Nu je de basis van kansrekenen onder de knie hebt, keren we terug naar de statistiek. Laten we even terugpakken waar we gebleven waren.
In Hoofdstuk 21 hebben we het gehad over schattingen. Het doel van veel onderzoeken is om een bepaalde grootheid of populatieparameter te schatten. We hebben benadrukt dat schattingen onzeker zijn. Bij schattingen op basis van steekproeven komt dat door steekproefvariabiliteit en mogelijk door bias in de samenstelling van de steekproef. Bij metingen spelen systematische en toevallige meetfouten een rol. Daarom is het belangrijk om je bij elk getal dat je tegenkomt af te vragen hoe precies die schatting is.
Een getal zonder indicatie van de nauwkeurigheid en precisie is nutteloos.
In dit hoofdstuk leer je voor een specifieke situatie hoe je die onzekerheid kwantificeert. We doen dit door betrouwbaarheidsintervallen uit te rekenen.
24.1 Leerdoelen
Na het bestuderen van dit hoofdstuk kun je:
uitleggen wat betrouwbaarheidsintervallen zijn en ze correct interpreteren;
betrouwbaarheidsintervallen berekenen voor het populatiegemiddelde van een continue variabele;
de aannames van het Normale Model benoemen, uitleggen waarom die belangrijk zijn, en afwijkingen van die aannames herkennen in praktische situaties;
QQ-plots interpreteren om te beoordelen of de aanname van normaliteit in een dataset redelijk is;
de relatie uitleggen tussen onzekerheid in schattingen en de spreiding in de steekproevenverdeling van de schatter;
de standaardfout van het steekproefgemiddelde berekenen en interpreteren;
uitleggen hoe de breedte van een 95%-betrouwbaarheidsinterval afhangt van de steekproefgrootte en de spreiding in de populatie;
24.2 Betrouwbaarheidsintervallen
Dit is het idee: we zullen bij het maken van een schatting niet alleen één getal berekenen (een zogenaamde puntschatting) maar ook een interval om dat punt dat aangeeft wat de onzekerheid in die schatting is. Dat interval heet een betrouwbaarheidsinterval (BHI, confidence interval). Vaak wordt een 95%-betrouwbaarheidsinterval gebruikt. Dat is een interval dat zo berekend wordt dat de ware waarde van de ware parameter er in 95% van de gevallen binnen ligt. Het BHI geeft dus een indicatie van de precisie van de schatting. Een smal interval betekent dat de schatting precies is, een breed interval dat de schatting onzeker is.
