In het vorige hoofdstuk heb je kennisgemaakt met hypothesetoetsen. In dit hoofdstuk gaan we een aantal specifieke toetsen behandelen voor situaties die in de praktijk vaak voorkomen. Dat zijn situaties waarbij de variabele \(X\) numeriek en continu is, en waarbij onze hypotheses gaan over parameter \(\mu_X\), het populatiegemiddelde van die variabele.
26.1 Leerdoelen
Na het bestuderen van dit hoofdstuk kun je
drie veelvoorkomende toetsen voor gemiddelden uitvoeren en interpreteren:
De \(t\)-toets voor één steekproef;
De \(t\)-toets voor twee onafhankelijke steekproeven;
De \(t\)-toets voor gepaarde steekproeven;
de aannames van deze toetsen uitleggen en controleren;
zelfstandig bepalen welke toets in een bepaalde situatie passend is;
uitleggen wat verdelingsvrije alternatieven zijn en wanneer je die kunt gebruiken;
uitleggen waarin de \(t\)-toets van Welch verschilt van de standaard \(t\)-toets voor twee steekproeven en wanneer je die moet gebruiken;
de relatie uitleggen en toepassen tussen hypothesetoetsen en betrouwbaarheidsintervallen.
26.2 Toets van het gemiddelde: \(t\)-toets voor één steekproef
Voorbeeld 26.1 (Is de lichaamstemperatuur van gezonde mensen wel 37\(\degree\)C?) Waarschijnlijk heb je lang geleden geleerd dat gezonde mensen een “normale” lichaamstemperatuur hebben van 37\(\degree\)C. Die wijsheid is het resultaat van klassiek onderzoek door Carl Reinhold August Wunderlich dat werd gepubliceerd in 1868. In die tijd waren de meetmethoden lang niet zo precies als nu. Het is dus niet gek om je af te vragen: klopt die waarde eigenlijk wel?
Om dat te achterhalen zouden we een steekproef kunnen nemen van een aantal gezonde personen. Als de gemiddelde temperatuur van die proefpersonen sterk afwijkt van 37\(\degree\)C, dan is dat een indicatie dat de standaardtemperatuur misschien herzien moet worden.1
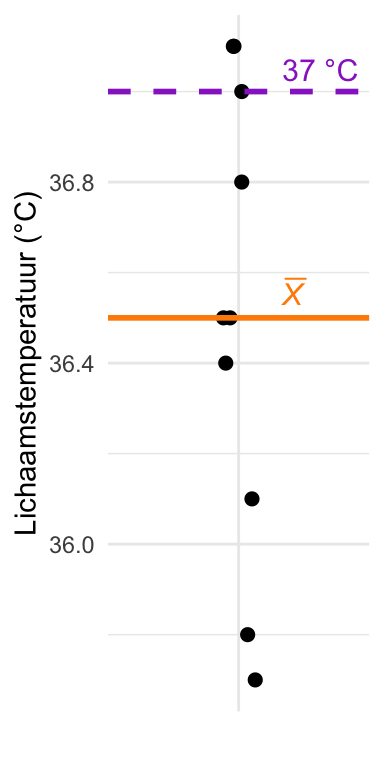
Stel dat we inderdaad een steekproef nemen van \(n = 10\) personen en de volgende resultaten vinden, in \(\degree\)C:
# Gegevens (vervang dit met je eigen getallen indien gewenst)gegevens <-c(35.7, 35.8, 37.0, 36.5, 37.1, 36.4, 36.1, 36.8, 36.5, 37.1)# Bereken het steekproefgemiddeldegemiddelde <-mean(gegevens)# Nulhypothese-gemiddeldenulhypothese <-37# Maak de jitterplotggplot(data.frame(waarde = gegevens), aes(x ="", y = waarde)) +geom_jitter(width =0.1, height =0, size =2, color ="black") +geom_hline(yintercept = gemiddelde, color = lijnkleur0, linetype ="solid", linewidth =1) +geom_hline(yintercept = nulhypothese, color = lijnkleur1,linetype ="dashed", linewidth =1) +annotate("text", x =1.2, y = gemiddelde, label =expression(bar(italic(X))),color = accentkleur1, hjust =0, vjust =-0.5, size =4) +annotate("text", x =1.2, y = nulhypothese, label ="37 °C",color = accentkleur2, hjust =0, vjust =-0.5, size =4) +labs(y ="Lichaamstemperatuur (°C)", x ="") +theme_minimal() +theme(axis.text.x =element_blank(),axis.ticks.x =element_blank())
Figuur 26.1: Jitterplot van de gegevens. De oranje lijn geeft het gemiddelde aan, de paarse lijn de standaardwaarde van 37°C.
Het gemiddelde van deze steekproef is \(\overline{X} = 36{,}5\degree\)C. Is dit dan sterk bewijs tegen de standaardtemperatuur van 37\(\degree\)C?
Mensen verschillen onderling in hun normale temperatuur, en ieders lichaamstemperatuur schommelt bovendien gedurende de dag (door je biologische klok) en van dag tot dag (bijvoorbeeld door de menstruatiecyclus). Een steekproefgemiddelde dat wat lager is dan 37\(\degree\)C kan dus ook het gevolg zijn van steekproevenvariabiliteit. We hebben daarom een hypothesetoets nodig om te bepalen in hoeverre de gevonden afwijking bewijs levert tegen een populatiegemiddelde van 37\(\degree\)C.
Hypotheses over het gemiddelde van een variabele
De casus hierboven over de normale lichaamstemperatuur is een voorbeeld van een veelvoorkomende situatie. We zijn geïnteresseerd in een continue variabele (in het voorbeeld: lichaamstemperatuur), en hebben een hypothese over het gemiddelde van die variabele in de populatie (in het voorbeeld: het populatiegemiddelde van de lichaamstemperatuur). Om die hypothese te onderzoeken nemen we een steekproef. Voor iedere eenheid in die steekproef bepalen we de waarde van de variabele. Dat levert een steekproefgemiddelde op dat typisch wat afwijkt van het populatiegemiddelde volgens onze hypothese. De vraag is hoe opmerkelijk die afwijking is. Kan die verklaard worden door steekproevenvariabiliteit, of is de afwijking daarvoor te groot?
De \(t\)-toets voor één steekproef is de standaardtoets die voor dit soort situaties ontwikkeld is.
De \(t\)-toets voor één steekproef in zes stappen
In Paragraaf 25.9 hebben we al gezien dat alle hypothesetoetsen dezelfde logische structuur hebben. Daar hebben we die structuur in zes stappen opgedeeld. We gaan die zes stappen nu doorlopen voor de \(t\)-toets voor één steekproef. Daarbij passen we de berekening direct toe op Voorbeeld 26.1 over de lichaamstemperatuur.
Stap 1: Kies een statistisch model.
De eerste stap van iedere toets bestaat uit het kiezen van een gepast statistisch model. De \(t\)-toets voor één steekproef gaat uit van het Normale Model (Paragraaf 24.4) dat we in Hoofdstuk 24 ook hebben gebruikt. We nemen dus aan:
De variabele is in de populatie normaal verdeeld, met gemiddelde \(\mu_X\) en standaarddeviatie \(\sigma_X\).
Iedere waarde \(X_i\) in onze steekproef is onafhankelijk uit die normale verdeling getrokken. Dat vereist dat we een eenvoudige aselecte steekproef hebben uitgevoerd.
Het is weer belangrijk dat we kritisch nagaan of die aannames redelijk zijn voor de toepassing. We hebben in Paragraaf 24.10 uitgebreid besproken hoe je dat kunt doen.
Stap 2: Stel de hypotheses \(H_\textrm{0}\) en \(H_\textrm{A}\) op.
Stap 2 is het opstellen van de nulhypothese en de alternatieve hypothese. In de casus was de nulhypothese dat het populatiegemiddelde van de variabele lichaamstemperatuur gelijk is aan 37\(\degree\)C. Die hypothese kan kort opgeschreven worden als:
\(H_\textrm{0}:\qquad\mu_X = 37\degree\)C.
De alternatieve hypothese is de ontkenning daarvan:
\(H_\textrm{A}:\qquad\mu_X \neq 37\degree\)C.
De waarde van \(\mu_X\) volgens de nulhypothese wordt in het algemeen vaak \(\mu_0\) genoemd.
In het algemeen kunnen we de hypotheses dus opschrijven als
Stap 3: Kies de toetsingsgrootheid en bepaal zijn kansverdeling onder \(H_\textrm{0}\).
We hebben een toetsingsgrootheid nodig die weergeeft hoe ver het steekproefgemiddelde \(\overline{X}\) afwijkt van de verwachting onder \(H_\textrm{0}\). De \(t\)-toets voor één steekproef gebruikt daarvoor: \[
t = \frac{\overline{X} - \mu_0}{\mathrm{SE}_{\overline{X}}}.
\tag{26.1}\] Dit is het verschil tussen het steekproefgemiddelde \(\overline{X}\) en het populatiegemiddelde volgens \(H_\textrm{0}\), relatief ten opzichte van de standaardfout.
