2^64 - 1[1] 1.844674e+19In dit eerste hoofdstuk gaan we een belangrijk concept uit de biologie beter leren begrijpen: exponentiële groei. Na dit hoofdstuk word je geacht het volgende te kunnen:

In het introducerende hoofdstuk hebben we besproken dat alle modellen drie belangrijke basisingrediënten hebben: variabelen, parameters, en aannames. Laten we aan de hand van deze begrippen een model maken van de beroemde mythe over de ontdekking van het schaakspel. De koning beloofde de ontdekker namelijk een gigantische hoeveelheid rijst.
De mythe van de ontdekking van het schaakspel is een beroemde legende uit India. Volgens het verhaal wilde een koning de uitvinder van het schaakspel belonen. In schijnbare bescheidenheid vroeg de uitvinder om rijst: één korrel op het eerste veld van het schaakbord, twee op het tweede, vier op het derde, en zo verder, telkens verdubbelend tot het 64e veld is bereikt. De koning stemde toe, zich niet realiserend hoeveel rijst hij zojuist had beloofd. Tegen de tijd dat het 64e veld bereikt was, had de koning niet genoeg rijst in zijn hele koninkrijk om aan de vraag te voldoen. Het totaal aantal korrels rijst komt uit op:
\[
\begin{aligned}
1 + 2 + 4 + \cdots + 2^{63} &= 2^{64} - 1 \\
&= 18,446,744,073,709,551 %>% ,615
\end{aligned}
\] Als je het aantal cijfers van dit grote getal telt, zie je dat het neerkomt op 18 triljoen (een 18 met 18 nullen!). Dit kunnen we beter als een macht van 10 schrijven: \(\sim 1.84 \cdot 10^{19}\). In R worden dergelijke grote getallen meestal met e+ aangegeven:
2^64 - 1[1] 1.844674e+19Deze legende van de ontdekking van het schaakspel illustreert de snelheid waarmee exponentiële groei getallen doet oplopen. Wat aanvankelijk klein en bescheiden lijkt, kan snel uitgroeien tot een enorme (onvoorstelbare) hoeveelheid.
De vergissing van de koning was dat hij (zoals veel mensen) niet in kon zien hoe snel verdubbelingen toenemen. We kunnen aan de hand van deze mythe de volgende variabelen, parameters, en aannames formuleren:
Naast deze drie basisingrediënten, is het natuurlijk ook belangrijk om te bepalen wat de hoeveelheid rijst is waar we mee beginnen (hier \(R(0) = 1\)). Dit wordt in de model-wereld de initiële conditie (initial condition) genoemd, oftewel de start waarde van de variabele(n). Vanaf daar gaan we verder rekenen: op het tweede vakje liggen \(R(1) = R(0) \cdot 2\) rijstkorrels, op het derde vakje \(R(2) = R(0) \cdot 2 \cdot 2\) korrels, etc. Het aantal korrels op het 64e vakje, wordt gegeven door 63 verdubbelingen (want let op: het eerste vakje was al bezet!). Dit kunnen we omschrijven met de volgende vergelijking:
\[ R(63) = R(0) \cdot 2^{63} \tag{10.1}\]
Vergelijking 10.1 geeft het aantal korrels op het 64e vakje. Dat is dus nog niet het totaal aantal korrels. Het totaal wordt gegeven door \(R(0) + R(1) + R(2) + \cdots + R(63)\). Deze som is een beetje te lang om volledig op te schrijven, maar we weten dat elke stap de volgende vergelijking wordt toegepast:
\[ R(t+1) = 2\cdot R(t) \tag{10.2}\]
Een vergelijking in de vorm van Vergelijking 10.2 wordt een differentievergelijking genoemd1. Deze differentievergelijking is zo simpel, dat we een eenvoudig R-script kunnen schrijven die deze herhaaldelijk toepast:
R <- 1 # beginaantal rijst (initiële conditie)
# herhaal iets 63 keer met een for-loop
for (i in 1:63) {
R[i+1] <- 2*R[i] # het aantal rijstkorrels in elk vakje op in R
}
print(R[64]) # print het aantal rijskorrels in het 64e vakje[1] 9.223372e+18In de bovenstaande code wordt er steeds een getalletje aan R toegevoegd. \(R\) is dus nu niet meer één getal, maar een steeds langer wordende lijst getallen: \(1, 2, 4, 8, \dots, 2^{63}\) etcetera. Zoals je hebt geleerd heet een dergelijke lijst in R een vector, die we eenvoudig kunnen plotten met R:
# beginaantal rijst
R <- 1
# herhaal iets 63 keer met een for-loop
for (i in 1:63) {
R[i+1] <- R[i]*2 # R in volgende stap is 2*R in deze stap
}
plot(R , type='l', col="seagreen", log="y", lwd=2.5) 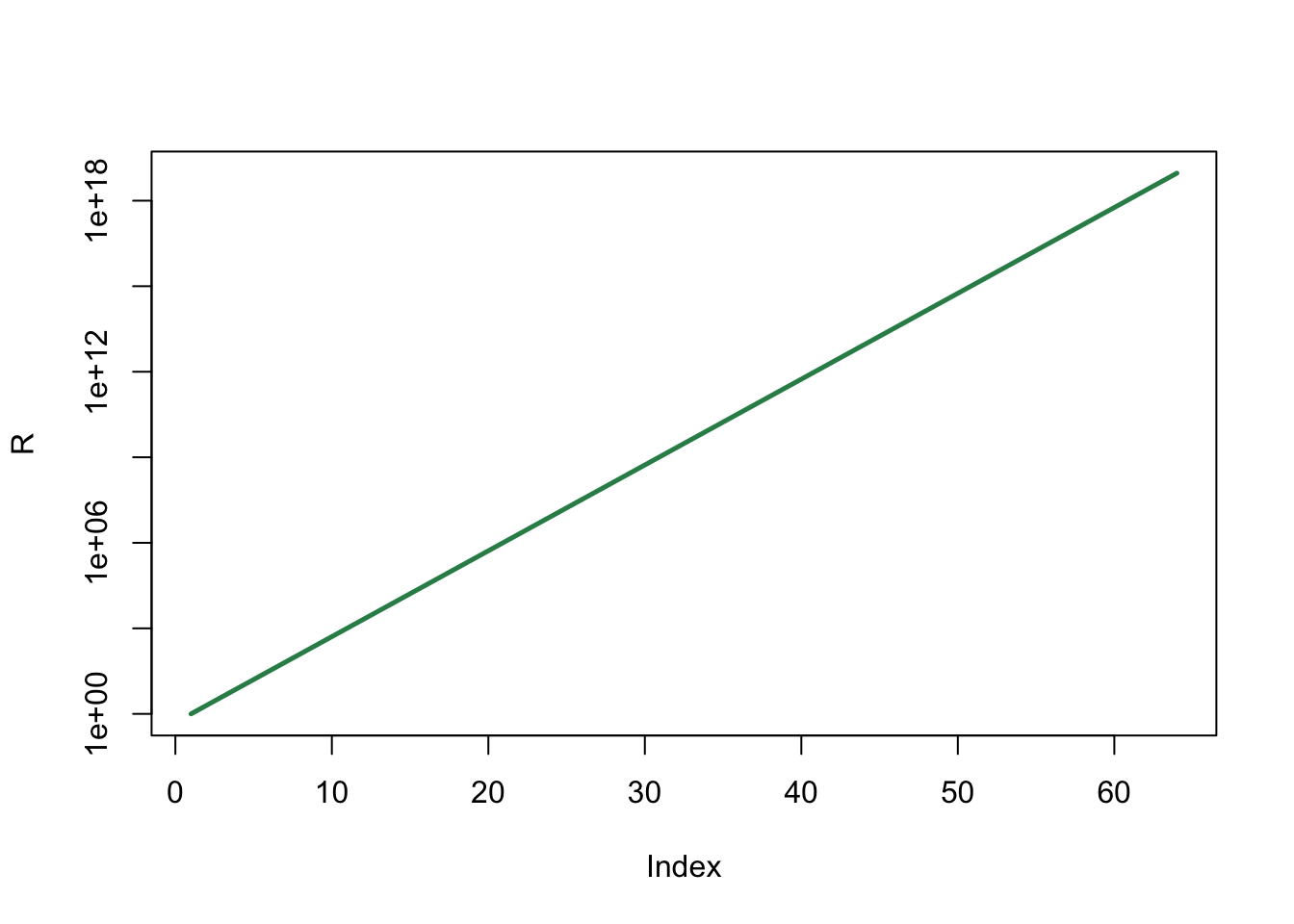
Oefening 10.1 (Een toename van slechts 5%)
We plotten het resultaat van de loop hierboven op een log-lineaire schaal (zie Hoofdstuk 6), zodat we goed kunnen zien of de groei exponentiëel is. Laten we nu aannemen dat de groei van het aantal rijstkorrels niet verdubbelt, maar met 5 procent toeneemt per hokje op het schaakbord:
\[R(t+1) = 1.05 \cdot R(t)\] Pas de R-code hierboven aan om deze nieuwe differentievergelijking door te rekenen.
a. Is er sprake van exponentiele groei?
b. Hoeveel rijstkorrels heb je nu in totaal? (hint: je kan de sum functie gebruiken om de som van een vector in één keer uit te rekenen!)