BelangrijkWat is een BHI?
Een 95%-BHI is een interval rondom een puntschatting, berekend op zo’n manier dat in 95% van de gevallen de ware parameter er binnen ligt.
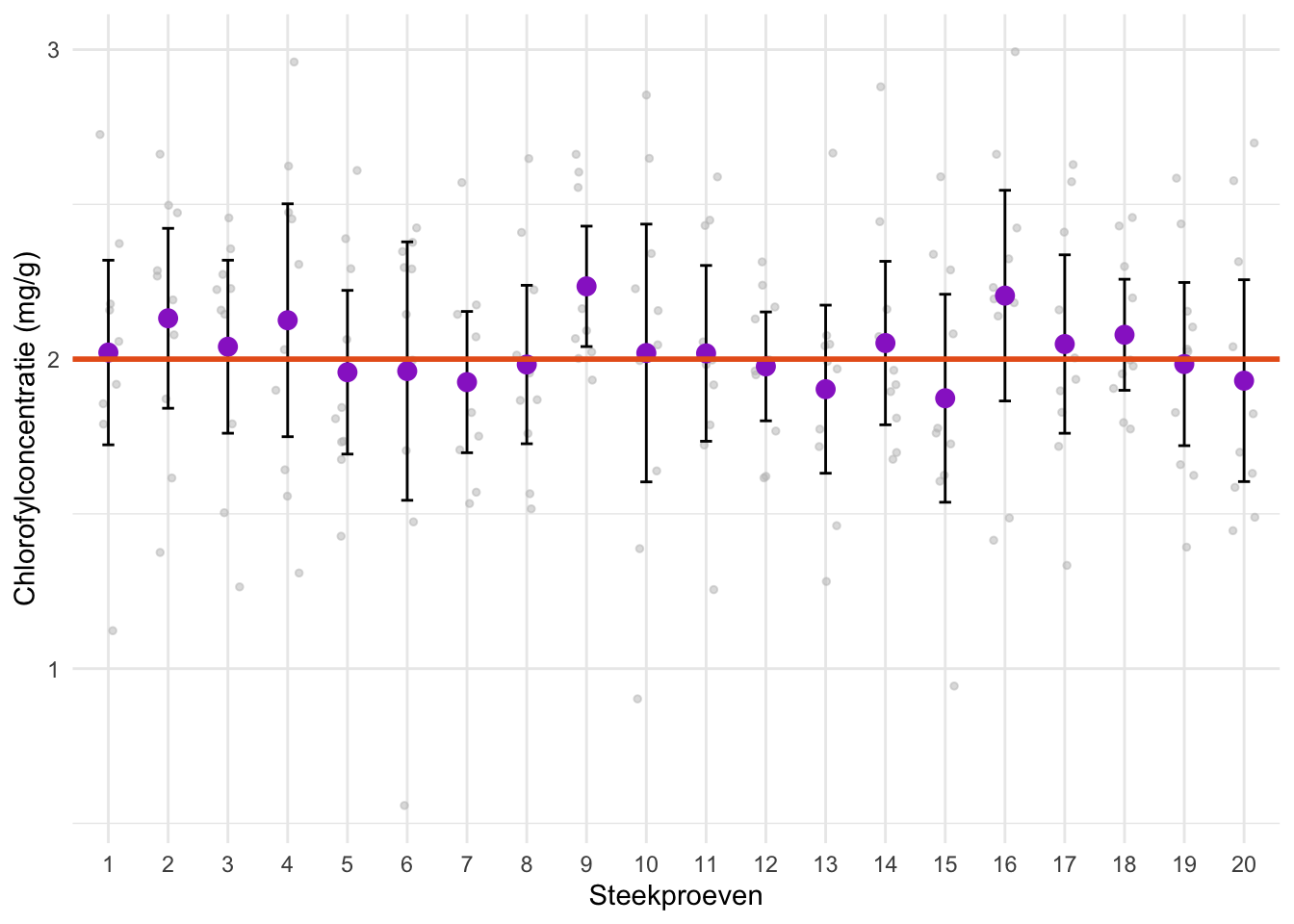
We maken dit concreet met een voorbeeld. Stel dat verschillende onderzoekers geïnteresseerd zijn in dezelfde parameter: de gemiddelde chlorofylconcentratie in de bladeren van tarweplanten. Iedere onderzoeker neemt een steekproef van 10 planten en meet daarvan de chlorofylconcentratie.
Neem aan dat het werkelijke populatiegemiddelde (de populatieparameter) gelijk is aan 2,0 mg per gram vers bladgewicht. De onderzoekers weten dat niet; zij hebben alleen toegang tot hun eigen steekproef. Iedere onderzoeker berekent de gemiddelde chlorofylconcentratie van de eigen steekproef. Dat is de puntschatting. Door steekproevenvariabiliteit vindt iedere onderzoeker een andere puntschatting, die over het algemeen zal afwijken van het ware populatiegemiddelde.
Iedere onderzoeker berekent ook een 95%-BHI. Figuur 24.1 laat zien wat het resultaat zou kunnen zijn. De waarnemingen van alle 20 steekproeven zijn in grijs geplot; de gemiddelden van alle steekproeven (de puntschattingen) als paarse punten; en de ware populatieparameter als een oranje horizontale lijn. Zwarte verticale lijnen geven de BHI’s aan.
Ieder 95%-BHI bevat met 95% zekerheid het ware gemiddelde. Iedere onderzoeker kan dus aan zijn eigen BHI aflezen hoe ver zijn puntschatting redelijkerwijs kan afwijken van het ware gemiddelde.
Helaas zal 5% van de 95%-BHI’s het gemiddelde niet bevatten. Bij 20 herhalingen komt dat gemiddeld één keer voor. In dit voorbeeld heeft onderzoeker 9 pech: de oranje lijn loopt niet door zijn BHI. Hoewel zijn onderzoek net zo zorgvuldig is uitgevoerd als dat van de anderen, geeft zijn puntschatting en BHI een verkeerde indruk.