Dat \(t\) een goede keuze is voor de toetsingsgrootheid, kun je als volgt inzien. We hebben in Hoofdstuk 24 gezien dat de standaardfout een maat is voor de onzekerheid in \(\overline{X}\) als gevolg van steekproevenvariabiliteit. De waarde van \(t\) is klein als het waargenomen verschil tussen \(\overline{X}\) en \(\mu_0\) niet veel groter is dan de standaardfout. (Controleer dat je dat begrijpt op basis van Vergelijking 26.1!) In dat geval is dat verschil goed te verklaren door toevallige steekproevenvariabiliteit. De waarde van \(t\) is juist groot als het waargenomen verschil tussen \(\overline{X}\) en \(\mu_0\) veel groter is dan de standaardfout. In dat geval is dat verschil erg opmerkelijk onder \(H_\textrm{0}\) en dus bewijs tegen \(H_\textrm{0}\). Extreme waarden van \(t\) zijn dus een indicatie dat er iets mis is met \(H_\textrm{0}\).
De volgende uitdaging is om de kansverdeling van \(t\) onder \(H_\textrm{0}\) te bepalen. Gelukkig hebben we in Paragraaf 24.8.2 al het lastige voorwerk al gedaan. Daar hebben we namelijk al besproken dat de verdeling van \(t\), zoals gedefinieerd in Vergelijking 26.1, onder het Normale Model een \(t\)-verdeling volgt met \(n - 1\) vrijheidsgraden!
Stap 4: Bereken de toetsingsgrootheid op basis van de daadwerkelijke waarnemingen.
We gaan \(t\) berekenen voor de lichaamstemperaturen. Uit de resultaten die in Voorbeeld 26.1 gegeven waren, kunnen we berekenen:
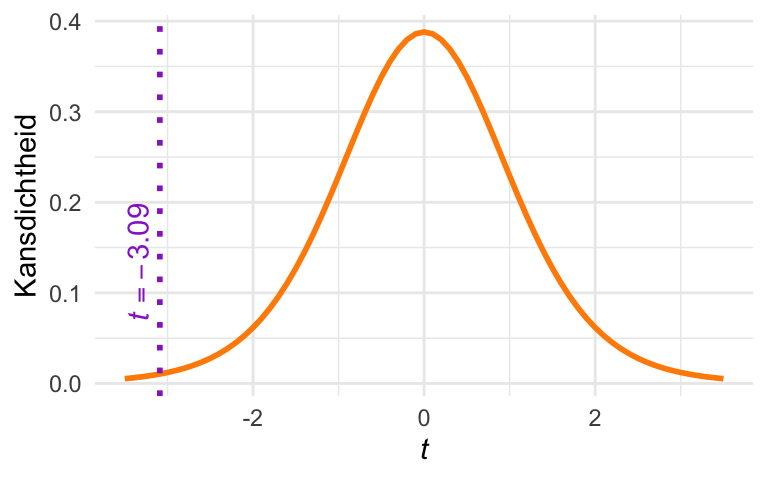
We kunnen ook de bijbehorende kansverdeling plotten. Dat is de \(t\)-verdeling met \(\mathrm{df}= n - 1 = 9\) vrijheidsgraden. Die ziet er zo uit:
Code
tCurve(9) +geom_vline(xintercept =-3.09, color = lijnkleur1,linewidth =1, linetype ="dotted") +annotate("text", x =-3.09, y =0.2,label =expression(italic(t) ==-3.09),color = accentkleur2, angle =90, vjust =-0.5, hjust =1)
Figuur 26.2: \(t\)-verdeling met 9 vrijheidsgraden
De \(t\)-waarde die we gevonden hebben, is met een paarse stippellijn aangegeven. Die waarde ligt aardig ver in de staart van de verdeling. Dat betekent dat deze waarde onder \(H_\textrm{0}\) vrij verrassend is. We kunnen zien aankomen dat de \(P\)-waarde klein gaat worden.
Stap 5: Bereken de \(P\)-waarde.
De volgende stap is om de \(P\)-waarde te berekenen.
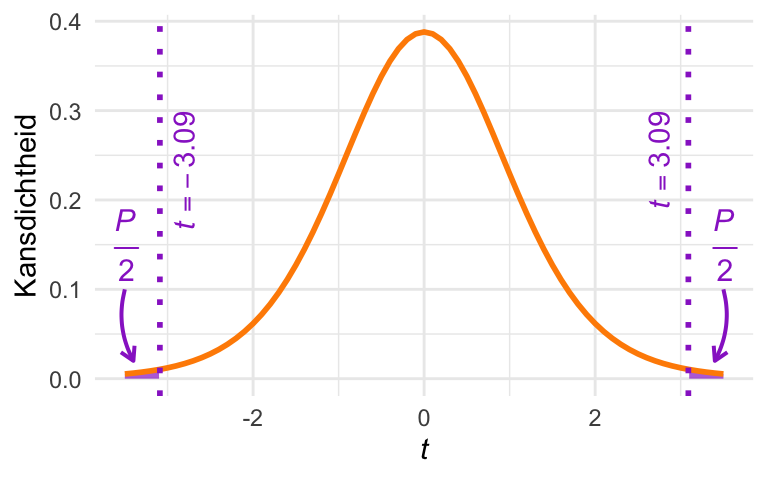
De \(P\)-waarde is de kans op een uitkomst die minstens zo extreem is als de waarde \(t = -3{,}09\) die we daadwerkelijk hebben gevonden. Dat komt overeen met de oppervlakte van de staarten van de verdeling die in Figuur 26.3 hieronder met paars zijn aangegeven. (Die oppervlakten zijn maar klein—ze zijn daardoor misschien lastig te zien!)
Code
# Data frame met x/y kolommen voor oppervlak()data <-data.frame(x =seq(-3.5, 3.5, length.out =350),y =dt(seq(-3.5, 3.5, length.out =350), df =9))y_pijl <-0.1y_end_pijl <-0.02tCurve(9) +oppervlak(-10, -3.09) +oppervlak( 3.09, 10) +annotate("curve",x =-3.5, y = y_pijl, xend =-3.4, yend = y_end_pijl,curvature =0.2, arrow =arrow(length =unit(0.2, "cm")),color = lijnkleur1, linewidth =0.7) +annotate("curve",x =3.5, y = y_pijl, xend =3.4, yend = y_end_pijl,curvature =-0.2, arrow =arrow(length =unit(0.2, "cm")),color = lijnkleur1, linewidth =0.7) +annotate("text", x =-3.5, y = y_pijl +0.05,label =expression(frac(italic(P), 2)),color = accentkleur2, hjust =0.5, size =4) +annotate("text", x =3.5, y = y_pijl +0.05,label =expression(frac(italic(P), 2)),color = accentkleur2, hjust =0.5, size =4) +geom_vline(xintercept =-3.09, color = lijnkleur1,linewidth =1, linetype ="dotted") +annotate("text", x =-2.55, y =0.3,label =expression(italic(t) ==-3.09),color = accentkleur2, angle =90, vjust =-0.5, hjust =1) +geom_vline(xintercept =3.09, color = lijnkleur1,linewidth =1, linetype ="dotted") +annotate("text", x =3, y =0.3,label =expression(italic(t) ==3.09),color = accentkleur2, angle =90, vjust =-0.5, hjust =1)
Figuur 26.3: \(t\)-verdeling met df = 9 vrijheidsgraden. De \(P\)-waarde is het totale oppervlak van de met paars aangegeven staarten van de verdeling.
Om deze oppervlakte te berekenen, kun je gebruik maken van de functie pt() in R. Deze functie geeft de cumulatieve verdeling van de \(t\)-verdeling. (In Oefening 23.11 heb je de functie pnorm() al gebruikt, die hetzelfde doet voor de normale verdeling.)
Bijvoorbeeld, pt(0, df = 9) geeft de kans op een waarde van \(t\) kleiner dan 0 volgens de \(t\)-verdeling met 9 vrijheidsgraden. (Het antwoord moet 0,5 zijn, omdat alle \(t\)-verdelingen symmetrisch zijn rond 0.)
De oppervlakte in de paarse linkerstaart van de verdeling kan dus worden berekend met deze code:
t <--3.087701n <-10pt(-abs(t), df = n -1)
[1] 0.006488777
De functie abs(t) haalt het minteken weg van \(t\) zodat de waarde positief wordt. Op deze manier werkt de code ongeacht of de \(t\)-waarde positief of negatief is.
Om ook de rechterstaart mee te rekenen, moeten we die kans verdubbelen. Dat levert op:
(P <-2*pt(-abs(t), df = n -1))
[1] 0.01297755
Dat is dus de \(P\)-waarde waarnaar we op zoek waren!
Stap 6: Trek je Conclusies
Nu we de \(P\)-waarde hebben, kunnen we onze conclusies trekken.
De \(P\)-waarde van 0,013 is behoorlijk klein. Omdat deze kleiner is dan 0,05 wordt deze “statistisch significant” genoemd. De \(P\)-waarde zegt: Als \(H_\textrm{0}\) waar is (en het ware populatiegemiddelde is dus \(37\degree\)C), dan komt zo’n extreme waarde (of nog extremer) voor bij iets meer dan 1 op de 100 steekproeven. Dat is een sterke indicatie dat de standaardwaarde van \(37\degree\)C aan de hoge kant is.
De stappen voor de \(t\)-toets voor één steekproef in het kort
We vatten de stappen van de \(t\)-toets nog even kort samen:
BelangrijkDe \(t\)-toets voor één steekproef in 6 stappen
We zijn geïnteresseerd in een continue variabele \(X\) en willen de hypothese toetsen dat het populatiegemiddelde van \(X\) gelijk is aan een bepaalde waarde \(\mu_0\). We nemen daarom een steekproef van \(n\) eenheden.