Hoewel in het dagelijks taalgebruik elke vorm van “snelle groei” als exponentiëel wordt bestempeld, is dit niet correct. Hele snelle groei hoeft niet altijd exponentiëel te zijn, en andersom, kan relatief langzame groei wél exponentiëel zijn (zie ook Oefening 10.1). Er is sprake van exponentiële groei als de percentuele toename constant blijft. In het voorbeeld van de rijst was er een toename van 100% (een verdubbeling) en in Oefening 10.1 een toename van 5%, maar in beide gevallen bleef deze constant. In beide gevallen is er dus sprake van exponentiële groei! Als je wilt controleren of groei exponentiëel is, kun je data altijd plotten op een log-lineaire schaal (log="y"), en kijken of het een rechte lijn vormt.
Nu we weten over de exponentiële groei van rijst, is het hoog tijd om de biologie in te duiken.

Thomas Austin was een Engelse kolonist in Australië, en hield van jagen. Daarom liet hij in de 19e eeuw 24 konijnen vrij in Australië. Binnen tien jaar waren er meer dan honderd miljoen konijnen in Australië, en kon de populatie onmogelijk nog onder controle gehouden worden. Net als bij het voorbeeld van de rijstkorrels, kunnen we een simpele differentievergelijking opschrijven om het aantal konijnen in Autralië te modelleren:
\[\begin{equation} N(t+1) = r \cdot N(t) \end{equation}\]\(N\) staat hier voor het aantal konijnen. Voor simpele populatiemodellen in de ecologie wordt vaak \(N\) (Number of rabbits, deer, plants) gebruikt, maar we hadden de konijnen ook \(K\) (voor konijnen) of \(R\) (voor rabbits) kunnen noemen. Dit heeft verder geen invloed op het model.
In plaats van het getal \(2\) of \(1.05\) in te vullen voor de groeisnelheid, gebruiken we hier \(r\): een vrije parameter waarvan we de waarde nog niet vastzetten. Zodoende kunnen we straks zelf bepalen of we \(r\) op 2, 3, of misschien nog wel hoger moeten zetten om de snelle toename in Australië te kunnen verklaren.
Hoewel de groei van populaties aanvankelijk goed benaderd kan worden met exponentiële groei, kan dit niet tot in het oneindige doorgaan. Zo kan na verloop van tijd het eten opraken (voedsel is de beperkende factor), of kan een graszaadje geen onbezet plekje in het veld meer vinden (ruimte is de beperkende factor). Met andere woorden: hoe meer individuen er aanwezig zijn, hoe minder groei er kan plaatsvinden. Dergelijke effecten noemen we dichtheidseffecten, of dichtheidsafhankelijkheid (density dependency). De bovengenoemde dichtheidseffecten zijn negatief (groei neemt af), maar dichtheidseffecten kunnen ook positief zijn, bijvoorbeeld wanneer individuen van een soort elkaar helpen met groeien, waar we later in Hoofdstuk 13 op terug zullen komen.
We gaan echter eerst onze pijlen richten op negatieve dichtheidseffecten, omdat deze ons kunnen helpen om exponentiële groei om te zetten naar logistische groei. Logistische groei is een vorm van populatiegroei die exponentieel begint, maar uiteindelijk een evenwicht bereikt. Dit geeft een karakteristieke sigmoïde S-curve. Op een log-lineaire schaal begint de groeicurve als een rechte lijn, maar buigt deze uiteindelijk af naar een evenwicht (Figuur 10.2). Deze evenwichtswaarde wordt ook wel de draagkracht of het draagvermogen (carrying capacity) van het systeem genoemd. Als de populatie kleiner is dan dit draagvermogen (er zijn weinig konijnen dus veel eten), dan zal de populatie toenemen. Is de populatie echter groter dan dit draagvermogen (er zijn veel konijnen dus weinig eten), dan zal de populatie alleen maar afnemen. Ergens daartussenin zal dus een evenwichtsituatie liggen.