Code
# Parameters voor de populatieverdelingwaar_gemiddelde <-2.0waar_sd <-0.4aantal_steekproeven <-20steekproefgrootte <-10# Aantal datapunten per steekproef# Genereer 20 aselecte steekproevenset.seed(125) # Voor reproduceerbaarheidsteekproeven <-replicate( aantal_steekproeven,rnorm(steekproefgrootte, mean = waar_gemiddelde, sd = waar_sd),simplify =FALSE)# Maak een data frame voor de individuele datapuntendatapunten <-data.frame(steekproef_id =rep(1:aantal_steekproeven, each = steekproefgrootte),waarde =unlist(steekproeven))# Bereken gemiddelden en 95%-betrouwbaarheidsintervallen met t.test()bhi_data <-data.frame(steekproef_id =1:aantal_steekproeven,gemiddelde =sapply(steekproeven, mean),ondergrens =sapply(steekproeven, function(x) t.test(x)$conf.int[1]),bovengrens =sapply(steekproeven, function(x) t.test(x)$conf.int[2]))# Plot de dataggplot() +# Jitterplot voor de individuele datapuntengeom_jitter(data = datapunten,aes(x =factor(steekproef_id), y = waarde),color ="gray",size =1,width =0.2,alpha =0.5 ) +# Foutbalken voor de betrouwbaarheidsintervallengeom_errorbar(data = bhi_data,aes(x =factor(steekproef_id), ymin = ondergrens, ymax = bovengrens),width =0.2 ) +# Punten voor de steekproefgemiddeldengeom_point(data = bhi_data,aes(x =factor(steekproef_id), y = gemiddelde),color = puntkleur2,size =3 ) +# Horizontale lijn voor het ware populatiegemiddeldegeom_hline(yintercept = waar_gemiddelde,color = lijnkleur0,linetype ="solid",linewidth =1 ) +labs(x ="Steekproeven",y ="Chlorofylconcentratie (mg/g)",title =NULL ) +theme_minimal() +theme(axis.text.x =element_text(angle =0, hjust =0.5))
Figuur 24.1: Illustratie van het concept van een betrouwbaarheidsinterval (BHI). Getoond worden de 95%-BHI’s van twintig onderzoekers die hetzelfde onderzoek hebben uitgevoerd naar de gemiddelde chlorofylconcentratie van de bladeren van tarweplanten. De ruwe datapunten zijn in lichtgrijs weergegeven, en de oranje lijn geeft het ware gemiddelde aan – de populatieparameter. De paarse punten zijn de steekproefgemiddelden (de puntschatters), en de zwarte lijnen geven de 95%-BHI’s aan.
In dit hoofdstuk zullen we zien hoe je een betrouwbaarheidsinterval kunt berekenen voor het populatiegemiddelde van een continue variabele. Je zult uiteindelijk zien dat de formule daarvoor helemaal niet moeilijk is. Maar, het is belangrijk dat je ook begrijpt waarom de formule werkt, en onder welke aannames. Om dat voor elkaar te krijgen zullen we wat dieper de theorie in moeten duiken.
Oefening 24.1 (Bloeddrukverlagende medicijnen)
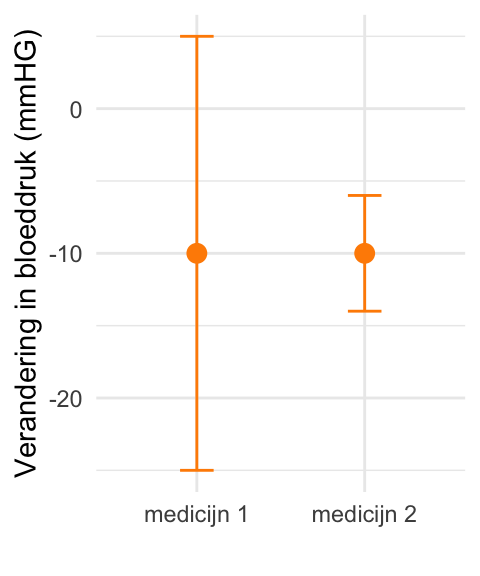
Een farmaceutisch bedrijf doet onderzoek naar het effect van twee nieuwe medicijnen op de systolische bloeddruk.
Hieronder zijn voor beide medicijnen het gemiddelde effect geplot (oranje datapunten). De oranje lijnen geven de 95%-betrouwbaarheidsintervallen aan.
Geven deze gegevens de indruk dat medicijn 1 gemiddeld genomen een effect heeft op de bloeddruk?
Kun je uitsluiten dat medicijn 1 gemiddeld genomen een effect heeft op de bloeddruk?
Geven deze gegevens een indicatie dat medicijn 2 een effect heeft op de bloeddruk?
Kan het zo zijn dat medicijn 2 gemiddeld genomen géén effect heeft op de bloeddruk?
Oefening 24.2 (Waarom 95%?)
Waarom berekenen we meestal een 95%-betrouwbaarheidsinterval, en niet, zeg, een 50%-betrouwbaarheidsinterval?
24.3 Het interpreteren van onzekere gegevens vereist een statistisch model
Om conclusies te trekken uit onzekere gegevens maken we altijd, bewust of onbewust, gebruik van voorkennis en aannames. Dat kan ook niet anders: de conclusies die je kunt trekken hangen af van hoe de gegevens tot stand zijn gekomen. Zo is het onmogelijk om iets te concluderen uit de chlorofylmetingen hierboven zonder iets te veronderstellen over de nauwkeurigheid van de meetmethode of de eigenschappen van de steekproef.
Daarom is iedere statistische analyse gebaseerd op een model. Bij Biologische Modellen heb je geleerd dat een model een vereenvoudigde beschrijving is van een onderdeel van de werkelijkheid, gebaseerd op aannames. Daar gingen de aannames vaak over de manier waarop variabelen elkaars dynamiek beïnvloeden. In de statistiek gaan de aannames over de kansprocessen die ten grondslag liggen aan onze onzekere gegevens — zoals de manier waarop de steekproef is uitgevoerd of de aard van de meetfouten. Zo’n model noemen we een statistisch model: een kansmodel dat gebruikt wordt om onzekere gegevens te interpreteren.