Verdeling van de toetsingsgrootheid onder \(H_\textrm{0}\):
De \(t\)-verdeling met \(\mathrm{df}= n - 1\).
Bereken de toetsingsgrootheid op basis van de steekproef.
Achtereenvolgens: \(\overline{X}\), \(s_X\), \(\mathrm{SE}_{\overline{X}}\), en dan \(t\).
Bereken de \(P\)-waarde:
Gebruik R:
P <-2*pt(-abs(t), df = n -1)
Trek je conclusies.
Oefening 26.1 (Kippen-eieren.)
Een kippenboerderij beweert dat de geleverde eieren gemiddeld 52 g wegen. Wij geloven dat niet zomaar en besluiten onderzoek te doen.
We wegen vier eieren, met de volgende gewichten: 51,7g; 50,3g; 48,4g; en 51,9g. Gebruik het stappenplan hierboven om de volledige \(t\)-toets uit te voeren.
De \(t\)-toets helemaal door R laten uitvoeren
Hierboven hebben we de hele \(t\)-toets handmatig uitgevoerd, en R enkel gebruikt om de \(P\)-waarde op te vragen. Het is efficiënter om de hele berekening door R te laten uitvoeren. Het script zou er zo uit kunnen zien:
Maar het kan nog veel gemakkelijker. De functie t.test() die we in Hoofdstuk 24 ook hadden gebruikt om het 95%-betrouwbaarheidsinterval uit te rekenen, voert de hele berekening in één keer uit:
One Sample t-test
data: temperaturen
t = -3.0877, df = 9, p-value = 0.01298
alternative hypothesis: true mean is not equal to 37
95 percent confidence interval:
36.13368 36.86632
sample estimates:
mean of x
36.5
Merk op dat we t.test() nu moeten vertellen wat onze nulhypothese is; dat gebeurt met het argument mu = mu0.
Het is belangrijk om even stil te staan bij de uitvoer van deze functie. We doen dat in de volgende opgave.
Oefening 26.2 (De uitvoer van de functie t.test() bij één steekproef.)
Neem de code hierboven, waarin de \(t\)-toets wordt uitgevoerd met de functie t.test(), over in een script en voer het uit.
Bestudeer de uitvoer:
Waar in de uitvoer vind je het steekproefgemiddelde?
Waar vind je de waarden van \(t\), df, en de \(P\)-waarde? Komen die overeen met onze handmatige berekeningen hierboven?
De functie geeft ook het 95%-BHI voor \(\mu_X\). Wat zijn de ondergrens en de bovengrens?
Relatie tussen toetsen en betrouwbaarheidsintervallen
In Hoofdstuk 24 hebben we het uitgebreid gehad over betrouwbaarheidsintervallen. Je hebt geleerd dat een 95%-BHI een interval is waarbinnen de ware parameter zich met 95% zekerheid bevindt. Dat wil zeggen: als \(H_\textrm{0}\) waar is, dan zou \(\mu_0\) in 95% van de keren dat we een steekproef trekken binnen het berekende 95%-BHI moeten liggen, en maar 5% van de keren daarbuiten.
Als we dus vinden dat \(\mu_0\) buiten het 95%-BHI ligt, dan kunnen we concluderen dat het waargenomen verschil tussen \(\overline{X}\) en \(\mu_0\) zo extreem is dat het onder \(H_\textrm{0}\) in minder dan 5% van de gevallen plaatsvindt. Dat betekent dat de \(P\)-waarde kleiner moet zijn dan 0,05.
Er is dus een nauw verband tussen het 95%-BHI en de \(P\)-waarde:
BelangrijkVerband tussen 95%-BHI en \(P\)-waarde
Neem een steekproef en bereken het 95%-BHI voor \(\mu_X\).
Als \(\mu_0\)buiten het 95%-BHI valt, dan moet \(P\) kleiner zijn dan 0,05 en is de afwijking dus sowieso “statistisch significant”.
Als \(\mu_0\)binnen het 95%-BHI valt, dan moet \(P\) groter zijn dan 0,05 en is de afwijking dus sowieso niet “statistisch significant”.
Je kunt het 95%-BHI dus ook interpreteren als de verzameling van alle mogelijke waarden van \(\mu_0\) waar volgens de \(t\)-toets geen “statistisch significant” bewijs tegen is.
Ondanks dit verband vullen het 95%-BHI en de \(P\)-waarde elkaar aan.
Het 95%-BHI kan je vertellen of de \(P\)-waarde voor een bepaalde nulhypothese kleiner is dan 0,05, maar niet hoe klein dan precies. Je kunt er de mate van bewijs tegen \(H_\textrm{0}\) dus niet precies mee bepalen.
De \(P\)-waarde kan je de mate van bewijs tegen \(H_\textrm{0}\) vertellen, maar niet hoe ver de ware \(\mu_X\) van \(\mu_0\) verwijderd is. Vaak is dat minstens zo belangrijk.
26.3 De \(t\)-toets voor twee onafhankelijke steekproeven
De \(t\)-toets voor één steekproef was bedoeld om te toetsen of het populatiegemiddelde van een variabele \(X\) afwijkt van een specifieke waarde \(\mu_0\). We gaan het nu hebben over een andere situatie, waarin we willen onderzoeken of de populatiegemiddelden van twee populaties van elkaar verschillen. Bijvoorbeeld, we zouden ons kunnen afvragen of bacteriën mét een bepaalde mutatie (populatie 1) gemiddeld resistenter zijn voor antibiotica dan bacteriën zonder die mutatie (populatie 2). Een ander voorbeeld: verschilt de gemiddelde hoeveelheid fijnstof aangetroffen in woningen in IJmond en Amsterdam?
Om de twee populaties te vergelijken, nemen we een steekproef uit populatie 1 en een steekproef uit populatie 2. Dat levert twee steekproefgemiddelden op, die waarschijnlijk van elkaar zullen verschillen. De vraag is vervolgens of we daaruit kunnen concluderen dat de populatiegemiddelden van beide populaties van elkaar verschillen, of dat de verschillen in het steekproefgemiddelde ook verklaard kunnen worden door toevallige steekproevenvariabiliteit.
Dat is de taak van de \(t\)-toets voor twee onafhankelijke steekproeven.
We gaan deze toets weer uitleggen door de zes stappen één voor één door te lopen. Daarna passen we het toe op een voorbeeld.
Stap 1: Kies een statistisch model.
Bij de \(t\)-toets voor één steekproef gingen we uit van het Normale Model. Dat doen we nu weer, maar met twee kleine twists:
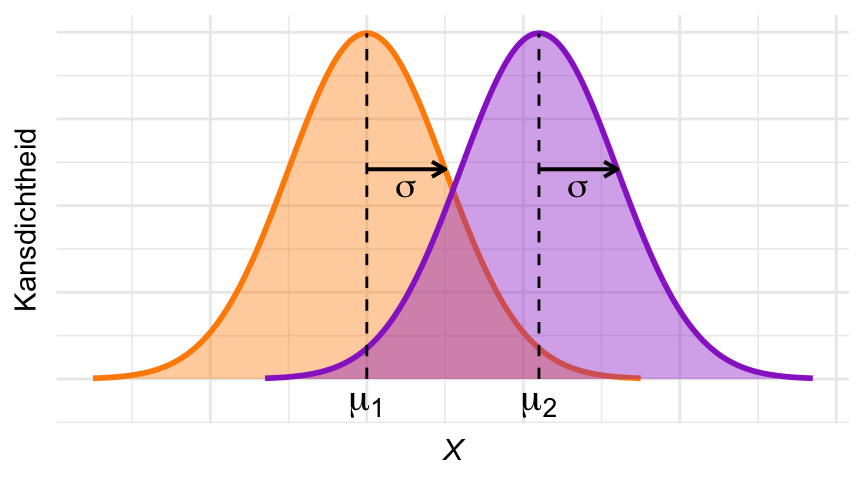
Omdat we nu te maken hebben met twee populaties en twee steekproeven in plaats van één, moeten we aannames maken over beide steekproeven. We nemen daarom aan dat het Normale Model van toepassing is op beide steekproeven. Dat wil zeggen dat de variabele \(X\) normaal verdeeld is in beide populaties, met gemiddelden \(\mu_1\) en \(\mu_2\), en dat de waarnemingen in beide steekproeven onafhankelijk uit die normale verdeling getrokken zijn.
We nemen bovendien aan dat de standaarddeviaties van beide populaties gelijk zijn; we zullen die standaarddeviatie \(\sigma\) noemen.
Deze aanname is vaak redelijk en maakt de berekeningen gemakkelijker. Maar, er bestaat ook een versie van de toets die deze aanname niet maakt, en die kan in veel gevallen dus geschikter zijn; daar komen we in Paragraaf 26.3.7 op terug.
Het statistisch model kan dus in het volgende plaatje worden samengevat:
Figuur 26.4: Illustratie van het statistisch model van de \(t\)-toets voor 2 steekproeven. Aangenomen wordt dat de variabele in beide populaties normaal verdeeld is, met dezelfde standaarddeviatie \(\sigma\).
Stap 2: Formuleer de hypotheses.
De sceptische hypothese is in dit geval dat de populatiegemiddelden van beide populaties gelijk zijn. Dat wil zeggen:
Stap 3: Kies de toetsingsgrootheid en bepaal zijn verdeling onder \(H_\textrm{0}\).