In de opgaven gaan we rekenen aan de konijnenpopulatie in Australië en onze eerste poging doen om de populatie een stabiel evenwicht te laten bereiken.
x<- 24
for(i in 1:70){
x[i+1] <- x[i] * 1.2 * (1-(x[i]/10^5))
}
plot(x, xlab="Tijd", ylab="Aantal", lwd=2.5, type='l', col='seagreen')
plot(x, xlab="Tijd", ylab="Aantal", lwd=2.5, type='l', col='seagreen',log="y")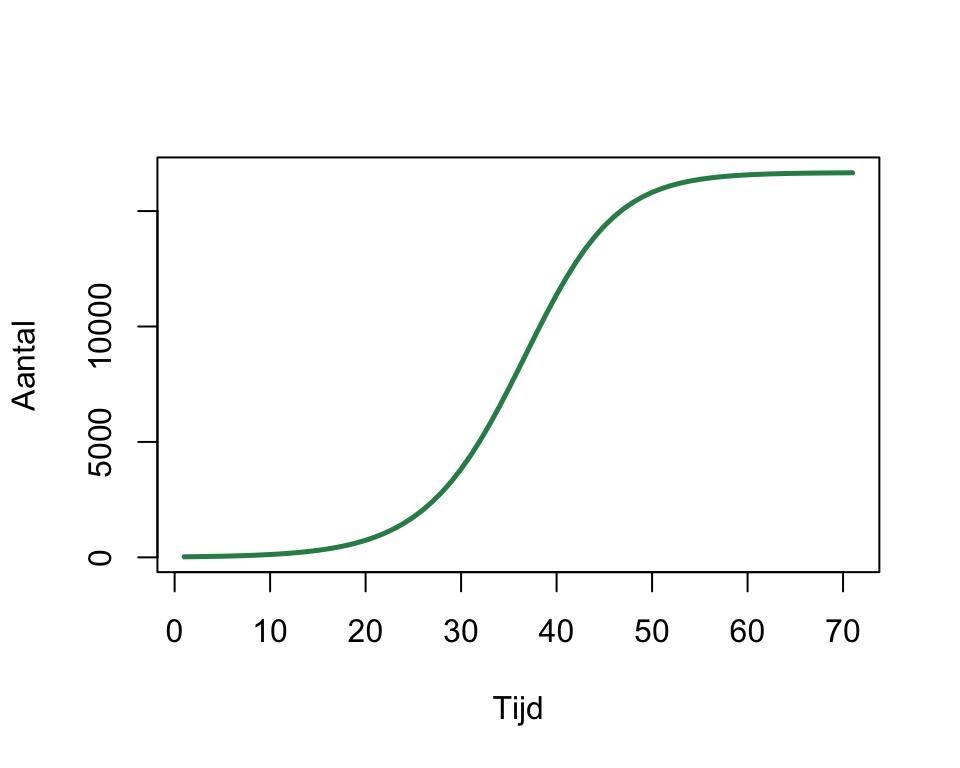
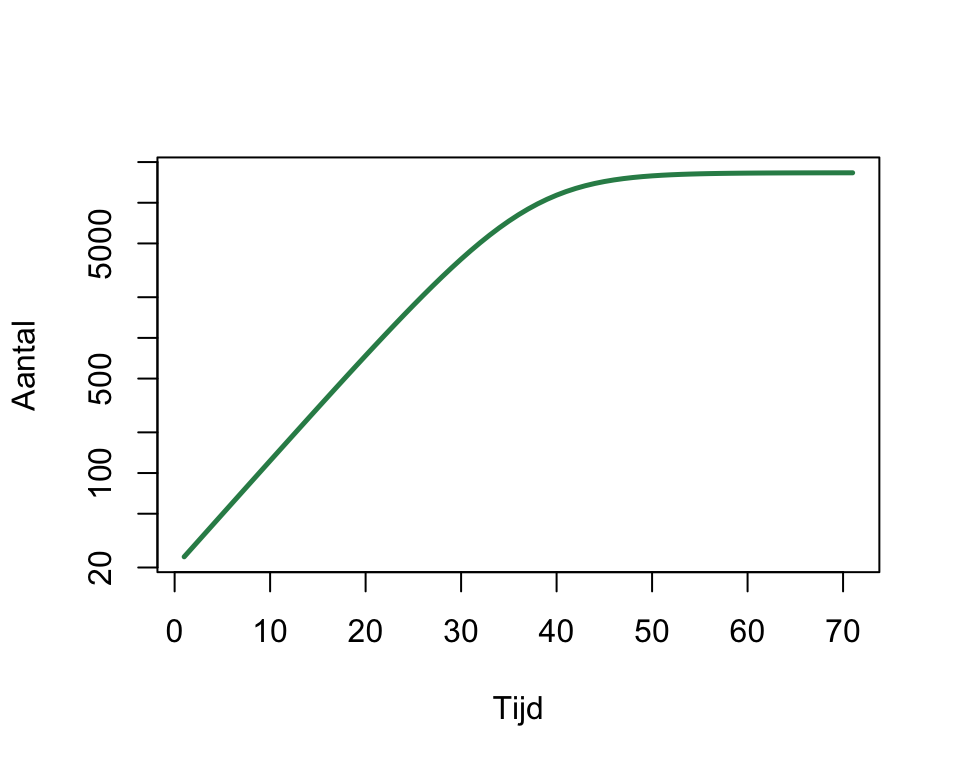
Oefening 10.2 (Konijnen in Australië)
Als een biologische populatie zich ergens vestigt, kan deze aanvankelijk enorm snel groeien. Voorbeelden hiervan zijn een virus dat zich verspreidt in een nieuwe gastheer, een bacteriële populatie in een voedselrijk medium, of zoals in dit hoofdstuk omschreven, de konijnenpopulatie in Australië:
\[ N(t+1) = r \cdot N(t) \]
Exponentiële groei is zo simpel dat het gemakkelijk te simuleren is met de computer, bijvoorbeeld in R. Neem de volgende code over in Rstudio:
# definieren van begin aantal konijnen
N <- 24
# Verdubbel het aantal konijnen 10 keer
for (t in 1:10){
N <- 2*N
}Het aantal konijnen na 20 stappen is gelijk aan 25165824.Om beter bij te kunnen houden hoeveel konijnen er zijn na elke stap, kunnen we het aantal konijnen bijhouden in een lijst, waar we elke herhaling het aantal konijnen op dat tijdpunt aan toevoegen. Ook kunnen we de groeisnelheid in een parameter \(r\) opslaan, zodat we deze gemakkelijk kunnen aanpassen:
# Stap 1: Stel begin-aantal konijnen in
N <- 24
r <- 2
# Stap 2: Vermeerder het aantal konijnen 30 keer
for (t in 1:30){
N[t+1] <- r*N[t]
}
