In Hoofdstuk 13 hebben jullie kennis gemaakt met individual-based models, en met name het belang van ruimtelijke structuur in biologische populaties. Voor het gemak namen we in dit eerdere hoofdstuk aan dat individuen posities innamen op een grid, maar in werkelijkheid is ruimte natuurlijk niet in hokjes opgedeeld. In dit hoofdstuk gaan we een aantal individual-based modellen bekijken waar individuen vrij kunnen bewegen in een continue ruimte. Hiervoor zullen we eerst leren wat er eigenlijk wordt bedoeld met een “continue” ruimte. Daarna bekijken we eerst wat conceptuele voorbeelden, en gaan dan naar meer biologisch relevante scenarios kijken.
Aan het eind van dit hoofdstuk, word je geacht hetvolgende te kunnen:
Uitleggen wat het verschil is tussen discrete en continue variabelen, en modelaspecten kunnen benoemen waarbij deze keuze relevant is
Begrijpen dat simpele regels complexe patronen en gedrag kunnen opleveren
Uitleggen wat de voordelen zijn van het virtuele experimenteren / het virtueel bestuderen van gedrag
Uitleggen wat een parameter-sweep is, en hoe dit zich verhoudt tot bifurcatie analyse van wiskundige modellen
16.1 Modelkeuzes met continue en discrete variabelen
Eerder in dit cursusonderdeel heb je al kennisgemaakt met discrete tijdstappen. Zo zagen we bijvoorbeeld bij de differentievergelijkingen dat je alleen in één keer van \(t=1\) naar \(t=2\) kan gaan. Met differentiaalvergelijkingen is tijd continu, en is de tijd tussen \(t=1\) en \(t=2\) in oneindig kleine stapjes is opgedeeld. Ook bij andere facetten van een model moeten we kiezen tussen discrete en continue waarden: modelleren we het daadwerkelijke (discrete) aantal konijnen, of versimpelen we hun aantal tot een (continue) dichtheid? Met ODEs, en zo ook met het predator-prooi model, nemen we aan dat populatiegrootes continu zijn. Zelfs als de dichtheid vossen kleiner is dan 1, kan dit nog steeds een biologisch relevant aantal vossen omschrijven (want \(1 \over 10\) vossen per vierkante meter is nogsteeds een behoorlijk druk bos!). Maar hoe klein kan de dichtheid zijn voordat we ons zorgen moeten maken of we het nog over “hele vossen” hebben? Om te illustreren hoe belangrijk dit is, kun je in Tip 16.1 lezen over het probleem van “de atto-vos”.
Belangrijk 16.1: De atto-vos
In 1991, tijdens het graven van de kanaaltunnel tussen Engeland en Frankrijk, waren er veel zorgen dat vossen met rabiës (hondsdolheid) de vossen in het Verenigd Koninkrijk zouden besmetten. Echter is het VK tot op de dag van vandaag volledig rabiës-vrij gebleven. De voorspelling was gedaan met een ODE-model, maar de dichtheid van de vossenpopulatie die succesvol door de kanaal-tunnel zou migreren was zeer laag (\(10^{-18}\)). Een hoeveelheid in de ordegrootte \(10^{-18}\) wordt ook wel “atto” genoemd (net zoals micro \(10^{-6}\) is en nano \(10^{-9}\) heet). Daarom kunnen we dit artefact van modelleren het “atto-vos”-probleem noemen. Want laten we eerlijk zijn: een heel klein stukje vos kan niet door een tunnel migreren, en dus ook geen ziektes verspreiden!
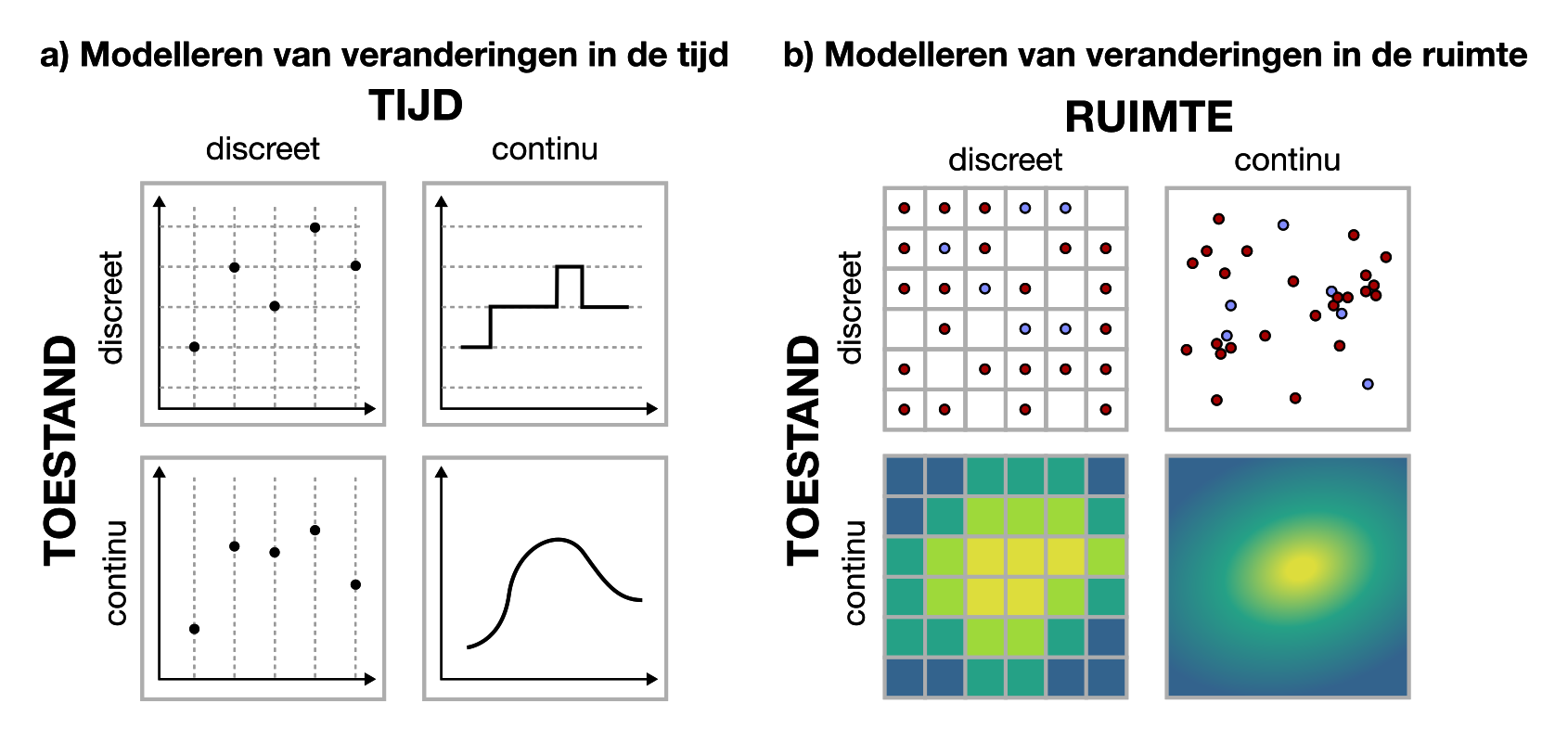
Het probleem van discrete tijdstappen uit Hoofdstuk 10 en de anekdote van de atto-vos zijn niet de enige momenten dat het belangrijk is om stil te staan bij wat voor variabelen we gebruiken, en wat ze precies betekenen. Bij elk model is het belangrijk om na te gaan welke keuze het meest logisch is: zijn de variabelen (toestand, tijd, en ruimte) discreet of continu (Figuur 16.1)? Natuurlijk zijn modellen altijd doelbewuste versimpelingen, maar in het geval van de atto-vos schepte het model een heel verkeerd beeld van het probleem! Toch is experimenteren met infectieziektes zeer onwenselijk, dus zijn deze modellen natuurlijk wel een zeer belangrijk stuk gereedschap! Laten we onze eerdere aanname dat ruimte in “hokjes” is opgedeeld dus ook eens onder de loep nemen.