We maken dit nu concreet.
24.4 Het Normale Model voor eenvoudige aselecte steekproeven uit grote populaties
We richten ons op de volgende situatie. We zijn geïnteresseerd in het gemiddelde van een numerieke variabele \(X\) in een bepaalde populatie. We noemen die populatieparameter \(\mu_X\). Om meer over die parameter te weten te komen, nemen we een steekproef van \(n\) eenheden uit de populatie.
Het idee is nu dat we het nemen van een steekproef gaan beschouwen als een kansexperiment, en iedere waarneming binnen de steekproef als een kansvariabele. In de statistiek wordt daarbij vaak gebruik gemaakt van het volgende kansmodel, dat we in dit boek het Normale Model zullen noemen.
BelangrijkDefinitie: Het Normale Model van steekproeven.
Het Normale Model is gebaseerd op de volgende aannames:
De variabele is normaal verdeeld in de populatie. We zagen eerder dat veel variabelen een klokvormige verdeling hebben. Dit model gaat ervan uit dat de verdeling benaderd kan worden door een normale verdeling.
Iedere waarde \(X_i\) van de steekproef is onafhankelijk uit deze normale verdeling getrokken. Dit is een redelijke benadering als we in werkelijkheid een eenvoudige aselecte steekproef uitvoeren en bovendien de populatie veel groter is dan de steekproef, zodat de populatie niet wezenlijk verandert als we al een deel van onze steekproef hebben gekozen.
Hoewel de twee aannames van het Normale Model bij de meeste toepassingen niet exact waar zijn, zijn ze vaak een goede benadering. Maar, voor sommige situaties is dit model niet geschikt; we komen hier in Paragraaf 24.10.5 op terug.
24.5 De kansverdeling van het steekproefgemiddelde
Goed — laten we de eigenschappen van steekproeven verder bestuderen, aangenomen dat het Normale Model van toepassing is.
Om \(\mu_X\) te schatten berekenen we allereerst het gemiddelde van de steekproef: \[
\overline{X} = \frac{\sum_{i=1}^n X_i}{n}.
\tag{24.1}\] Het is belangrijk te beseffen dat dit steekproefgemiddelde \(\overline{X}\) een kansvariabele is. Want als je meerdere keren op dezelfde manier een steekproef uitvoert en steeds het steekproefgemiddelde uitrekent, vind je niet steeds dezelfde waarde. Kunnen we iets zeggen over hoe onzekerheid in \(\overline{X}\)?
Om daar meer inzicht in te krijgen gaan we het nemen van steekproeven eerst bestuderen met simuleren.
Simulaties van het Normale Model
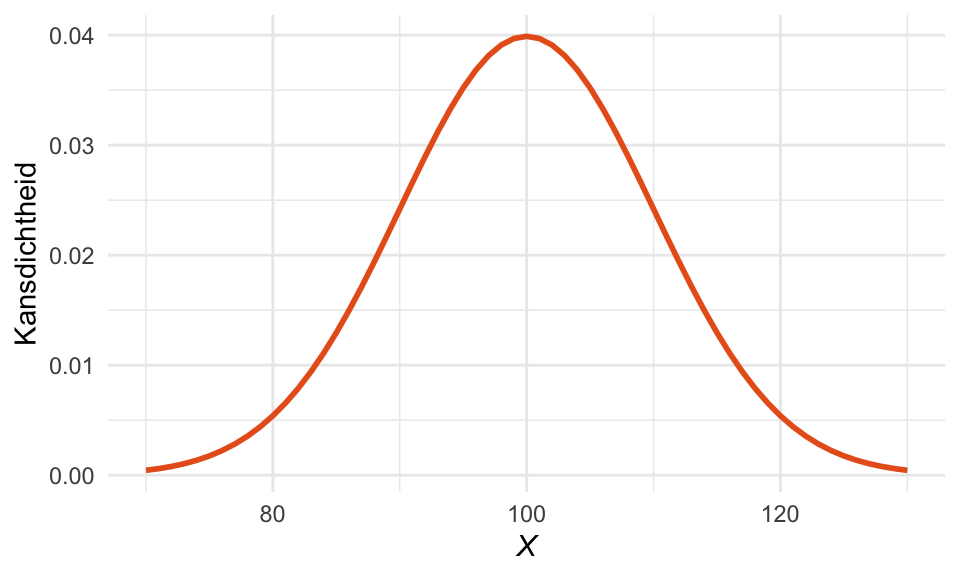
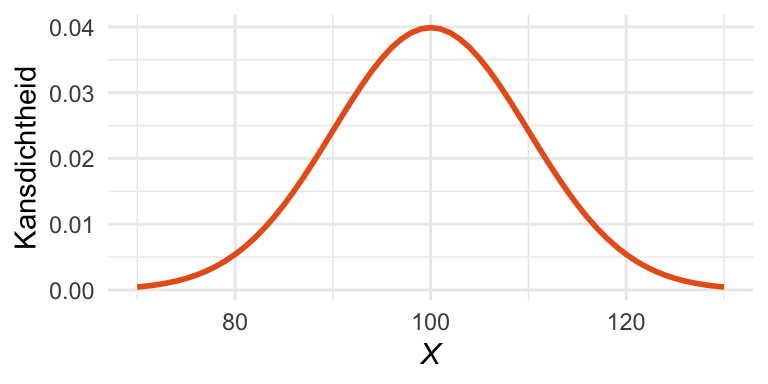
Stel dat het populatiegemiddelde gelijk is aan \(\mu_X = 100\), met standaarddeviatie \(\sigma_{X} = 10\). Dan ziet de verdeling van de populatie er zo uit:
Code
# Parameters voor de normale verdelingmu <-100# Gemiddeldesigma <-10# Standaarddeviatiexmin <- mu -3* sigmaxmax <- mu +3* sigmapopulatie <-normaalCurve(mu, sigma, expression(italic(X)), labels ="geen")populatie
Figuur 24.2: Een normaalverdeelde populatie met gemiddelde 100 en standaarddeviatie 10.