# Stap 3: Plot het resultaat
plot(N, type='l')Hoewel het aantal konijnen in Australië aanvankelijk exponentieel groeide, is er uiteindelijk een evenwicht bereikt bij ongeveer 500 miljoen konijnen. Kennelijk was er bij dit aantal een balans tussen geboorte en sterfte van konijnen. Laten we onze vergelijking veranderen in groei door een geboorte-term (\(b\), birth) en een sterfte-term (\(d\), death):
\[ N(t+1) = b \cdot N(t) - d \cdot N(t) \] De nieuwe R-simulatie wordt dan:
# Stap 1: Stel begin-aantal konijnen in
N <- 24
b <- 2
d <- 0.1
# Stap 2: Verander het aantal konijnen 30 keer met de gegeven birth en death rates
for (t in 1:30){
N[t+1] <- b*N[t] - d*N[t]
}
# Stap 3: Plot het resultaat
plot(N, type='l')We kunnen onze nieuwe vergelijking ook herschrijven als: \[ N(t+1) = (b-d) \cdot N(t) \]
Als we dan aannemen dat de eerder genoemde intrinstieke groei (\(r\)) gelijk is aan \(b-d\), zijn we terug bij af:
\[ N(t+1) = r \cdot N(t) \]
We hebben dus niet bereikt wat we wilden: dat er bij lage aantallen konijnen groei kan zijn, maar bij hoge aantallen niet. Om dit toch voor elkaar te krijgen, kunnen we de sterfte-term kwadrateren:
\[ N(t+1) = b \cdot N(t) - d \cdot N(t)^2 \]
Neem aan dat \(b=2\), \(d=0.001\), en dat we beginnen met 24 konijnen (\(N=24\)). Als je deze drie waarden gebruikt, wat zijn dan de numerieke waarden van de geboorte- en sterfteterm, en numerieke waarde van de volledige vergelijking?
Voer dezelfde berekening uit voor 1000 konijnen (voor dezelfde waarden van \(b\) en \(d\))
De onderstaande code gebruikt de bovengenoemde parameters \(b=2\) en \(d=0.001\).