Figuur 16.1: Bij het opzetten van een model moeten we voor veel verschillende variabelen kiezen of deze continu of discreet gemodelleerd gaan worden.
16.2 Particle life
From https://youtu.be/p4YirERTVF0
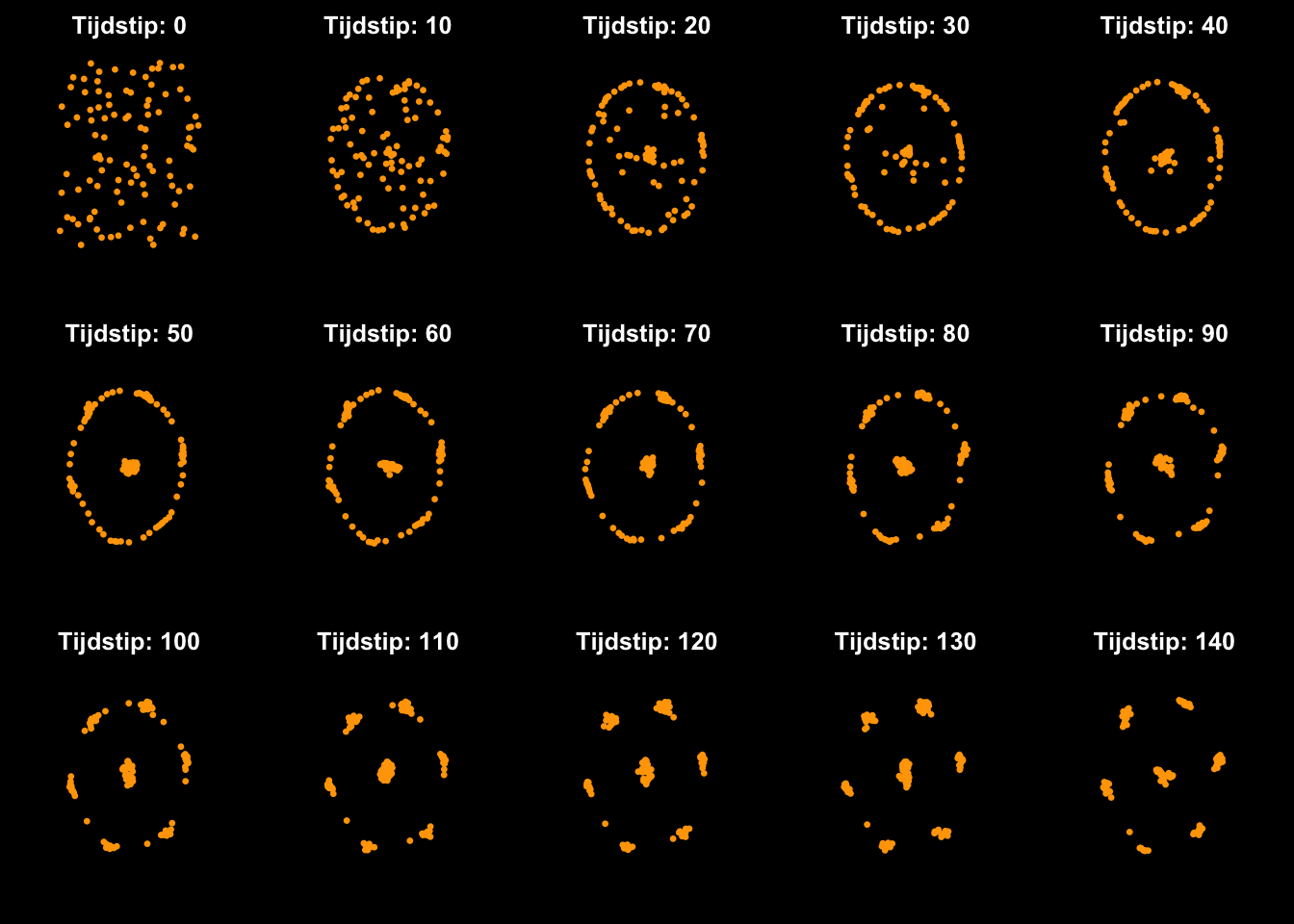
Hoewel biologie zeer complex is, bestaat het fundamenteel niet uit andere deeltjes dan niet-levende systemen. Deeltjes trekken elkaar aan, stoten elkaar af, en ondergaan interacties. Laten we zoiets in R modelleren, en kijken wat er gebeurt. Stel je voor dat we 100 punten in een ruimte verspreiden, allemaal met een x- en y-coördinaat. Zoals hierboven besproken kiezen we er dit keer niet voor om de coördinaten als gehele getallen (1, 2, 3, ) uit te drukken, maar drukken we ze uit als decimale getallen (2.159, 0.156, ). We geven de 100 punten allereerst een willekeurige plek in de ruimte, en nemen dan aan dat ze elkaar van een afstand aantrekken, terwijl ze op kleine schaal elkaar juist afstoten. Hoewel de code hiervoor niet super ingewikkeld is, is de code geen leerstof. In plaats daarvan, kunnen we onze regels uitdrukken in “pseudocode”, waarin we verbaal omschrijven wat er moet gebeuren:
Verspreid 100 punten in een 2D ruimte met willekeurige coördinaten tussen 0 en 1
Voor elk punt, bereken de afstand tot alle punten in de buurt, en zet een stapje in hun gemiddelde richting (dus naar het midden van de groep)
Wanneer twee punten overlappen, zet juist dan een stapje weg van dit punt.