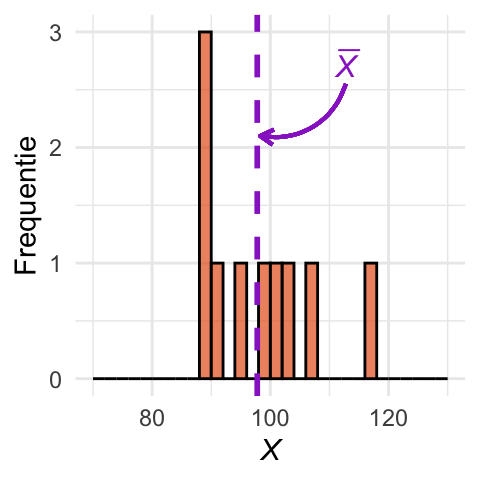
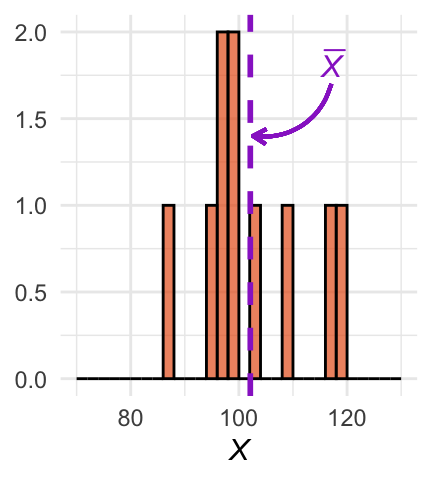
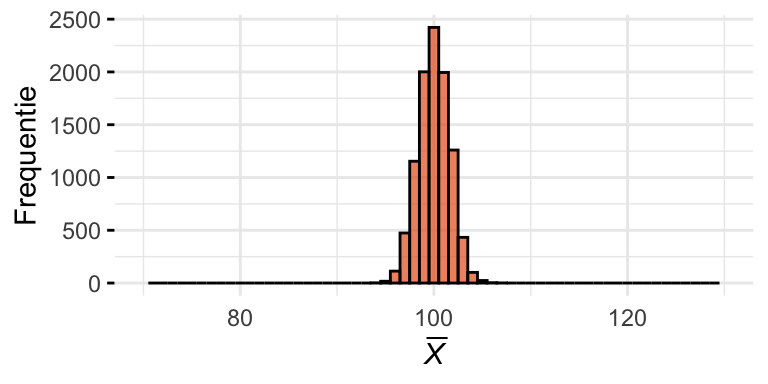
In de praktijk weten we de waardes van \(\mu_X\) en \(\sigma_{X}\) niet en hebben we alleen toegang tot een steekproef uit de populatie. Daarom trekken we als voorbeeld \(n = 10\) eenheden uit de populatie. In Figuur 24.3 (a) zijn de resultaten in een histogram weergegeven. In de figuur is ook het gemiddelde \(\overline{X}\) van de steekproef aangegeven met een verticale lijn.
Code
set.seed(130) # Voor reproduceerbaarheid# Stel parameters insteekproef_grootte <-10staafbreedte <-2# Genereer drie steekproeven van grootte 10steekproeven <-lapply(1:3, function(i) rnorm(steekproef_grootte, mean = mu, sd = sigma))# Bereken steekproefgemiddeldengemiddelden <-lapply(steekproeven, mean)# Maak histogrammenhistogrammen <-lapply(1:3, function(i) { s <- steekproeven[[i]] p <-maakHistogram(data.frame(x = s), "x", expression(italic(X)), staafbreedte, c(xmin, xmax)) +gemiddeldeLijn(s, gemiddelden[[i]], sigma, staafbreedte, c(xmin, xmax))if (i >1) p <- p +labs(y =NULL) p})# Toon het eerste histogramhistogrammen[[1]]histogrammen[[2]]histogrammen[[3]]
(a) Histogram van steekproef 1.