# Stap 1: Stel begin-aantal konijnen in
N <- 24
b <- 2
d <- 0.001
# Stap 2: Verander het aantal konijnen 30 keer met de gegeven birth/death rates
for (t in 1:30){
N[t+1] <- b*N[t] - d*N[t]^2
}
# Stap 3: Plot het resultaat
plot(N, type='l')De populatie bereikt een stabiel evenwicht wanneer \(N(t+1)\) gelijk is aan \(N(t)\). Omdat beide vormen van \(N\) nu gelijk zijn, kunnen we de differentievergelijking opschrijven als:
\[ N = b N - d N^2 \]
Om de populaties bij 500 miljoen te laten stabiliseren, moeten we \(d\) dus nog veel kleiner maken: \({1 \over 5 \cdot 10^8} = 2^{-9}\). In R schrijven we dan d <- 2e-9.
Gebruik de bovengenoemde death rate, en plot het aantal konijnen op een log-lineaire schaal (voeg log="y" toe aan de laatste regel). Groeit de populatie in de eerste jaren (bij benadering) exponentieel? Groeit de populatie in de laatste jaren exponentieel?
Neem aan dat elke tijdstap 1 jaar is. Hoeveel konijnen zijn er in je nieuwe model na 10 jaar? (let op: N[1] is tijdstap 0, niet tijdstap 1). Wat is er vreemd aan deze hoeveelheid?
De konijnenpopulatie bereikte naar schatting binnen 10 jaar een populatiegrootte van meer dan honderd miljoen. Als we dit vergelijken met onze eigen resultaten uit de bovenstaande vraag, groeit onze populatie dus te langzaam. Misschien kunnen we de birthrate (\(b\)) verhogen zodat ons model overeenkomt met de data. Neem aan dat \(b=3\). Gaat de konijnenpopulatie naar een evenwicht?
Heb je dit keer genoeg konijnen binnen 10 jaar om het scenario in Australië te evenaren?
Met een birthrate van \(b=3.7\) komen we aardig in de buurt van de geobserveerde groeisnelheid tijdens de eerste jaren in Australië. Wat gebeurt er als je deze waarde gebruikt?
Oefening 10.3 (Miniatuur Australië)
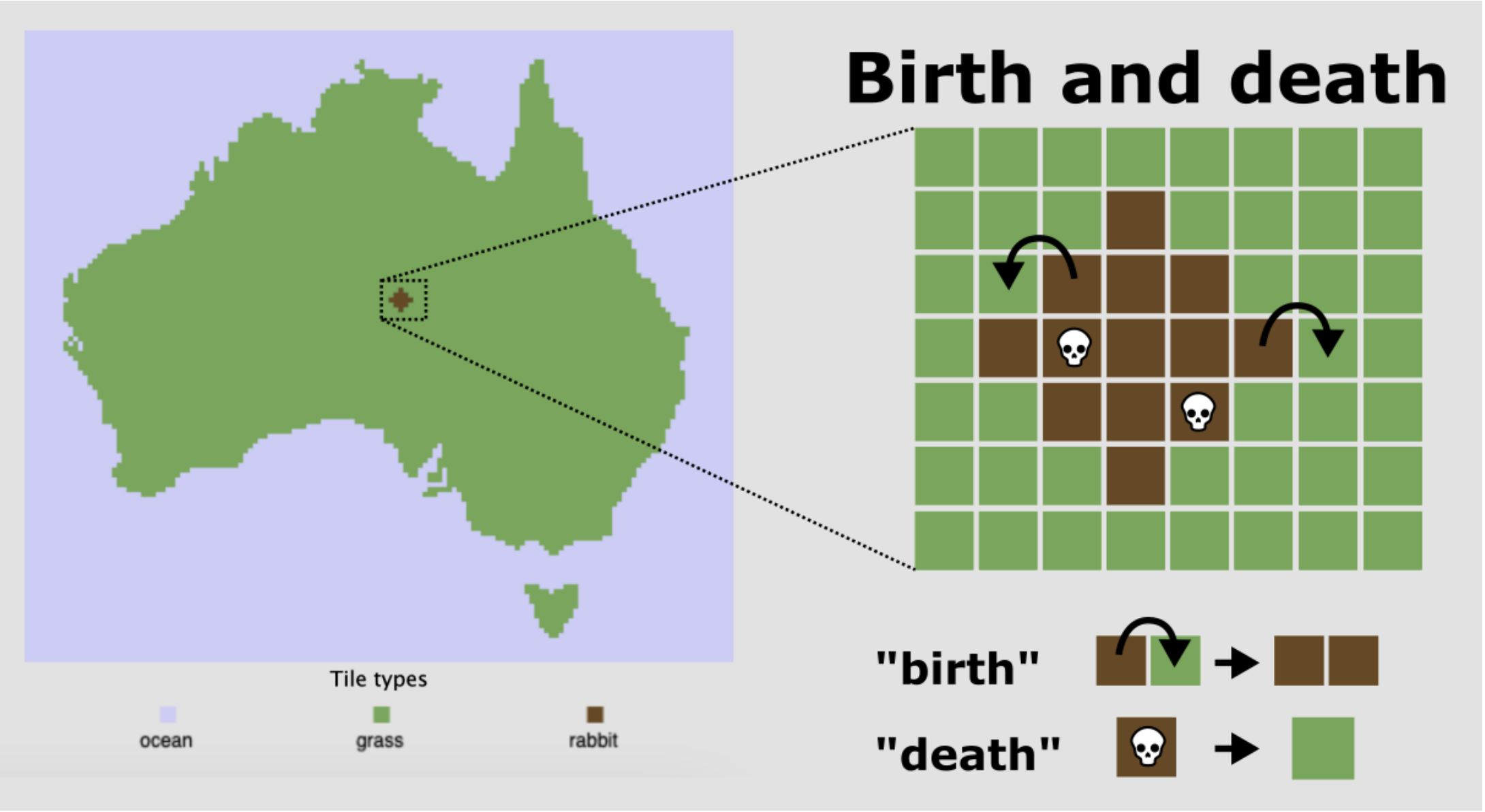