(elke 10e tijdstap, geef de punten weer in een plot)
Ga terug naar stap 2
Zoals gezegd, de R code hoeven jullie niet te begrijpen, maar voor de geïnteresserde student staat deze hier:
Code voor geïnteresseerde student
set.seed(8)# Aantal tijdstappenpar(mar =rep(2, 4), bg ="black")aantal_tijdstappen <-150# Aantal puntenaantal_punten <-100# Startcoördinatenalle_posities <-data.frame(x =runif(aantal_punten),y =runif(aantal_punten))# Parameters voor gedrag van puntenminimale_afstand <-0.4aantrekkingsfactor <-0.001# Factor voor de (globale) aantrekkingskrachtbotsingsfactor <-0.003# Factor voor de (lokale) afstotingskracht# Functie om, per punt, de aantrekkingskracht en botsingsdetectie te berekenenupdate_positie <-function(alle_posities, i) { dx <-0#verandering in x voor dit punt dy <-0#verandering in y voor dit puntfor (j in1:aantal_punten) {if (i != j) { #niet met jezelf botsen / naar je zelf toe bewegen afstand_x <- alle_posities$x[j] - alle_posities$x[i] afstand_y <- alle_posities$y[j] - alle_posities$y[i] afstand <-sqrt(afstand_x^2+ afstand_y^2) #stelling van pythagoras# Aantrekkingskracht dx <- dx + aantrekkingsfactor * afstand_x / afstand dy <- dy + aantrekkingsfactor * afstand_y / afstand# Afstotingskracht voor botsingsdetectieif (afstand < minimale_afstand) { dx <- dx - botsingsfactor * afstand_x / afstand dy <- dy - botsingsfactor * afstand_y / afstand } } }return(c(dx, dy))}par(mfrow=c(3,5))# Simuleer de diffusie en toon de resultaten stap voor stapfor (t in1:aantal_tijdstappen) {# Maak (leeg) dataframe voor posities in volgende tijdstap nieuwe_positie <-data.frame(x =numeric(aantal_punten), y =numeric(aantal_punten))# Bereken de verplaatsingen op basis van huidige positiesfor (i in1:aantal_punten) { verplaatsing <-update_positie(alle_posities, i) nieuwe_positie$x[i] <- alle_posities$x[i] + verplaatsing[1] nieuwe_positie$y[i] <- alle_posities$y[i] + verplaatsing[2] }# Update alle posities alle_posities <- nieuwe_positie# Plot de huidige posities van de puntenif(t%%10==1){plot(alle_posities$x, alle_posities$y, xlim =c(0, 1), ylim =c(0, 1), col ="orange", pch =19, cex =0.5,xlab ="X", ylab ="Y")title(sprintf("Tijdstip: %d", t-1),col.main="white") }}
Zoals je ziet ontstaat er na een tijdje een zeer specifiek patroon. Als je dit patroon nog niet erg spannend vindt, zouden we ook kunnen kijken wat er met meerdere deeltjes (kleuren) gebeurt, die naast de aantrekkingskracht op henzelf ook elkaar aantrekken. Bijvoorbeeld: oranje is aangetrokken tot rood, rood tot paars, etc. Dan gebeurt er hetvolgende:
Klik hier voor de R-code. De browser-simulatie hieronder is geïmplementeerd met Javascript
library(stringr)# Set up the plot areapar(mar =rep(2, 4), bg ="black")# Define global parametersnum_colors <-6dots_per_color <-100total_particles <- num_colors * dots_per_colorcolors <-rep(c("#E40303", "#FF8C00", "#FFED00", "#008026", "#24408E", "#732982"), each = dots_per_color)movement_rate <-0.0003# Control the influence of the attraction/repulsionself_attraction_rate <-0.0005# Mild attraction to particles of the same colorrepulsion_distance <-3.5# Distance threshold for repulsionspeed <-0.1# Control the delay between frames (R-studio wont keep up otherwise!)noise_level <-0.01# Define the level of noise to add to the directions# Initialize positions of the particles in distinct regionspositions <-matrix(0, nrow = total_particles, ncol =2)set.seed(42)for (i in1:num_colors) { start_index <- (i -1) * dots_per_color +1 end_index <- i * dots_per_color positions[start_index:end_index, ] <-matrix(runif(dots_per_color *2, min = (i -1) *1-10, max = i *1-10), ncol =2)}directions <-matrix(runif(total_particles *2, min =-0.1, max =0.1), ncol =2)# Function to get the next color in the sequencenext_color <-function(color) { color_order <-c("red", "blue", "green", "orange", "purple")return(color_order[(match(color, color_order) %% num_colors) +1])}# Function to update positionsupdate_positions <-function(positions, directions, movement_rate, self_attraction_rate, repulsion_distance) {for (i in1:total_particles) { attraction_force <-c(0, 0) repulsion_force <-c(0, 0) self_attraction_force <-c(0, 0)# Calculate attraction, self-attraction, and repulsion forcesfor (j in1:total_particles) {if (i != j) { diff <- positions[j, ] - positions[i, ] distance <-sqrt(sum(diff^2))# Attraction to particles of the next color in sequenceif (colors[j] ==next_color(colors[i]) && colors[i] !