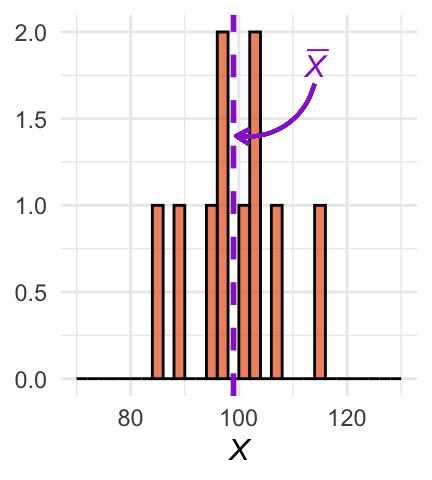
(b) Histogram van steekproef 2.
(c) Histogram van steekproef 3.
Figuur 24.3: Histogrammen van drie steekproeven van steeds \(n = 10\) eenheden. Paarse verticale lijnen geven het steekproefgemiddelde aan.
Het steekproefgemiddelde hangt natuurlijk af van de steekproef die we getrokken hebben. Als we opnieuw een steekproef uitvoeren uit dezelfde populatie vinden we andere waarden en dus ook een ander gemiddelde. Figuur 24.3 (b) en Figuur 24.3 (c) laten twee andere steekproeven zien, ieder met hun eigen \(\overline{X}\).
Omdat iedere steekproef een andere waarde van \(\overline{X}\) geeft en dus ook een andere schatting voor \(\mu_X\), rijst de vraag: Hoe ver ligt \(\overline{X}\) typisch van \(\mu_X\) af? Als \(\overline{X}\) bij een steekproef van \(n = 10\) typisch heel ver van \(\mu_X\) afligt, dan is een schatting op basis van zo’n steekproef blijkbaar erg onzeker. Als \(\overline{X}\) typisch juist heel dicht bij \(\mu_X\) ligt, dan is die schatting blijkbaar juist heel precies en nauwkeurig.
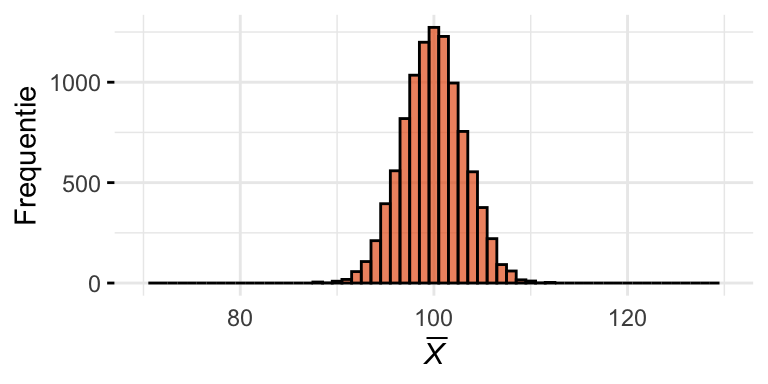
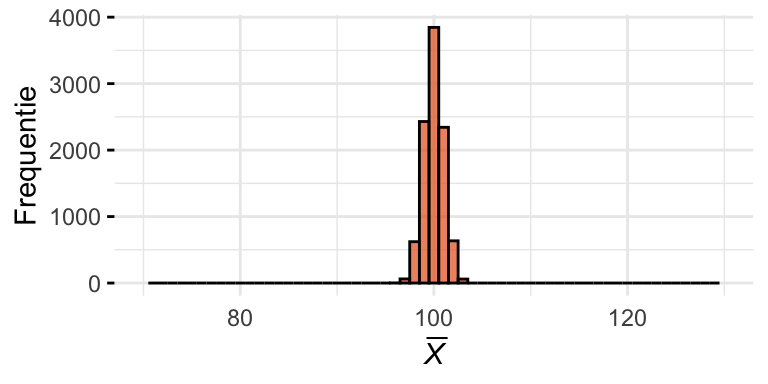
Om daar een beeld van te krijgen trekken we nu heel vaak opnieuw een steekproef met \(n = 10\) en berekenen telkens \(\overline{X}\). (Dit is een gedachtenexperiment; in werkelijkheid zouden we dit nooit doen.) Vervolgens tekenen we een histogram van alle steekproefgemiddelden. We noemen dit de steekproevenverdeling van het gemiddelde (sampling distribution of the mean). We simuleren dit proces weer met de computer; het resultaat staat in Figuur 24.4 (b). Ter vergelijking is in Figuur 24.4 (a) weer de populatie weergegeven.