Laten we de konijnenpopulatie uit de vorige opgave ook in een ander type model bekijken. Hiervoor simuleren we een “miniatuur Australië” (zie Figuur 10.3). Laten we Australië in drie types hokjes opdelen: grashokjes (groen) waarop konijnen kunnen voortplanten, konijnhokjes (bruin), en oceaanhokjes (blauw). We nemen voor het gemak aan dat er geen woestijn-hokjes zijn, wat betekent dat konijnen overal in Australië kunnen voortplanten. Elke tijdstap kunnen konijnen zich vermenigvuldigen door een naastgelegen grashokje over te nemen. Deze “geboortekans” zetten we vast op 80%, en ondervindt géén dichtheidsafhankelijkheid. Konijnen kunnen ook sterven met een vaste kans van 1%, waardoor een bruin hokje weer groen wordt. Als laatste nemen we voor het gemak aan dat konijnen niet bewegen.
Lees de bovenstaande modelomschrijving zorgvuldig door. Verwacht je exponentiële groei? Waarom wel/niet?
Verwacht je dat er een draagvermogen (carrying capacity) zal zijn? Bespreek je antwoord op a en b met je studentassistent.2
Een interactieve versie van deze simulatie zie je hieronder. Start de simulatie en bekijk de grafieken. Had je de vorige vragen juist beantwoord?
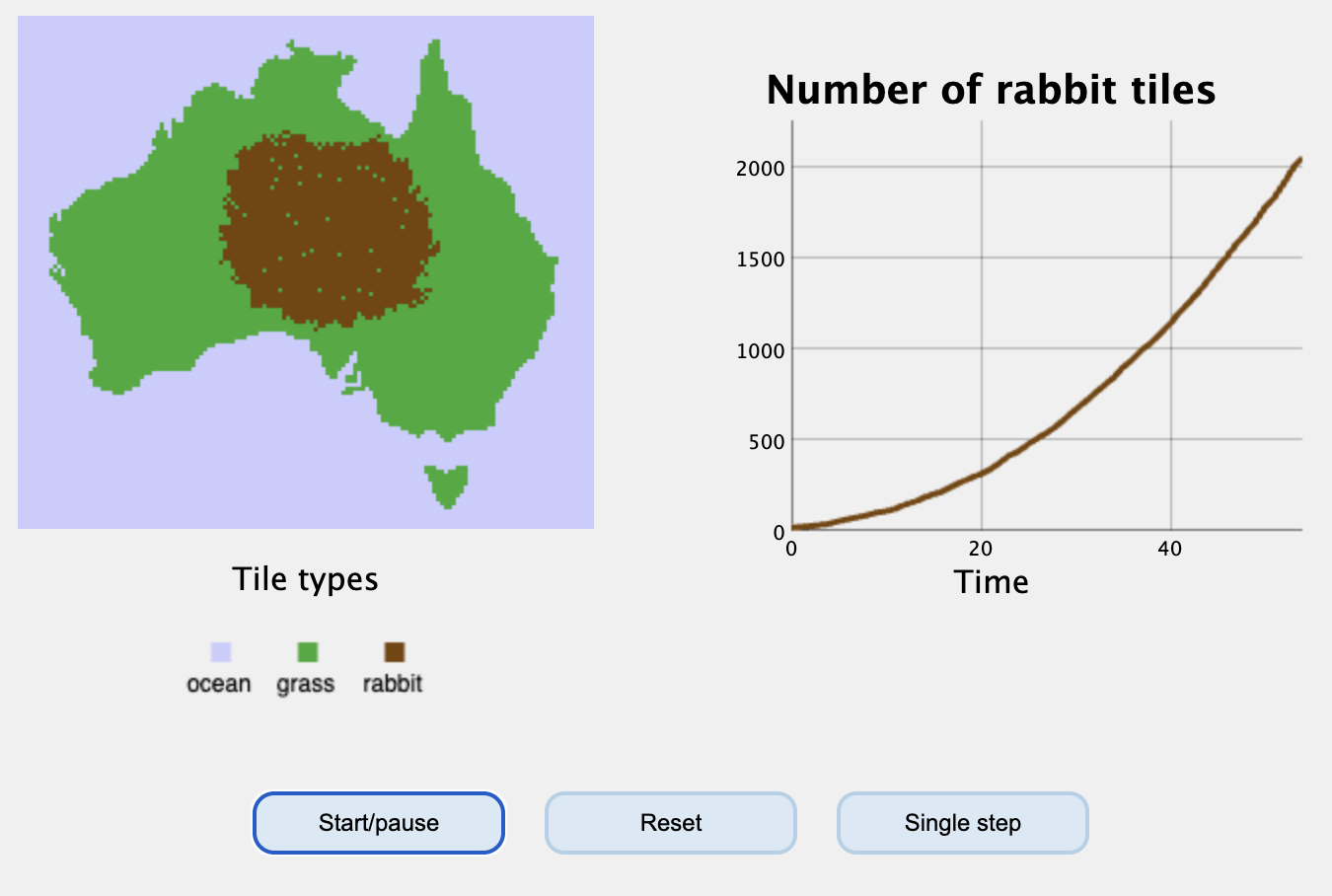
Omdat dit model willekeur bevat (geboorte en sterfte worden met kansen bepaald), zijn populatiegroottes niet elke keer hetzelfde en is de groei nooit perfect exponentieel. We kunnen wél testen of de groei bij benadering exponentieel is. Daarvoor tellen we bijvoorbeeld elke 10 tijdstappen het aantal konijnen, wat we in een R-vector kunnen stoppen: konijnen <- c(13, 108, 311, 665, 1137, 1773, 2549, 3384). Dan kunnen we met plot(konijnen, type='l') kunnen we deze waarden plotten. Bepaal of deze groei exponentieel is.