="purple") { attraction_force <- attraction_force + movement_rate * diff }# Mild attraction to particles of the same colorif (colors[j] == colors[i]) { self_attraction_force <- self_attraction_force + self_attraction_rate * diff }# Repulsion from particles that are too closeif (distance < repulsion_distance) { repulsion_force <- repulsion_force - movement_rate * (repulsion_distance - distance) * diff / distance } } }# Add noise to the direction noise <-runif(2, min =-noise_level, max = noise_level) directions[i, ] <- noise positions[i, ] <- positions[i, ] + directions[i, ]# Combine forces total_force <- attraction_force + self_attraction_force + repulsion_force directions[i, ] <- total_force positions[i, ] <- positions[i, ] + directions[i, ] }return(list(positions = positions, directions = directions))}# Create a directory to save the frames#dir.create("frames")par(bg ='black')# Update and animate the particlesfor (i in1:1000) {#png(filename = sprintf("frames/frame_%04d.png", i), width = 1280, height = 720, bg = "black")# Initialize plot# Update positions and directions updated <-update_positions(positions, directions, movement_rate, self_attraction_rate, repulsion_distance) positions <- updated$positions directions <- updated$directionsplot(NULL, xlim =c(-10, 10), ylim =c(-10, 10), xlab ="", ylab ="", xaxt ='n', yaxt ='n', asp =1, axes=F)# Add a semi-transparent black backgroundrect(-100, -100, 100, 100, col =rgb(0, 0, 0, 0.05), border =NA)# Draw the particlespoints(positions[, 1], positions[, 2], col = colors, pch =16, cex =0.4)# Pause for a moment to create animation effectSys.sleep(speed)}
Interactieve content beschikbaar op de website:
Zoals je ziet vormen de deeltjes nu niet meer een stabiel patroon, maar blijven de deeltjes constant rondjes om elkaar heen draaien. Als we één van deze 6 kleuren (rood) juist geen aantrekking geven tot een andere kleur, dan gebeurt er werkelijk iets opmerkelijks:
Interactieve content beschikbaar op de website:
Zoals je je kan voorstellen, kunnen variaties op deze simpele regels enorm veel verschillende patronen opleveren. Het systeem wat je hier bekijkt is particle life genoemd. Als je hier meer over wil weten, vind je hier een uitgebreide video, en hier een app die je zelf kan downloaden om met deze systemen te spelen.
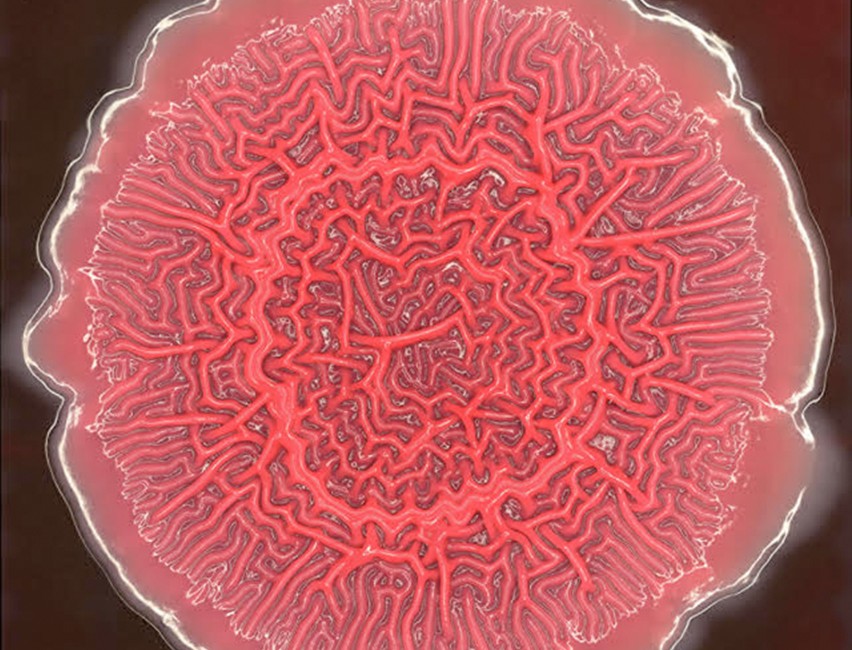
Als je de bovenstaande video’s en simulaties bekijkt zou je bijna denken dat je naar echte beestjes kijkt. Het lijkt bijvoorbeeld bijna alsof de bovenstaande worm “beslissingen” maakt wanneer deze zich plotseling omdraait. Maar alles gaat alleen maar om het aantrekken en wegduwen van stipjes. Een enkele stip zou natuurlijk niet dergelijk complex gedrag ontwikkelen, dat gebeurt alleen in de aanwezigheid van anderen. Als simpele onderdelen bij elkaar komen en daardoor complexe dynamica of patronen genereren, spreken we van een emergente eigenschap/emergente eigenschappen. Emergente eigenschappen komen we overal tegen in de biologie: van vetzuren die zich organiseren tot dubbele membranen, tot microben die doolhof-achtige patronen vormen (Figuur 16.2), tot de strepen op een zebra, tot chimpansees en mensen die complexe politieke structuren vormen. Hoewel al deze structuren erg complex lijken, is het in de kern wellicht gedreven door hele simpele regels.
Figuur 16.2: Foto door Lars Dietrich (Columbia University)
16.3 Zwermpatronen in boids
Particle life is een zogenaamd toy model. Dat wil zeggen: het laat bepaalde principes heel goed zien, maar het is niet per se een model van een specifiek biologisch systeem. Maar het illustreert wel heel goed dat complex (emergent) gedrag uit hele simpele regels kan ontstaan. Hier en daar doet het zelfs wel wat denken aan de zwermpatronen die je ziet in bijvoorbeeld insecten, vissen en vogels. Wellicht kunnen we dit model aanpassen om specifieker naar dit gedrag te kijken: hoe spreeuwen zogenaamde “murmuraties” vormen.