Code
# Parameters instellenaantal_herhalingen <-10^4# Aantal herhalingensteekproefgroottes <-c(10, 40, 100) # Steekproefgroottesstaafbreedte <-1# Binbreedte voor histogrammen# Simuleer steekproefgemiddeldenset.seed(42) # Voor reproduceerbaarheidsteekproef_gemiddelden <-matrix(nrow = aantal_herhalingen, ncol =length(steekproefgroottes))for (i inseq_along(steekproefgroottes)) {for (j inseq_len(aantal_herhalingen)) { steekproef <-rnorm(steekproefgroottes[i], mean = mu, sd = sigma) steekproef_gemiddelden[j, i] <-mean(steekproef) }}# Zet de steekproefgemiddelden om naar een long-formaat data framesteekproef_gemiddelden <-data.frame(waarde =c( steekproef_gemiddelden[, 1], steekproef_gemiddelden[, 2], steekproef_gemiddelden[, 3] ),groep =factor(rep(c("n = 10", "n = 40", "n = 100"), each = aantal_herhalingen),levels =c("n = 10", "n = 40", "n = 100") ))# Subsets van de data voor elke groepdata_n10 <-subset(steekproef_gemiddelden, groep =="n = 10")data_n40 <-subset(steekproef_gemiddelden, groep =="n = 40")data_n100 <-subset(steekproef_gemiddelden, groep =="n = 100")# Maak afzonderlijke histogrammenplot_n10 <-maakHistogram(data_n10, "waarde", expression(bar(italic(X))), staafbreedte, c(xmin, xmax))plot_n40 <-maakHistogram(data_n40, "waarde", expression(bar(italic(X))), staafbreedte, c(xmin, xmax))plot_n100 <-maakHistogram(data_n100, "waarde", expression(bar(italic(X))), staafbreedte, c(xmin, xmax))populatieplot_n10plot_n40plot_n100
(a) Verdeling van de variabele in de populatie.
(b) Steekproevenverdeling van het gemiddelde bij \(n = 10\).
(c) Steekproevenverdeling van het gemiddelde bij \(n = 40\)
(d) Steekproevenverdeling van het gemiddelde bij \(n = 100\)
Figuur 24.4: Simulaties van steekproeven. (a) De populatieverdeling waaruit de steekproef getrokken wordt. (b, c, d) Steekproevenverdelingen van het gemiddelde, voor \(n = 10\), \(n = 40\), en \(n = 100\).
Het eerste wat opvalt aan de steekproevenverdeling in Figuur 24.4 (b) is dat het gemiddelde van de verdeling op \(\overline{X} = 100\) ligt en dus gelijk is aan de populatieparameter \(\mu_X\). Dat wil zeggen dat \(\overline{X}\) een zuivere schatter is: gemiddeld is die gelijk aan het populatiegemiddelde. (Anders gezegd: de verwachtingswaarde van \(\overline{X}\) is \(\mu_X\).) Dat komt doordat het Normale Model uitgaat van een steekproef zonder bias. De schatter \(\overline{X}\) heeft dus geen systematische fout, maar wel een toevallige fout.
Misschien viel je ook op dat de steekproevenverdeling van het gemiddelde (Figuur 24.4 (b)) een mooie klokvorm heeft die lijkt op een normale verdeling. Dat klopt: als de populatie normaal verdeeld is, is de steekproevenverdeling van het gemiddelde dat ook.
Vergelijk tot slot de steekproevenverdeling van het gemiddelde (Figuur 24.4 (b)) eens met de verdeling van de variabele in de populatie (Figuur 24.4 (a)). Het is duidelijk te zien dat de steekproevenverdeling een veel kleinere spreiding heeft. (De klokvorm is bij de steekproevenverdeling smaller.) Als de verschillende gemiddelden in de steekproevenverdeling sterk van elkaar verschillen, dan wil dat zeggen dat \(\overline{X}\) een onzekere (weinig precieze) schatter is. Daarom is de spreiding van de steekproevenverdeling een maat van de onzekerheid.
Intuïtief zou je verwachten dat een grote steekproef een preciezere schatting oplevert. Laten we dat controleren door de steekproevenverdeling ook te simuleren voor \(n = 40\) en \(n = 100\). De resultaten staan in Figuur 24.4 (c) en Figuur 24.4 (d). Zoals je ziet wordt de piek smaller naarmate \(n\) groter is. De conclusie is: hoe groter de steekproef, hoe dichter de gemiddelden van de steekproeven bij elkaar liggen, en hoe kleiner dus de toevallige fout is.
Als je zelf nog wat wilt experimenteren met steekproeven, dan kun je dat in de applet hieronder doen!
BelangrijkConclusies op basis van de simulaties:
De spreiding van de steekproevenverdeling van het gemiddelde is een maat voor de toevallige fout als gevolg van steekproevenvariabiliteit.