De simulatie bereikt een draagvermogen van ongeveer 8000 konijnen, wat veel minder is dan honderden miljoenen. We zouden een veel groter Australië kunnen simuleren. Ook kunnen we de konijnen een beetje rond laten lopen in dat grotere Australië, zie bijvoorbeeld deze versie. Groeit de populatie nu wel exponentieel?
Door Australië groter te maken werd de simulatie veel langzamer, want er moeten veel meer hokjes berekend worden. In plaats van met een heel groot Australië te werken, kunnen we ook definiëren dat elk hokje niet 1 konijn is, maar een lokale populatie konijnen. Wat zou dit betekenen voor de interpretatie van de geboorte- en de sterftekans?
| Nederlands | Engels | Beschrijving |
|---|---|---|
| Initiële conditie | Initial condition | De begin-toestand van het model. In simpele wiskundige modellen is dit vaak een aantal (zoals de begin-hoeveelheid rijst in dit hoofdstuk). Bij andere modellen (uit latere hoofdstukken) kan de begin-toestand ook een kleur of een patroon zijn. |
| Differentievergelijking | Difference equation / Map | Een wiskundige formule die de relatie beschrijft tussen opeenvolgende waarden van een variabele in discrete tijdstappen. |
| Exponentiële groei | Exponential growth | Groei waarbij het percentage van toename constant blijft. |
| Logistische groei | Logistic growth | Groei die exponentiëel begint, maar waarbij het (eco)systeem of de populatie uiteindelijk een evenwicht bereikt. |
| Draagvermogen | Carrying capacity | Het maximale aantal individuen (of de maximale concentratie) dat een systeem in evenwicht kan ondersteunen. |
Niet te verwarren met de differentiaalvergelijking, waar we in het volgende hoofdstuk over gaan leren!↩︎
Verwachtingsvragen zijn vaak open, en er is niet een eenduidig “goed” of “fout” antwoord. Het is belangrijk dat je je verwachtingen onderbouwt, en dat je deze verwachtingen bespreekt met anderen, zodat je samen tot een beter begrip van de stof komt!↩︎