Bij de \(t\)-toets voor één steekproef gebruikten we als toetsingsgrootheid de afwijking van \(\overline{X}\) van \(\mu_0\), relatief ten opzichte van de standaardfout van het gemiddelde, \(\mathrm{SE}_{\overline{X}}\). Het intuïtieve idee daarachter was dat we de afwijking van \(\overline{X} - \mu_0\) moesten vergelijken met de onzekerheid in \(\overline{X}\) als gevolg van steekproevenvariabiliteit.
Bij de \(t\)-toets voor twee steekproeven volgen we dezelfde logica. De toetsingsgrootheid die we gaan gebruiken moet weer aangeven hoe het verschil dat is aangetroffen tussen de twee steekproefgemiddelden, \(\overline{X}_1 - \overline{X}_2\), zich verhoudt tot de onzekerheid in dat verschil als gevolg van steekproevenvariabiliteit. Daarom is de toetsingsgrootheid \[ t = \frac{\overline{X}_1 - \overline{X}_2}{\mathrm{SE}_{\overline{X}_1 - \overline{X}_2}}, \tag{26.2}\] waarin \(\mathrm{SE}_{\overline{X}_1 - \overline{X}_2}\) de standaardfout is van het verschil in de steekproefgemiddelden, \(\overline{X}_1 - \overline{X}_2\).
Om te begrijpen wat die standaardfout voorstelt, stellen we ons voor dat we heel vaak steekproeven nemen uit beide populaties en steeds \(\overline{X}_1 - \overline{X}_2\) uitrekenen. Dat levert de steekproevenverdeling van \(\overline{X}_1 - \overline{X}_2\) op. De standaardfout \(\mathrm{SE}_{\overline{X}_1 - \overline{X}_2}\) is een schatter van de standaarddeviatie van die verdeling.
Je kunt de waarde van \(\mathrm{SE}_{\overline{X}_1 - \overline{X}_2}\) zelf berekenen, maar de formule is niet zo elegant. In de praktijk zul je de berekening dus aan R over laten. We laten de formules toch even zien:
Eerst bereken je de standaarddeviaties \(s_1\) en \(s_2\) van beide steekproeven.
Daarmee bereken je de gepoolde steekproefvariantie\(s_\textrm{p}^2\) met de volgende formule:
In deze formule zijn \(n_1\) en \(n_2\) de steekproefgroottes van beide steekproeven. Merk op dat \(s_\textrm{p}^2\) eigenlijk gewoon een gewogen gemiddelde is van de steekproefvarianties van beide steekproeven, waarbij een grotere steekproef een groter gewicht krijgt.
Tot slot kun je de volgende formule invullen: \[ \mathrm{SE}_{\overline{X}_1 - \overline{X}_2} = \sqrt{s_\textrm{p}^2 \left( \frac{1}{n_1} + \frac{1}{n_2}\right)}. \tag{26.4}\]
Nu we weten wat de toetsingsgrootheid is, is de volgende stap om te bepalen wat de verdeling van de toetsingsgrootheid is onder \(H_\textrm{0}\). Wiskundig kan worden aangetoond dat de \(t\) van Vergelijking 26.2 onder \(H_\textrm{0}\) een \(t\)-verdeling volgt met \(\mathrm{df}= n_1 + n_2 - 2\) vrijheidsgraden.
Stap 4: Bereken \(t\) op basis van de twee steekproeven.
Je vult in deze stap dus Vergelijking 26.2 in.
Stap 5: Bereken de \(P\)-waarde:
Nu kunnen we de \(P\)-waarde berekenen met R. Dat gaat weer precies zoals bij de \(t\)-toets voor één steekproef, behalve dat we nu een ander aantal vrijheidsgraden moeten specificeren, namelijk \(\mathrm{df}= n_1 + n_2 - 2\):
# Zorg dat t, n1, en n2 al gedefinieerd zijn.# Bereken en print de P-waarde(P <-2*pt(-abs(t), df = n1 + n2 -2))
Stap 6: Trek je conclusies.
Trek op basis van \(P\) je conclusies!
De stappen voor de \(t\)-toets voor twee onafhankelijke steekproeven in het kort
We vatten de stappen weer even samen:
BelangrijkDe \(t\)-toets voor twee onafhankelijke steekproeven in 6 stappen
We zijn geïnteresseerd in een continue variabele \(X\). We willen de hypothese toetsen dat de populatiegemiddelden \(\mu_1\) en \(\mu_2\) van twee populaties gelijk zijn.
We nemen daarom uit beide populaties een steekproef, van \(n_1\) en \(n_2\) eenheden.
Dan zijn dit de stappen van de toets:
Kies het statistische model:
Beide populaties en steekproeven voldoen aan het Normale Model.
De standaarddeviaties van beide populaties zijn gelijk.
Verdeling van de toetsingsgrootheid onder \(H_\textrm{0}\):
De \(t\)-verdeling met \(\mathrm{df}= n_1 + n_2 - 2\).
Bereken de toetsingsgrootheid op basis van de steekproeven.
Achtereenvolgens: \(\overline{X}_1\),\(\overline{X}_2\), \(s_1\), \(s_2\), \(s_\textrm{p}^2\), \(\mathrm{SE}_{\overline{X}_1 - \overline{X}_2}\), en dan \(t\).
Bereken de \(P\)-waarde:
Gebruik R:
P <-2*pt(-abs(t), df = n1 + n2 -2)
Trek je conclusies.
De \(t\)-toets voor twee steekproeven met R uitvoeren
De \(t\)-toets voor twee steekproeven is één van de meest eenvoudige toetsen die er bestaan. Maar als je ’m met de hand moet uitrekenen, ben je toch een tijd bezig, en de kans op fouten is erg groot. Het is dus veel handiger om gebruik te maken van R.
Het is niet moeilijk om de formules zelf in R in te programmeren, maar dat is niet nodig. Ook deze \(t\)-toets kan namelijk met de functie t.test() worden uitgevoerd!
Laten we aannemen dat je de resultaten van je twee steekproeven in R hebt ingevoerd als twee vectoren, steekproef1 en steekproef2. Dan ben je daarna in één regel klaar:
t.test(steekproef1, steekproef2, var.equal =TRUE)
Het argument var.equal = TRUE is nodig om de functie te vertellen dat we hebben aangenomen dat beide populaties een gelijke variantie hebben.
Voorbeeld 26.2 (Verschillen de snavellengtes tussen pinguins van de soorten Chinstrap en Gentoo?)
Figuur en data: Horst et al (2020)
Op drie eilanden in the Palmerarchipel (Antarctica) zijn metingen verricht aan pinguïns van drie verschillende soorten.2 We vragen ons af: verschillen de soorten in de gemiddelde lengte van hun snavel?
Hieronder zullen we met een analyse in R twee soorten vergelijken: Chinstrap en Gentoo.
De data
We lezen eerst de gegevens in; die zijn beschikbaar gesteld via de library "palmerpenguins".
De variabele heet bill_length_mm. Uit de naam van de variabele valt op te maken dat de snavellengte gegeven is in mm. We selecteren de snavellengtes van de twee soorten en verwijderen NAs:
Voordat we een toets uitvoeren, moeten we de gegevens altijd eerst goed bekijken. Hoeveel datapunten zijn er?
(n1 <-length(snavel_Chinstrap))
[1] 68
(n2 <-length(snavel_Gentoo))
[1] 123
Dit is dus een flinke dataset, met snavelmetingen voor 68 Chinstrap-pinguïns en 123 Gentoo-pinguïns.
We bekijken wat kengetallen voor beide soorten. Eerst de ligging:
summary(snavel_Chinstrap)
Min. 1st Qu. Median Mean 3rd Qu. Max.
40.90 46.35 49.55 48.83 51.08 58.00
summary(snavel_Gentoo)
Min. 1st Qu. Median Mean 3rd Qu. Max.