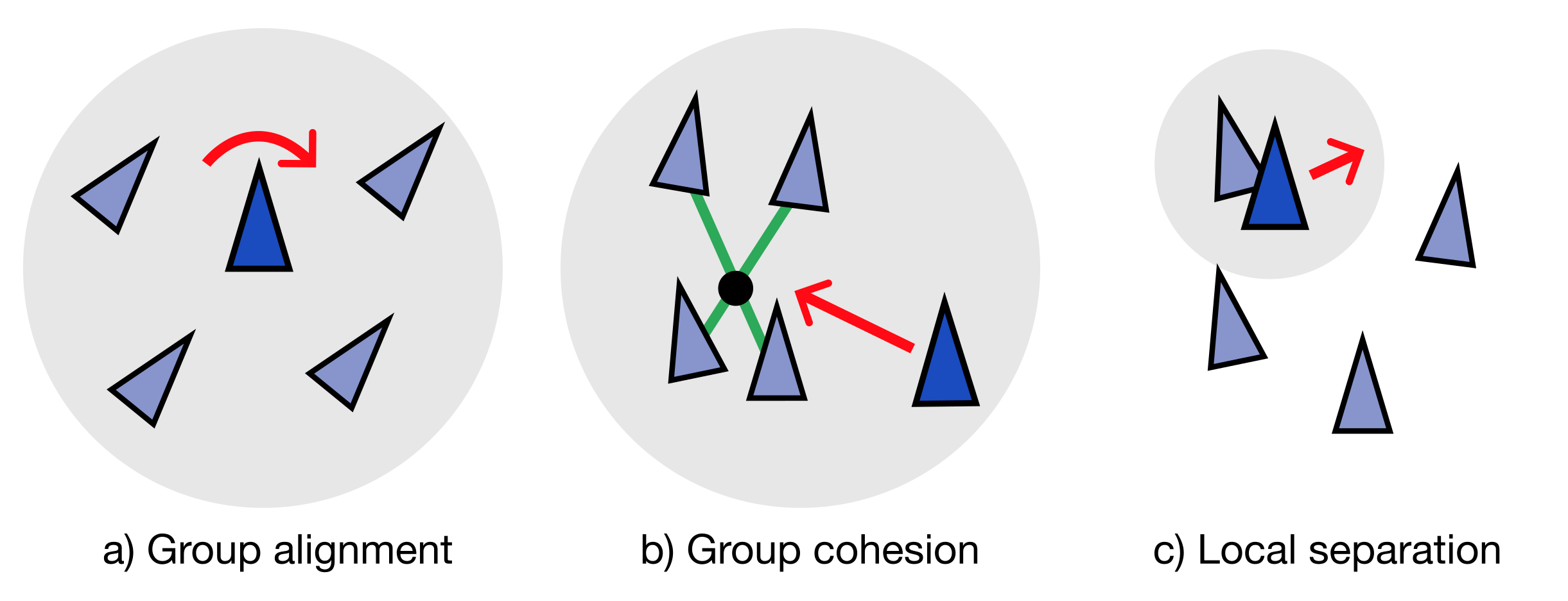
Laten we er allereerst vanuit gaan dat de vogels alleen andere vogels kunnen zien wanneer die in hun buurt zijn. Dat wil zeggen, hun gedrag wordt alleen bepaald door nabije buren. In pseudocode, volgt elke vogel de volgende regels:
Probeer je richting uit te lijnen met de groep
Beweeg je naar het midden van de groep toe
Probeer te voorkomen dat je met anderen botst
De drie simpele regels van Boids: een model dat prachtige “murmuraties” op kan leveren.
Als je deze drie regels samenvoegt, zul je zien dat je onmiddellijk prachtige murmuraties ziet:
Interactieve content beschikbaar op de website:
Dit model is door de bedenker, Craig Reynolds, “boids” genoemd, omdat hij het grappig vond hoe mensen in New York het woord birds uitspraken. Anders dan particle life, kunnen we met een dergelijk model wel degelijk biologisch onderzoek doen. Het wordt bijvoorbeeld door de onderzoeksgroep van Charlotte Hemelrijk (Emeritus professor aan de Rijksuniversiteit Groningen) gebruikt om te onderzoeken hoe zwermen van spreeuwen reageren op predatie door haviken. Met dergelijk onderzoek kunnen we observaties uit het veld goed aanvullen, want dergelijk veldwerk is natuurlijk heel pittig en tijdrovend! Dat gezegd hebbende, is er natuurlijk niets zo indrukwekkend als echte beelden van dit prachtige fenomeen:
16.4 Aapjes met gedrag
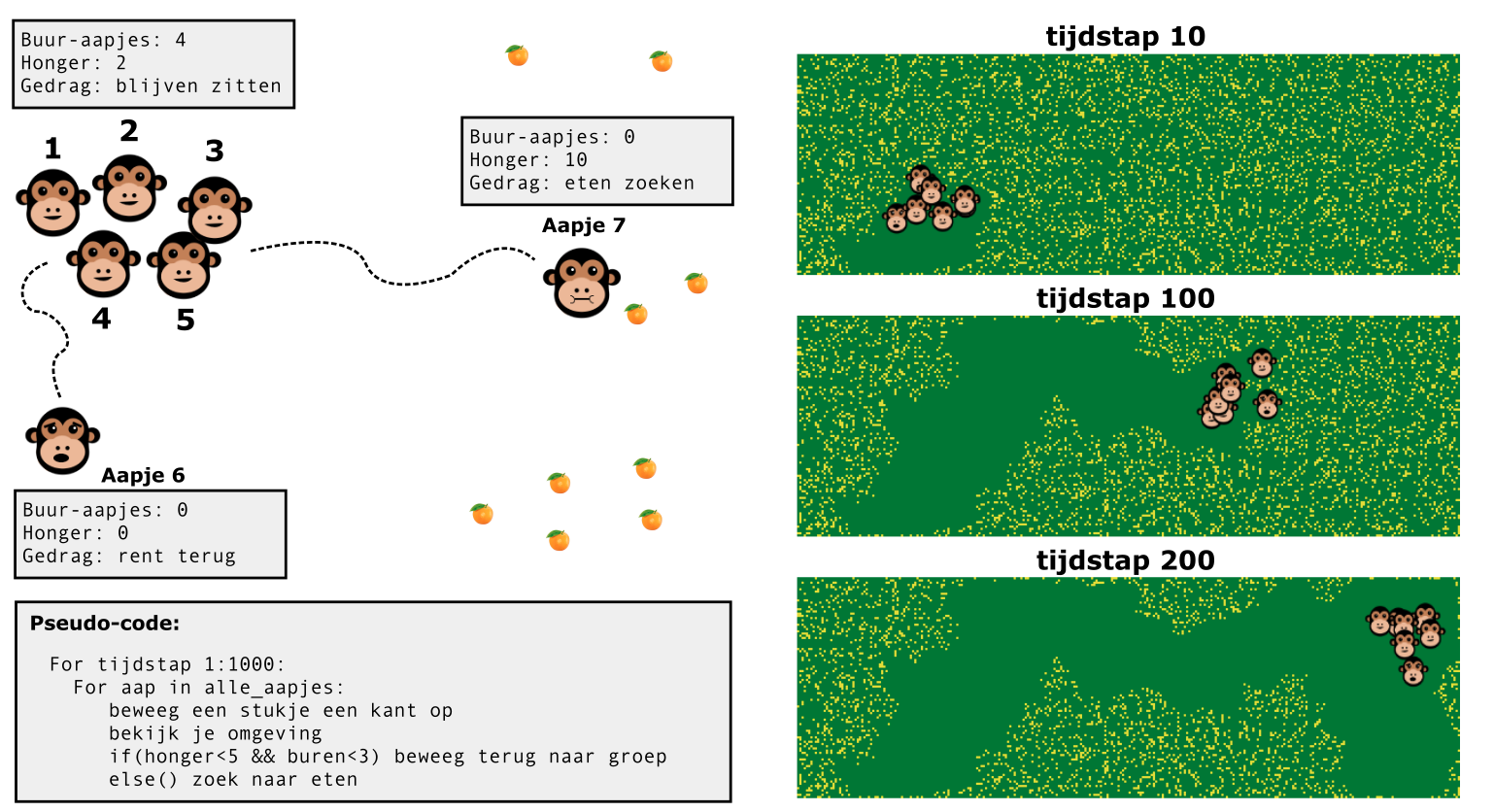
In hoofdstuk Hoofdstuk 13 hebben we de basis geleerd van individual-based modellen, maar hebben we vooral gekeken naar groeiende populaties op een grid. Hoewel dergelijke grids veel technische voordelen hebben (een grid is heel handig als je snel wilt bepalen wie er “naast” iemand zit), is een echt ecosysteem natuurlijk niet in hokjes opgedeeld. Nu we hierboven individuen iets meer vrijheid hebben gegeven, kunnen we wellicht ook meer “gedragsregels” toevoegen. Laten we dit eerst doen met een simpel model van aapjes die naar fruit zoeken.
Overzicht van een individual based model van aapjes die naar eten zoeken.
Laten we een groot grasveld voorstellen, waarin zich individuele aapjes bevinden. Wederom schrijven we het systeem op in pseudocode:
Voor elke aap in de simulatie:
Als er minder dan 10 apen in de buurt zijn, en de aap heeft geen enorme honger, dan rent deze terug naar de groep.
Als een aap honger heeft, en er zijn genoeg apen in de buurt, loopt deze een willekeurige kant op om te zoeken naar fruit.
Als een aap 6 stukken fruit heeft gevonden, blijft de aap zitten en gaat eten. Zolang de aap aan het eten is, gaat deze niet op zoek naar de groep of naar meer eten.
Opmerking
Nu je een paar keer pseudocode hebt gezien, begrijp je misschien waarom dit handig is. Als wetenschapper is het belangrijk om goed te communiceren hoe je onderzoek precies is opgezet, maar we willen niet altijd door hele stukken code moeten lezen. Het doel van pseudocode is om deze precies genoeg te maken, zodat iemand anders het zou kunnen reproduceren (eventueel in een andere programmeertaal!). De resultaten van zo’n computermodel zouden namelijk niet van de programmeertaal moeten afhangen, maar van de aannames die gedaan worden.
Zoals je in de bovenstaande omschrijving kan lezen, zal niet elk aapje hetzelfde doen. Aapje 1 t/m 5 hebben veel buur-aapjes en voelen zich veilig. Omdat ze ook geen honger hebben, blijven ze zitten. Aapje 6 heeft ook geen honger, maar voelt zich niet veilig, en rent terug naar de groep. Aapje 7 heeft echter veel honger, en zal dus (eventueel met gevaar voor eigen leven) naar eten blijven zoeken. Door deze gedragsregels een lange tijd te herhalen, kunnen we onderzoeken hoe onze virtuele aapjes naar eten zoeken, en hoe ze groepjes vormen.
Interactieve content beschikbaar op de website:
Met een dergelijk model kun je heel goed biologisch onderzoek doen (je kan heel veel simulaties tegelijk runnen, en je verstoort alleen virtuele apen!). Heel leuk onderzoek is bijvoorbeeld gedaan door Daniel van der Post, die heeft laten zien dat verschillende apengroepen in dezelfde omgeving hele andere voedselculturen kunnen ontwikkelen1. In het werkcollege gaan jullie met deze simulatie aan de slag, en bestuderen hoe emergente eigenschappen bepalen hoe veel fruit deze aapjes vinden. Natuurlijk kan je allerlei gedrag aan een dergelijk model toevoegen: vlooien, vechten, opvoeden, en ga zo maar door. Deze modellen kunnen dus een hele efficiënte (snel, goedkoop) en niet-verstorende manier zijn om gedrag te bestuderen.