40.90 45.30 47.30 47.50 49.55 59.60
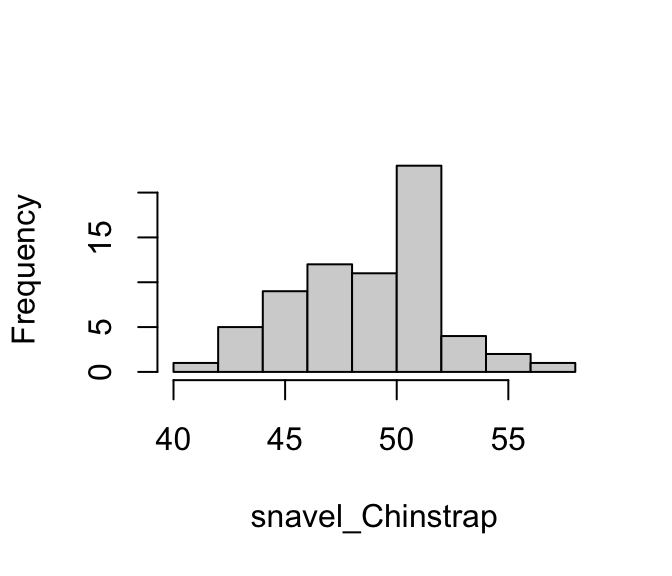
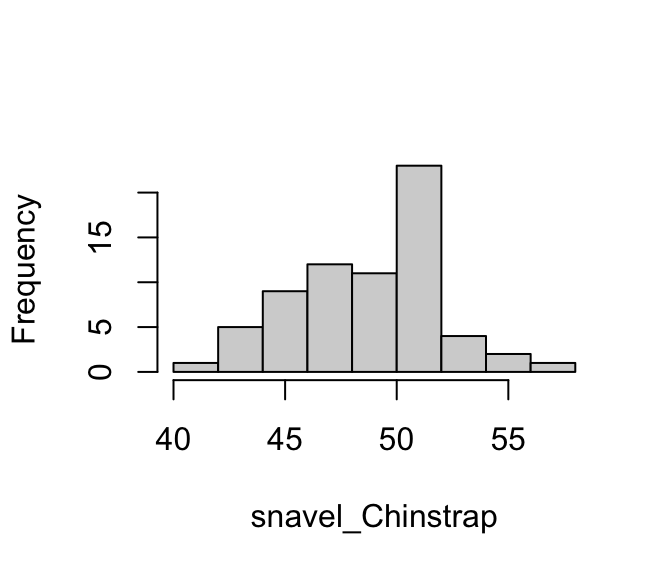
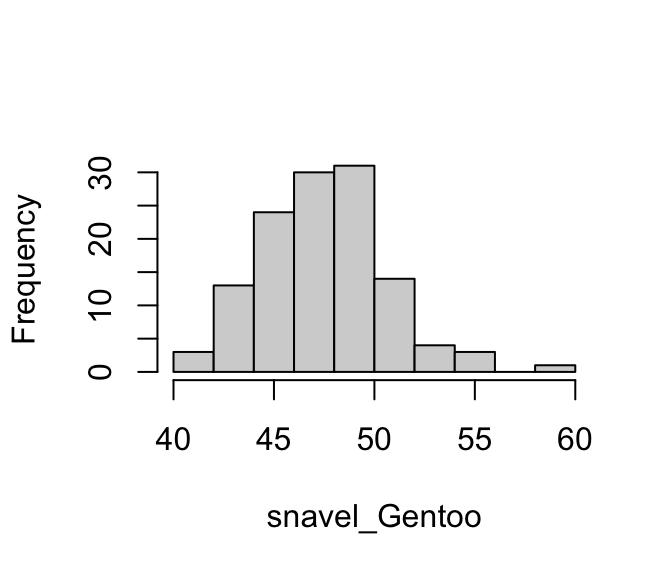
De mediaan en het gemiddelde van de Gentoos zijn net iets kleiner dan die van de Chinstraps.
Dan de spreiding:
sd(snavel_Chinstrap)
[1] 3.339256
sd(snavel_Gentoo)
[1] 3.081857
IQR(snavel_Chinstrap) #interkwartielafstand
[1] 4.725
IQR(snavel_Gentoo)
[1] 4.25
De spreiding is voor beide soorten vergelijkbaar, maar iets kleiner voor de Gentoos.
We genereren ook voor beide soorten een histogram:
hist(snavel_Chinstrap, main =NULL)hist(snavel_Gentoo, main =NULL)
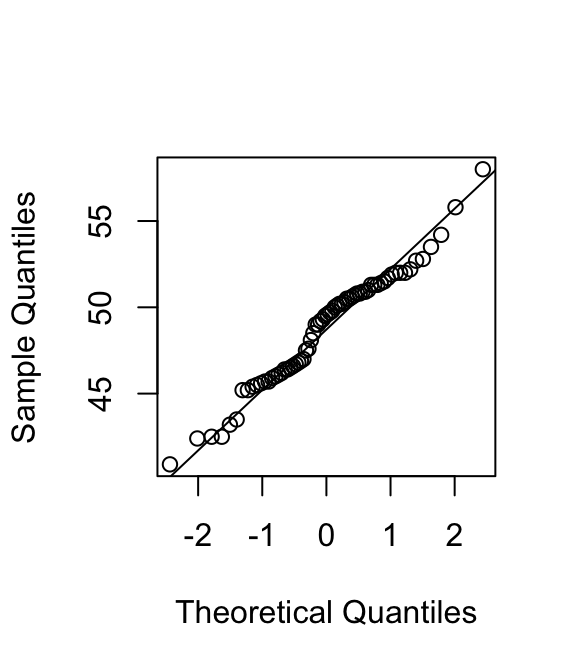
De verdelingen lijken lichtelijk rechts-scheef. Dat is jammer, want het Normale Model neemt aan dat de variabele in beide populaties normaal verdeeld is. We onderzoeken dit verder met twee QQ-plots:
qqnorm(snavel_Chinstrap, main =NULL)qqline(snavel_Chinstrap)qqnorm(snavel_Gentoo, main =NULL)qqline(snavel_Gentoo)
Er zijn zeker wat milde afwijkingen te zien. Maar, in Hoofdstuk 24 hebben we gezien dat bij grote steekproeven afwijkingen van het Normale Model minder belangrijk zijn. In dit geval zijn beide steekproeven groot en zouden deze milde afwijkingen geen probleem moeten zijn.
Two Sample t-test
data: snavel_Chinstrap and snavel_Gentoo
t = 2.7694, df = 189, p-value = 0.006176
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.3823625 2.2755285
sample estimates:
mean of x mean of y
48.83382 47.50488
Conclusies
De \(P\)-waarde is 0,006. Dat is behoorlijk klein en dus sterk bewijs tegen \(H_\textrm{0}\). Het (kleine) verschil in de gemiddelde snavellengte is dus moeilijk te verklaren door steekproevenvariatie. Gentoo-pinguïns hebben dus waarschijnlijk daadwerkelijk gemiddeld een iets kortere snavel.
Oefening 26.3 (De uitvoer van de functie t.test() bij twee onafhankelijke steekproeven.)
In Voorbeeld 26.2 wordt uiteindelijk een \(t\)-toets voor twee steekproeven uitgevoerd met de functie t.test(). Bekijk de uitvoer goed.
Hoeveel vrijheidsgraden heeft R gebruikt? Klopt dat?
Er wordt in de uitvoer een 95%-BHI gegeven. Hoe moet je dat interval interpreteren?
Ligt het getal 0 binnen het 95%-BHI? Wat zegt dat over de \(P\)-waarde?
De \(t\)-toets van Welch voor twee onafhankelijke steekproeven
De standaard \(t\)-toets voor twee steekproeven maakt de aanname dat de variantie van de variabele in beide populaties gelijk is. In veel praktische situaties is dat niet het geval. Wat dan?
De \(t\)-toets is op zich niet heel gevoelig voor kleine afwijkingen tussen beide standaarddeviaties, vooral als de steekproeven groot zijn. Als beide steekproeven groter zijn dan 30, is een verschil in standaarddeviatie van een factor 2 vaak nog geen groot probleem.
Maar, bij twijfel is het beter om gebruik te maken van een versie van de \(t\)-toets die de \(t\)-toets van Welch wordt genoemd. Deze toets maakt de aanname dat beide standaarddeviaties gelijk zijn niet.
In deze cursus bespreken we de precieze formules voor de \(t\)-toets van Welch niet. Maar het is binnen R heel gemakkelijk om de toets uit te voeren. Voor de standaard \(t\)-toets moesten we aan de t.test() functie het argument var.equal = TRUE meegeven. Als we in plaats daarvan var.equal = FALSE invoeren, wordt de toets van Welch uitgevoerd:
Welch Two Sample t-test
data: snavel_Chinstrap and snavel_Gentoo
t = 2.706, df = 129.22, p-value = 0.00773
alternative hypothesis: true difference in means is not equal to 0
95 percent confidence interval:
0.3572698 2.3006212
sample estimates:
mean of x mean of y
48.83382 47.50488
Sterker nog, de setting FALSE is in R de default; als je niets specificeert wordt dus standaard de toets van Welch uitgevoerd:
t.test(snavel_Chinstrap, snavel_Gentoo)
Het enige nadeel van de toets van Welch is dat die iets minder krachtig is dan de standaard \(t\)-toets voor twee steekproeven. De \(P\)-waarde zal typisch dus iets groter zijn bij de toets van Welch dan bij de standaard toets. Maar als de steekproeven groter zijn, is het verschil te verwaarlozen.
Oefening 26.4 (Verschil in interpretatie tussen de toets van Welch en de standaardtoets.)
In de tekst hierboven zijn zowel de toets van Welch als de standaard \(t\)-toets toegepast op de pinguïndata. Vergelijk de uitvoer van beide toetsen.
Vergelijk de \(P\)-waardes. Verschillen die betekenisvol van elkaar?
Vergelijk de 95%-betrouwbaarheidsintervallen. Welke interval is breder? Hoe komt dat?
26.4 De \(t\)-toets voor gepaarde steekproeven
Om het derde en laatste type \(t\)-toets te illustreren, beginnen we weer met een voorbeeld.
Voorbeeld 26.3 (De effecten van slaaptekort)
Figuur 26.5: De gevolgen van weinig slapen zijn niet mals.
Slaaptekort heeft grote effecten op de lichamelijke en geestelijke gezondheid. In een experiment uit 2003 werden de acute effecten onderzocht3.
Gedurende één week mochten acht proefpersonen slechts 4 uur per nacht in bed doorbrengen. Vervolgens werd elke dag gemeten hoe slaperig de proefpersonen waren door middel van de Maintainance of Wakefulness test (MWT). Die werkt als volgt: de deelnemer zit gedurende 20 minuten in bed, in een donkere kamer zonder verdere afleiding. De deelnemer mag geen gerichte acties ondernemen om te voorkomen dat deze in slaap valt, zoals zichzelf in het gezicht slaan of zingen. Gemeten wordt hoeveel minuten de deelnemer wakker blijft. De test wordt vijf keer herhaald, en de uiteindelijke score is het gemiddelde van die vijf testen.