16.5 Parameter-sweeps
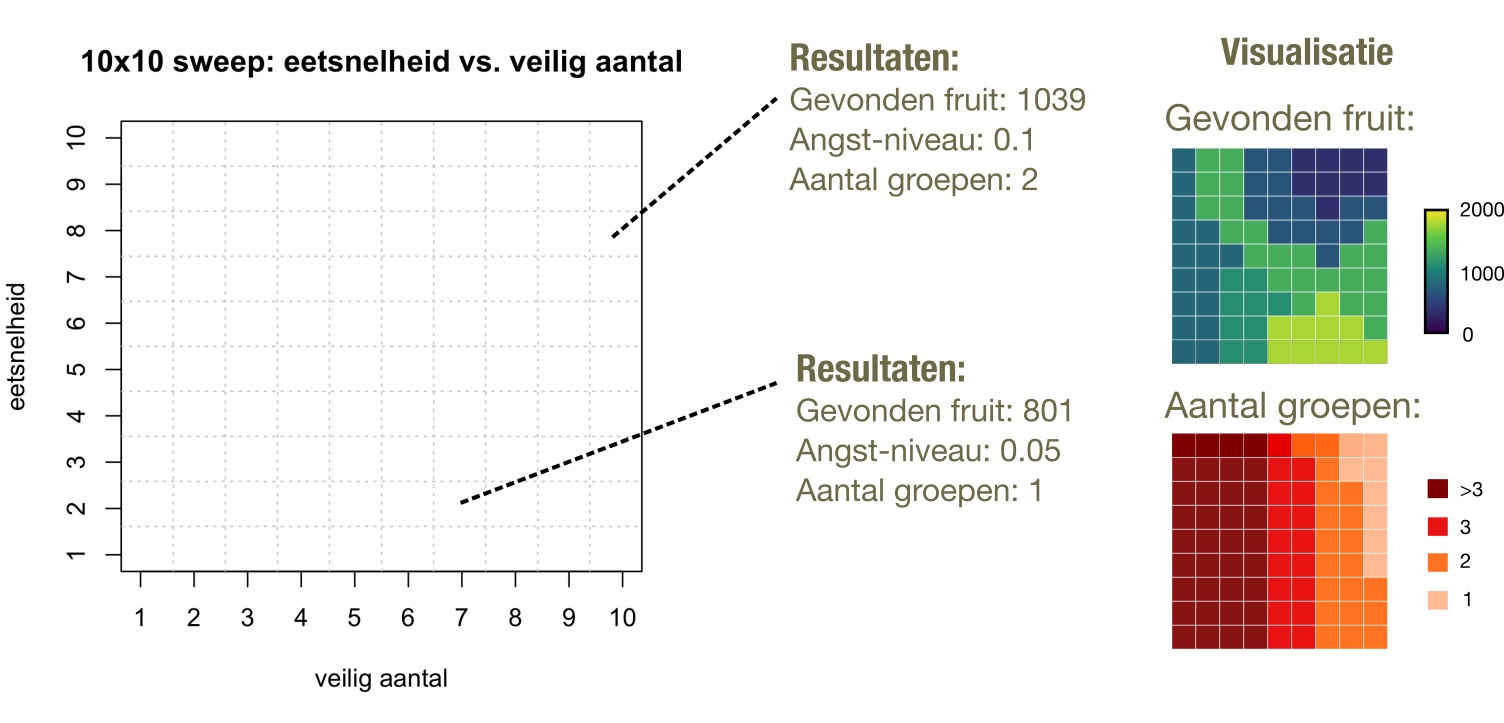
In de hoofdstukken over het Lotka-Volterra predator-prooi model heb je kennis gemaakt een bifurcatie-diagram (Figuur 4). Door de parameter \(K\) te varieren, zagen we twee belangrijke overgangen (bifurcaties): eerst een overgang van alleen prooi naar een stabiele samenleving van predator en prooi, en dan een tweede overgang naar oscillerende predator-prooi populaties (Hopf bifurcatie). Computermodellen zoals de IBM van de aapjes hierboven bevatten vaak erg veel parameters: hoe snel eten de aapjes, hoeveel aapjes moeten er in de buurt zijn zodat een aapje zich veilig voelt, hoeveel eten ligt er in de omgeving, etc. Zodoende is het vaak belangrijk om een zogeheten parameter-sweep te doen, waarbij je vele parameters systematisch bestudeert en de uitkomst classificeert. Op deze manier kun je enerzijds bepalen of het gedrag van je model niet maar alleen voorkomt voor hele specifieke parameters (en dus wellicht in werkelijkheid nauwelijks voorkomt) en anderzijds bepalen welke parameters het meest belangrijk zijn voor hoe het model zich gedraag. Als je bijvoorbeeld twee parameters varieert, kun je deze uitkomsten bijvoorbeeld opslaan in een grote tabel waarbij de rijen de ene parameter zijn, en de kolommen de andere (Figuur 16.3).
Figuur 16.3: Een hypothetisch voorbeeld van een parameter sweep van 2 parameters, en een heatmap visualisatie van de resultaten.
16.6 Foeragerende mieren
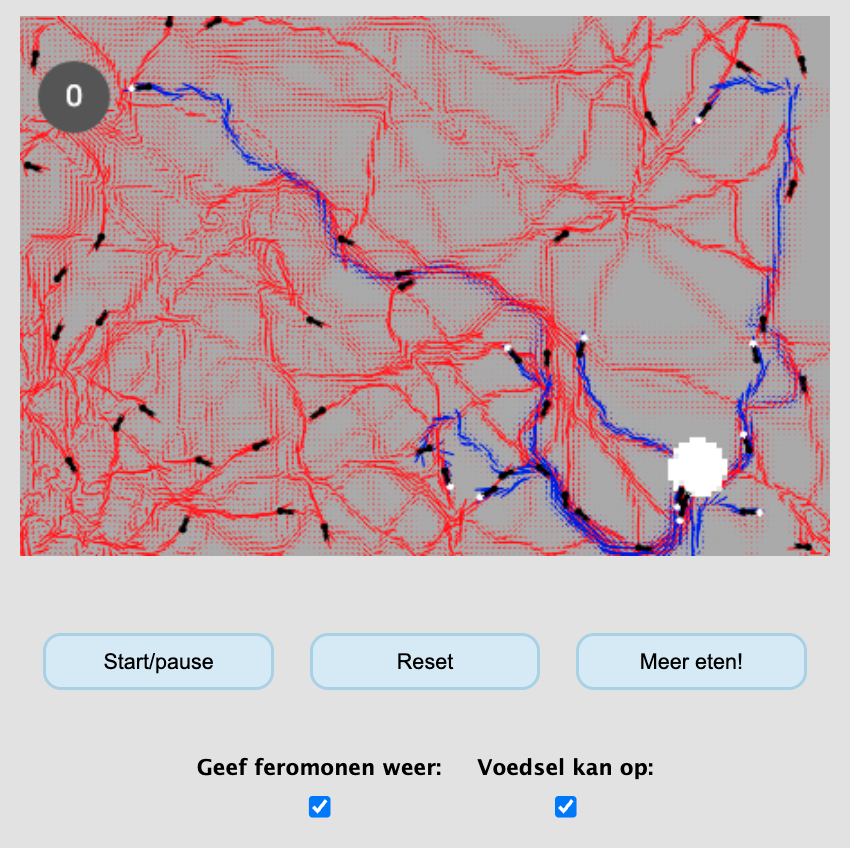
Als het gaat om foerageren, lijken mieren een stuk georganiseerder dan de aapjes uit de bovenstaande simulatie. Ze rennen niet maar zo een kant op, maar volgen elkaar netjes van/naar een voedselbron. Echter doen mieren dat niet altijd door elkaar te zien (sterker nog, sommige mieren zijn volledig blind!). In plaats daarvan ruiken ze elkaars feromonen, die bijvoorbeeld aangeven waar het voedsel ligt, waar het nest is, of waar er gevaar dreigt. Hoewel dit meestal heel goed werkt, kun je ook een zogeheten “mierenkringen” ant mills krijgen, waar mieren voor eeuwig in rondjes achter elkaar aan lopen (soms net zo lang tot ze van uitputting dood gaan!).