Om het effect van het slaaptekort te bestuderen, vergelijken we de MWT scores van dag 0 (vlak voor de slaaprestrictie) met die van dag 6.
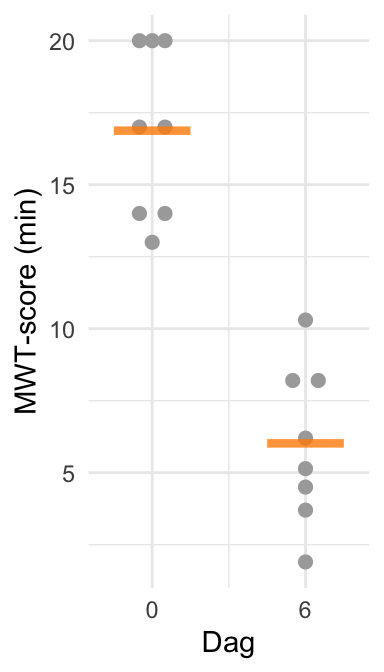
Hieronder laten we de scores op beide dagen zien in jitterplots. De gemiddelden van de beide dagen zijn met oranje lijntjes aangegeven.
Figuur 26.6: MWT-scores van de acht proefpersonen op dag 0 en dag 6 van de slaaprestrictie. Gemiddelde scores per dag zijn aangegeven met de oranje lijnen.
Zoals je in Figuur 26.6 kunt zien, waren er op dag 0 drie deelnemers die gedurende de hele test wakker bleven. Op dag 6 lukte dat geen van de deelnemers. De gemiddelde MWT-scores op die twee dagen verschillen dus van elkaar. Maar hoe toetsen we of dit verschil verklaard kan worden door toevallige steekproevenvariabiliteit?
De casus uit Voorbeeld 26.3 verschilt op een essentiële manier van die van Voorbeeld 26.2. De metingen op dag 0 en op dag 6 zijn namelijk verricht op dezelfde acht proefpersonen. In andere woorden: de twee steekproeven zijn gepaard: bij elke waarde in steekproef 1 hoort een waarde in steekproef 2. Een gevolg is dat de twee steekproeven niet onafhankelijk zijn van elkaar. Een proefperson die in het algemeen vrij gemakkelijk in slaap valt, zal mogelijk zowel op dag 0 als op dag 6 een lage MWT-score behalen. En een proefpersoon die in het algemeen moeilijk in slaap valt zal op beide dagen een relatief hoge score halen. De scores op dag 0 hangen dus samen met de scores op dag 6.
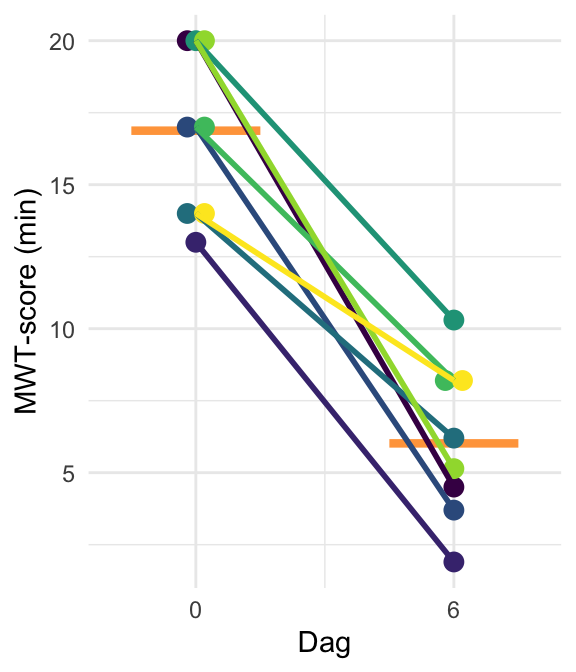
We kunnen dit laten zien door de metingen op dag 0 en dag 6 die bij dezelfde persoon horen dezelfde kleur te geven en met een lijntje te verbinden. Dat geeft deze figuur:
Figuur 26.7: Dezelfde figuur als hierboven, maar nu hebben de metingen op beide dagen die bij dezelfde persoon dezelfde kleur; ze zijn bovendien met een lijn verbonden.
Deze figuur suggereert inderdaad dat er een slaperig persoon in de groep was: die viel op beide dagen het snelst in slaap (de onderste, donkerpaarse lijn). Er was ook een wakker type bij, die op beide dagen tot de topscores behoorde (de bovenste, donkergroene lijn).
Dat de waarnemingen in beide steekproeven niet onafhankelijk zijn, heeft een belangrijke consequentie: het statistische model van de \(t\)-toets voor twee onafhankelijke steekproeven nam aan dat alle waarnemingen onafhankelijk waren; dat is hier niet juist, en dus kan die toets hier niet worden gebruikt.
Zelfs als we de \(t\)-toets voor onafhankelijke steekproeven hadden mogen gebruiken, is die toets niet ideaal. De onderlinge verschillen in de slaperigheid van de deelnemers dragen namelijk bij aan de spreiding binnen iedere steekproef. Hoe groter die spreiding is, hoe lastiger het is om aan te tonen dat er een verschil is in de gemiddelden van beide steekproeven. Om precies te zijn: de onderlinge verschillen tussen de deelnemers zorgen voor grotere standaarddeviaties \(s_1\) en \(s_2\), daardoor een grotere gepoolde steekproefvariantie \(s_\textrm{p}^2\) (zie Vergelijking 26.3) en dus een grotere standaardfout \(\mathrm{SE}_{\overline{X}_1 - \overline{X}_2}\) (zie Vergelijking 26.4), en dat levert dan weer een kleinere waarde van \(t\) op (Vergelijking 26.2). Dat verkleint de kans op een significant resultaat!
In dit onderzoek zijn we bovendien helemaal niet geïnteresseerd in de onderlinge verschillen. We willen vooral aantonen dat de individuele proefpersonen typisch slaperiger zijn op dag zes dan op dag 0, ongeacht hoe slaperig ze van zichzelf zijn.
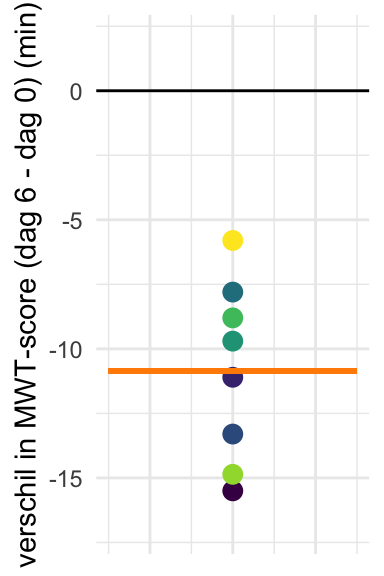
De oplossing is om voor iedere persoon het verschil uit te rekenen tussen de MWT-score op dag 6 en op dag 0, en enkel die verschillen te analyseren. Door alleen op de verschillen de focussen, filteren we de onderlinge verschillen in “baseline” slaperigheid weg.
We plotten die verschillen hieronder, in Figuur 26.8; de oranje lijn geeft het gemiddelde verschil aan. Deze figuur laat duidelijk zien dat alle proefpersonen na zes nachten slaperiger zijn geworden.
Figuur 26.8: Het verschil tussen MWT-scores dag 6 en dag 0. De oranje lijn geeft het gemiddelde aan van de verschillen.
De vraag wordt nu: kunnen we op basis van deze steekproef van acht proefpersonen concluderen dat het populatiegemiddelde van de verschillen in de MWT-scores afwijkt van 0?
Merk op dat er in Figuur 26.8 maar één steekproef te zien is, namelijk een steekproef van verschillen. De nulhypothese die we zouden willen toetsen is dat het populatiegemiddelde van de verschillen gelijk is aan 0. Deze situatie zou je bekend moeten voorkomen: dit is namelijk precies de situatie waarvoor de \(t\)-toets voor één steekproef was bedacht!
De toets die we willen gaan uitvoeren is daarom precies de \(t\)-toets voor één steekproef, maar dan toegepast op de verschillen binnen de gepaarde gegevens.
BelangrijkDe \(t\)-toets voor gepaarde steekproeven is gewoon de \(t\)-toets voor één steekproef
De \(t\)-toets voor gepaarde steekproeven is exact de \(t\)-toets voor één steekproef, maar dan toegepast op de verschillen die gevonden zijn binnen de gepaarde gegevens.
Aan de slag:
Stap 1: Kies een statistisch model.
We zijn geïnteresseerd in de variabele \(D\), het verschil tussen de MWT-score op dag 6 en dag 0.
We nemen aan dat de waargenomen verschillen voldoen aan het Normale Model. Dat wil zeggen: ieder verschil is onafhankelijk getrokken uit een normale verdeling, met (onbekend) gemiddelde \(\mu_D\).
Let op! We hoeven niet aan te nemen dat steekproef 1 of steekproef 2 uit een normale verdeling zijn getrokken; de aannames gaan enkel over de verschillen.
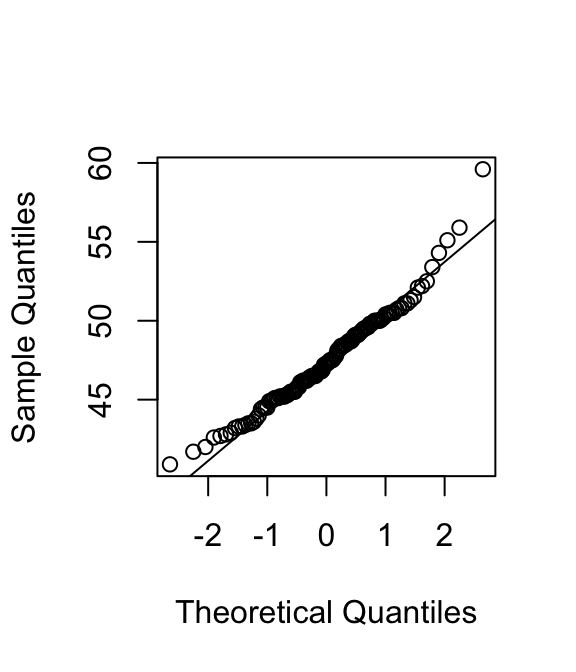
Om te controleren of de gegevens aanleiding geven tot twijfel aan de normale verdeling, maken we een QQ-plot van de verschillen:
Er zijn geen bijzonderheden te zien.
Stap 2: Formuleer de hypotheses.
De nulhypothese is dat het slaaptekort gemiddeld geen effect heeft. Dus:
Stap 3: Kies de toetsingsgrootheid en bepaal zijn verdeling onder \(H_\textrm{0}\).
We volgen de \(t\)-toets voor één steekproef; de toetsingsgrootheid is dus \[t = \cfrac{\overline{D}}{\mathrm{SE}_{\overline{D}}}.\]
Deze \(t\) is onder \(H_\textrm{0}\) verdeeld volgens de \(t\)-verdeling met \(\mathrm{df}= n - 1 = 8 - 1 = 7\) vrijheidsgraden.
Stap 4: Bereken \(t\) op basis van de twee steekproeven.
Het gemiddelde verschil \(\overline{D}\) is gelijk aan \(-10{,}86\textrm{\,min}\), de standaarddeviatie van de steekproef \(s_D = 3{,}47\textrm{\,min}\), en de standaardfout is \(\mathrm{SE}_{\overline{D}} = 1{,}23\textrm{\,min}\). Dus,
\[t = \frac{-10{,}86}{1{,}23} = -8.86.\]
Stap 5: Bereken de \(P\)-waarde:
Gebruik R (precies zoals bij de \(t\)-toets voor één steekproef):
n <-8(P <-2*pt(-abs(t), df = n -1))
[1] 4.723134e-05
Stap 6: Trek je conclusies.
De \(P\)-waarde is 0,000047. Dat is een heel kleine \(P\)-waarde. De gegevens vormen dus erg sterk bewijs tegen de nulhypothese. Dat geeft aan dat de deelnemers daadwerkelijk gemiddeld na 6 dagen slaaprestrictie een lagere MWT-score hebben.
De stappen voor de \(t\)-toets voor gepaarde steekproeven in het kort
We vatten de toets weer in het algemeen samen:
BelangrijkDe \(t\)-toets voor twee gepaarde steekproeven in 6 stappen
We zijn geïnteresseerd in een continue variabele \(X\). Er zijn twee steekproeven genomen van grootte \(n\), maar iedere waarneming in steekproef 1 is gepaard aan een waarneming in steekproef 2. We willen de hypothese toetsen dat het populatiegemiddelde van het verschil \(D\) binnen de paren gelijk is aan 0.
Dan zijn dit de stappen van de toets:
Kies het statistische model:
We nemen aan dat de verschillen \(D\) binnen de paren voldoen aan het Normale Model. De verschillen zijn dus onafhankelijk getrokken uit een normale verdeling met (onbekend) gemiddelde \(\mu_D\).
Verdeling van de toetsingsgrootheid onder \(H_\textrm{0}\):
De \(t\)-verdeling met \(\mathrm{df}= n - 1\).
Bereken de toetsingsgrootheid op basis van de steekproef.
Achtereenvolgens: alle verschillen \(D_i\), \(\overline{D}\), \(s_D\), \(\mathrm{SE}_{\overline{D}}\), en dan \(t\).
Bereken de \(P\)-waarde:
Gebruik R:
P <-2*pt(-abs(t), df = n -1)
Trek je conclusies.
De \(t\)-toets voor gepaarde steekproeven in R uitvoeren
De gemakkelijkste manier om de \(t\)-toets uit te voeren is door in R gebruik te maken van de functie t.test(), maar nu met het argument paired = TRUE. Toegepast op het voorbeeld levert dat de volgende code op:
Paired t-test
data: dag0 and dag6
t = 8.86, df = 7, p-value = 4.723e-05
alternative hypothesis: true mean difference is not equal to 0
95 percent confidence interval:
7.959764 13.755236
sample estimates:
mean difference
10.8575
Dat levert precies de resultaten op die we hierboven ook met de hand hadden berekend.
26.5 De drie \(t\)-toetsen en het Normale Model
De drie \(t\)-toetsen maken allemaal de aanname dat het Normale Model van toepassing is. Maar iedere \(t\)-toets past het Normale Model net iets anders toe. Het is belangrijk om die subtiele verschillen goed te begrijpen, omdat je anders niet kunt beoordelen of de gegevens afwijkingen laten zien van het model.
Het statistisch model van de \(t\)-toets voor één steekproef veronderstelt dat het Normale Model van toepassing is op de verdeling van de variabele in de populatie en de manier waarop de steekproef tot stand is gekomen.
Het statistisch model van de \(t\)-toets voor twee onafhankelijke steekproeven veronderstelt dat het Normale Model van toepassing is op beide populaties en steekproeven.
Het statistisch model van de \(t\)-toets voor gepaarde steekproeven veronderstelt dat het Normale Model van toepassing is op de verschillen binnen de gepaarde gegevens.
26.6 Wat is er nog meer?
We hebben in dit hoofdstuk drie \(t\)-toetsen behandeld die allemaal te maken hebben met het gemiddelde van een continue variabele. In deze cursus moeten we het daarbij laten.
Maar, er bestaan nog veel meer toetsen die gebruikt kunnen worden om de ligging van een verdeling te toetsen. We kunnen die onmogelijk allemaal bespreken, maar willen wel dat je nog een paar namen gezien hebt.
Niet-parametrische alternatieven
In sommige situaties zijn we niet bereid om aan te nemen dat het Normale Model van toepassing is. Dat kan zijn omdat de normale verdeling bij voorbaat niet plausibel is, of omdat de data zelf aanleiding geven om aan de normale verdeling te twijfelen, bijvoorbeeld vanwege een scheve verdeling of opvallende uitbijters. We hebben het hier in Paragraaf 24.10 uitgebreid over gehad.
Voor dit soort situaties zijn speciale toetsen ontwikkeld die minder specifieke aannames maken dan de \(t\)-toets over de verdeling van de variabele in de populatie. Deze toetsen worden verdelingsvrije of non-parametrische toetsen genoemd.
Omdat deze toetsen minder specifieke aannames maken, zijn ze minder krachtig. Dat wil zeggen, als je voor dezelfde situatie zowel een \(t\)-toets als een verdelingsvrije toets uitvoert, zal de \(t\)-toets meestal een kleinere \(P\)-waarde opleveren. Maar als de \(t\)-toets niet passend is, komt zo’n minder krachtige toets toch van pas.
In de tabel hieronder is kort een overzicht gegeven van de meest gebruikte verdelingsvrije alternatieven voor de \(t\)-toetsen. We laten ze zien zodat je weet dat ze bestaan; we behandelen ze verder in deze cursus niet.
De alternatieven voor de \(t\)-toets voor één steekproef en de \(t\)-toets voor gepaarde steekproeven zijn gelijk; dat is omdat, zoals we gezien hebben, het in feite om één en dezelfde toets gaat.
Met de \(t\)-toets voor twee onafhankelijke steekproeven kunnen we de gemiddelden van twee populaties vergelijken. In de praktijk vraagt een onderzoek vaak om het vergelijken van meer dan twee groepen. Om dat op een consistente manier te kunnen doen, is ANOVA ontwikkeld. ANOVA staat voor analysis of variance. De nulhypothese van de standaard ANOVA (ook wel “een-weg ANOVA” genoemd) is dat de populatiegemiddelden van alle populaties gelijk zijn. Ook deze toets zullen we verder in deze cursus niet behandelen.
26.7 Samenvatting
In dit hoofdstuk zijn drie toetsen behandeld:
de \(t\)-toets voor één steekproef,
de \(t\)-toets voor twee onafhankelijke steekproeven,
Toets van een hypothese over het populatiegemiddelde van een continue variabele.
\(t\)-toets voor twee onafhankelijke steekproeven
two-sample \(t\) test
Toets van de hypothese dat het populatiegemiddelde van een continue variabele gelijk is voor twee populaties.
\(t\)-toets voor gepaarde steekproeven
\(t\) test for paired samples
Toets van de hypothese dat het gemiddelde verschil van een continue variabele over twee condities gelijk is aan nul.
\(t\)-toets van Welch
Welch’s \(t\) test
Variant van de \(t\)-toets voor twee onafhankelijke steekproeven waarbij niet wordt aangenomen dat beide populaties een gelijke standaarddeviatie hebben.
niet-parametrische / verdelingsvrije toetsen
non-parametric tests
Hypothesetoetsen die geen (of minder specifieke) aannames maken over de verdeling van de variabele in de populatie.