Mieren vormen paadjes naar/van het eten door elkaars feromonen te volgen…
.. maar kunnen daardoor ook in een zogeheten ant-mill terecht komen!
Dus, een belangrijk verschil met de aapjes is dat de mieren niet direct elkaar zien, maar feromonen. Mieren laten deze feromonen achter, maar deze feromonen worden ook afgebroken of verdunnen. Zo ontstaat er dus een interessante interactie van de mieren naar de omgeving, en van de omgeving naar de mieren. Diffusie van stofjes is een concept waar we in het volgende hoofdstuk nog meer naar zullen kijken. Maar voor nu, als we deze componenten samenbrengen in een simulatie, zien we inderdaad dat mieren niet alleen prachtige sporen vormen, maar ook de bovengenoemde mierenkringen kunnen vormen:
Interactieve content beschikbaar op de website:
16.7 Opgaven
Let op: dit hoofdstuk heeft slechts 1 opgave. Echter is het wel belangrijk dat je de vraag maakt, want de resultaten sla je op in een tabel die je bij het onderdeel Statistiek verder zal analyseren.
Daarnaast kun je verder werken aan het mini-project, waarbij je met een groep samenwerkt om zorgvuldig verslag te doen van een uitgebreide werkcollegevraag.
Oefening 16.1 (Aapjes die gele pixels eten)
Afbeelding gegenereerd met ChatGPT4-o, November 2024
In deze opgaven kijken we naar het individual-based model van aapjes die naar fruit zoeken, zoals besproken in dit hoofdstuk. De aapjes volgen de volgende regels:
Als er minder dan 10 apen in de buurt zijn, ren terug naar de groep
Als er genoeg apen in de buurt zijn, loop een willekeurige kant op om te zoeken naar fruit
Als je 6 stukken fruit hebt gevonden, blijf zitten waar je zit en ga eten. Eet per tijdstap een x-aantal stukken fruit, gegeven door de parameter “eet-snelheid”. Pas als je klaar bent met eten ga je weer terug naar de groep.
In de simulatie wordt bijgehouden hoeveel fruit de aapjes (in totaal) hebben gevonden. De aapjes eten standaard 3 stukken fruit per tijdstap, (dus eten voor 2 tijdstappen).
Wacht 1000 tijdstappen. Waarom neemt de totale hoeveelheid gevonden fruit na een tijdje niet zo veel meer toe?
Vorm met andere studenten groepjes van 2. Kies een hogere óf lagere eetsnelheid. Herhaal je experiment 5 keer en schrijf iedere keer op hoeveel fruit er is gevonden na 1000 tijdstappen. Bekijk ook goed hoe de aapjes zich over het veld bewegen.
Kies een andere eetsnelheid, en herhaal weer 5 keer je experiment. Zie je verschillen? Had je dit resultaat verwacht?
Vergelijk je resultaten ook met een ander groepje. Probeer je ondervindingen biologisch uit te leggen.
Bewaar je resultaten in een tabel. Deze ga je in het onderdeel ‘Statistiek’ bestuderen om te kijken of je resultaten betrouwbaar zijn, of dat het misschien toch toeval is.
16.8 Terminologie
Nederlands
Engels
Beschrijving
Discrete variabelen
Discrete variables
Variabelen die niet alle waarden kunnen innemen, maar alleen waarden met een vaste afstand. Meestal heeft dit simpelweg de vorm 1,2,3, etc., maar je zou er ook voor kunnen kiezen om alleen met tienvouden te werken ( 1,10,100,1000) of om ook negatieve getallen te gebruiken (-10,-9,-8)
Continue variabelen
Continuous variables
Variabelen die alle numerieke waarden in een bepaald bereik kunnen innemen. Bijvoorbeeld alle waarden tussen 0 en 1 of alle waarden tussen \(-\infty\) en \(\infty\). Tussen 0 en 1 zitten oneindig veel waarden, en tussen \(-\infty\) en \(\infty\) zitten ook oneindig veel waarden. (eigenlijk zou je dus kunnen stellen dat sommige oneindigheden groter zijn dan andere oneindigheden!)
Discrete ruimte
Discrete space
De gemodelleerde ruimte is opgedeeld in vaste afstanden, zoals bijvoorbeeld op een grid van vierkanten waar ieder punt 4 of 8 buren heeft (afhankelijk van of je de diagonale buren meetelt). Ook een hexagonaal patroon (zoals een bijenkorf) is een discrete ruimte, waarbij iedere hexagon 6 buren heeft.
Continue ruimte
Continuous space
De gemodelleerde ruimte heeft geen vaste posities, waardoor punten, eiwitten, individuen, etc. elke positie in kunnen nemen. Dit geeft vaak vloeiende bewegingen, maar is een stuk moeilijker voor je computer om door te rekenen!
Pseudocode
Pseudocode
Een verbale omschrijving van wat een computerprogramma doet (en hoe deze dat doet!), zonder ons druk te maken over de technische aspecten zoals het gebruik van de juiste syntax, de functienamen, of alle komma’s op de goede plek staan, etc.
Emergente eigenschappen
Emergent properties
Een eigenschap van een systeem die ontstaat door de interactie tussen de onderdelen, en die niet zichtbaar is in de losse onderdelen zelf. Bijvoorbeeld: individuele neuronen kunnen niet “denken”, maar een groot aantal neuronen met de juiste verbindingen kunnen deze zin interpreteren ook al is de zin veel te lang en staat er te weinig interpunctie in.
Van der Post, D. J., & Hogeweg, P. (2008). Diet traditions and cumulative cultural processes as side-effects of grouping. Animal Behaviour, 75(1), 133-144.↩︎