één-weg ANOVA
one-way ANOVA
Een hypothesetoets die bedoeld is voor situaties met meer dan twee populaties. De nulhypothese die getoetst wordt, is dat de gemiddelden van alle populaties gelijk zijn.
26.9 Opgaven
Oefening 26.5 (Het gemiddelde gewicht van de Bonte manakin.)
Lichaamsgewicht is een belangrijke eigenschap bij dieren,
omdat het invloed heeft op hun fysiologie, gedrag en ecologische rol. In deze opgave gebruiken we een uitgebreide dataset over vogels en zoogdieren in Colombia, waarin het lichaamsgewicht van meer dan 42.000 vogels en 7.400 zoogdieren is vastgelegd4. We focussen op de Bonte manakin (Manacus manacus).
In eerder onderzoek wordt beweerd dat het gewicht van de Bonte manakin gemiddeld gelijk is aan 16,5g. Wij willen de Colombiaanse dataset gebruiken om te toetsen of die bewering juist is.
Welke \(t\)-toets zou je moeten gebruiken om die bewering te testen?
Formuleer \(H_\textrm{0}\) en \(H_\textrm{A}\).
Begin een nieuw R script om de analyse te programmeren.
We hebben de gegevens online gezet; voeg de volgende regel toe aan je script om de gegevens te importeren:
Bekijk de dataset even. Welke variabelen zijn er? Hoeveel datapunten?
Onderzoek de dataset. Bereken maten van ligging en spreiding voor de variabele, en visualiseer de verdeling met een boxplot en een histogram.
Wat is het statistische model dat bij deze \(t\)-toets hoort?
Lijkt het Normale Model in dit geval bij voorbaat redelijk?
Voeg een QQ-plot toe om te zien of de verdeling van de gegevens sterk afwijkt van een normale verdeling.
Alles overziend, lijkt de \(t\)-toets geschikt voor deze situatie?
Voer de \(t\)-toets uit met de functie t.test().
Bekijk eerst het 95%-BHI. Wat zegt die?
Bekijk de \(P\)-waarde en trek je conclusies.
Wat vertelt het 95%-BHI je wat je niet uit de \(P\)-waarde kunt opmaken?
En wat vertelt de \(P\)-waarde wat je niet uit het betrouwbaarheidsinterval kunt opmaken?
Oefening 26.6 (Gewichtsverschillen tussen mannetjes en vrouwtjes bij de Bonte manakin.)
In Oefening 26.5 hierboven hebben we het gemiddelde lichaamsgewicht van een Bonte manakin onderzocht. Hierbij hebben we echter geen rekening gehouden met een factor die mogelijk van belang kan zijn voor het gewicht: geslacht. Zoals je in Figuur 26.9 kunt zien hebben de mannetjes en vrouwtjes een heel ander uiterlijk. Daarom willen we in deze opgave onderzoeken of er ook een verschil is in de gewichten van mannelijke en vrouwelijke Bonte manakins. Je kunt doorwerken in het script dat je gemaakt hebt voor Oefening 26.5.
Vrouwelijke Bonte manakin. Foto gemaakt door Dario Sanches uit São Paulo, Brazil
Mannelijke Bonte manakin. Foto gemaakt door Félix Uribe uit Rionegro, Antioquia, Colombia
Figuur 26.9: De Bonte manakin (Manacus manacus). CC BY-SA 2.0
Welke \(t\)-toets zou je voor deze situatie willen gebruiken?
Formuleer \(H_\textrm{0}\) en \(H_\textrm{A}\).
Maak een vector met alleen de gewichten van de mannetjes, en een vector met alleen de gewichten van de vrouwtjes.
Van hoeveel mannetjes en vrouwtjes heb je gegevens?
Maak een boxplot en een histogram voor zowel de mannetjes en de vrouwtjes. Bereken ook maten voor ligging en spreiding.
Wat is het statistisch model van deze \(t\)-toets? (Wat zijn de aannames van het model?)
Lijkt dat model je bij voorbaat plausibel?
Bepaal of je op de waarnemingen zelf aanleiding geven om aan het model te twijfelen. Maak daarvoor ook een QQ-plot of -plots.
Ziet het er goed uit?
Gebruik de t.test() functie om de toets uit te voeren.
Bestudeer de uitvoer:
Wat is het 95%-BHI voor het verschil tussen de gemiddelden van de geslachten? Welk geslacht heeft het grotere gewicht?
Bekijk de \(P\)-waarde en trek je conclusies.
Wat vertelt het 95%-BHI je wat je niet uit de \(P\)-waarde kunt opmaken?
En wat vertelt de \(P\)-waarde wat je niet uit het betrouwbaarheidsinterval kunt opmaken?
Oefening 26.7 (Kurkafzetting.)
Onderzoekers vragen zich af of aan alle kanten van bomen evenveel kurk wordt afgezet. Om dat te bepalen selecteren ze uit een groot bosgebied aselect 28 bomen en meten aan de noord-, zuid-, oost- en westkant de dikte van de kurkafzetting.
In deze opgave negeren we de metingen van de noord- en zuid-kant en onderzoeken we het verschil tussen de oost- en de westkant.
Welke \(t\)-toets zou je willen uitvoeren om de onderzoeksvraag te beantwoorden?
Stel \(H_\textrm{0}\) en \(H_\textrm{A}\) op.
Start een nieuw script voor deze analyse.
De gegevens staan online; importeer ze door de volgende regel aan je script toe te voegen:
Gebruik str(kurk), head(kurk) en/of View(kurk) om de volgende vragen te beantwoorden:
Hoeveel kolommen heeft de dataset?
Hoeveel regels zijn er?
Van welk datatype is elke kolom? Controleer dat R de juiste datatypes heeft gebruikt.
Voordat je een analyses of toetsen gaat uitvoeren, is het belangrijk om de data eerst eens goed te bekijken. Maak daarom boxplots en histogrammen voor de waarden van kolommen OOST en WEST en bestudeer ze.
Bereken ook kengetallen voor de ligging en spreiding van OOST en WEST. Vallen je dingen op? Zijn er opvallende verschillen tussen de kurkafzetting aan de oost- en westkant?
Wat is het statistische model van de \(t\)-toets die je wilt gebruiken?
Lijkt je dat bij voorbaat een redelijk model voor deze variabele?
Maak een QQ-plot en een boxplot of histogram om te controleren dat het model van toepassing is op deze situatie.
Is dat wat jou betreft het geval?
Voer de \(t\)-toets uit met de functie t.test().
Bestudeer de uitvoer van t.test().
Bekijk het 95%-BHI dat gegeven wordt. Wat is de interpretatie van dat interval?
Zoek de \(P\)-waarde op en trek je conclusies.
Wat vertelt het 95%-BHI je wat je niet uit de \(P\)-waarde kunt opmaken?
En wat vertelt de \(P\)-waarde wat je niet uit het betrouwbaarheidsinterval kunt opmaken?
Oefening 26.8 (Eten trage aapjes significant meer gele pixels?)
In Oefening 16.1 van het onderdeel Biologische Modellen heb je een individual-based model onderzocht van aapjes die naar fruit zoeken. Specifiek heb je gekeken naar het effect van de eetsnelheid op de totale hoeveelheid fruit die na 1000 stappen tijdstappen gevonden is.
Als je de simulatie meerdere keren herhaalt bij dezelfde eetsnelheid, krijg je elke keer net een ander resultaat. Toch leek het erop dat de aapjes bij een kleine eetsnelheid (zoals 0,5) typisch meer fruit vonden dan bij een hoge eetsnelheid (zoals 5). Maar is dat verschil daadwerkelijk statistisch significant? Of kunnen de gevonden verschillen ook worden verklaard doordat de resultaten “toevallig” bij de ene parameter wat hoger zijn uitgevallen dan bij de andere?
Als het goed is, heb je series experimenten uitgevoerd voor drie verschillende waarden van de eetsnelheid, en heb je je resultaten bewaard. Gebruik \(t\)-toetsen5 om te onderzoeken of je op basis van deze gegevens kunt concluderen dat de hoeveelheid fruit die gemiddeld gevonden wordt verschilt tussen deze drie condities.
In de praktijk heeft dat onderzoek allerlei haken en ogen. Hoe selecteren we gezonde personen? Hoe ga je om met het feit dat de lichaamstemperatuur ’s ochtends gemiddeld lager is dan ’s middags, of het verschil tussen mannen en vrouwen?
Toch zijn er pogingen gedaan om de norm van 37\(\degree\)C te toetsen:
Mackowiak, P. A., S. S. Wasserman, and M. M. Levine. “A Critical Appraisal of 98.6 Degrees F, the Upper Limit of the Normal Body Temperature, and Other Legacies of Carl Reinhold August Wunderlich.” JAMA 268, no. 12 (September 23, 1992): 1578–80.↩︎
Horst AM, Hill AP, Gorman KB (2020). palmerpenguins: Palmer Archipelago (Antarctica) penguin data. R package version 0.1.0. https://allisonhorst.github.io/palmerpenguins/. doi: 10.5281/zenodo.3960218.↩︎
Het vergelijken van meer dan twee condities/groepen zou je eigenlijk met ANOVA moeten doen (zie Paragraaf 26.6.2), met daarna post-hoc toetsen, maar omdat we dat niet behandeld hebben, zien we dat nu even door de vingers.↩︎