Bij grotere steekproeven heeft de steekproevenverdeling een kleinere spreiding.
Grotere steekproeven geven dus preciezere schattingen.
24.6 De standaarddeviatie van het steekproefgemiddelde.
We zagen net dat de spreiding van de steekproevenverdeling van het gemiddelde aangeeft hoe ver een typische schatting van het populatiegemiddelde ligt. Het is daarom nuttig om die spreiding te kwantificeren. Een goede maat van spreiding is de standaarddeviatie. De standaarddeviatie van de steekproevenverdeling noteren we als \(\sigma_{\overline{X}}\).
Met wat wiskunde (die we je hier zullen besparen) kan de volgende formule voor \(\sigma_{\overline{X}}\) worden afgeleid: \[
\sigma_{\overline{X}} = \frac{\sigma_{X}}{\sqrt{n}}.
\tag{24.2}\] Dit is een belangrijk resultaat! Het bevestigt wat we in Figuur 24.4 al zagen: de standaarddeviatie van de steekproevenverdeling neemt af naarmate \(n\) groter wordt. Maar nu weten we precies hoe sterk die afname is: de afname komt door de \(\sqrt{n}\) in de noemer van Vergelijking 24.2.
Dat wortelteken heeft grote gevolgen. Bijvoorbeeld, als we de toevallige fout twee keer zo klein willen maken, hebben we een vier keer zo grote steekproef nodig. Willen we de toevallige fout 10 keer zo klein hebben, dan moeten we zelfs een 100 keer zo grote steekproef nemen. Dat loopt snel uit de hand.
Wat hebben we met al dit rekenwerk bereikt? We vatten de voorlopige conclusies samen:
BelangrijkConclusies over de steekproevenverdeling van het gemiddelde
We gaan uit van het Normale Model: we trekken onafhankelijk \(n\) eenheden uit een normaalverdeelde populatie met parameters \(\mu_X\) en \(\sigma_{X}\).
Het gemiddelde van \(X\) in de steekproef, dus \(\overline{X}\), is een kansvariabele.
Deze kansvariabele \(\overline{X}\) is normaal verdeeld.
De verwachtingswaarde van \(\overline{X}\) is het populatiegemiddelde \(\mu_X\). Dat betekent dat \(\overline{X}\) een zuivere schatter is voor het populatiegemiddelde.
De standaarddeviatie van \(\overline{X}\) is \(\sigma_{\overline{X}} = \sigma/\sqrt{n}\).
In Paragraaf 23.8.1 (vuistregels) hebben we gezien dat bij een normale verdeling 95% van de waarnemingen binnen 1,96 standaarddeviaties van het gemiddelde valt. Daaruit kunnen we concluderen dat een gemiddelde van een steekproef met 95% zekerheid binnen \(1,96 \sigma_{\overline{X}}\) van de ware populatieparameter \(\mu_X\) afligt.
We kunnen die redenering omdraaien. Als we in een steekproef een steekproefgemiddelde \(\overline{X}\) vinden, dan betekent dit dat met 95% zekerheid \(\mu_X\) binnen \(1{,}96 \sigma_{\overline{X}}\) van die waarde afligt.
Dit is het idee achter het BHI van het gemiddelde. In de volgende paragraaf gaan we dat idee precies maken.
Oefening 24.3 (Steekproevenverdeling van de gemiddelde spanwijdte van buizerds)
Stel dat de gemiddelde spanwijdte van de populatie buizerds in Nederland \(\mu_X = 110\textrm{\,cm}\) is, met standaarddeviatie \(\sigma_{X} = 9\textrm{\,cm}\). Ga uit van het Normale Model.
Schets de verdeling van de populatie. Label het gemiddelde en de standaarddeviatie in de figuur.
Je vangt aselect 1 buizerd en meet de spanwijdte. Wat is de kans dat deze buizerd een spanwijdte heeft die meer dan 18cm afwijkt van \(\mu_X\)?
Arceer de kans in je schets uit onderdeel a.
Je bent van plan om eenvoudig aselect 9 vogels te vangen, hun spanwijdte te meten, en het gemiddelde van die steekproef te meten.
Wat is de verwachtingswaarde van dat steekproefgemiddelde?
Wat is de standaarddeviatie van dat steekproefgemiddelde?
Schets de kansverdeling van het steekproefgemiddelde (de steekproevenverdeling van het gemiddelde). Label het gemiddelde en de standaarddeviatie van deze verdeling.
Wat is de kans dat het steekproefgemiddelde meer dan \(6\textrm{\,cm}\) afwijkt van het populatiegemiddelde \(\mu_X\)?
24.7 95%-BHI van het gemiddelde als de standaarddeviatie van de populatie bekend is
We hebben nu alle theorie op een rijtje om af te leiden hoe je het BHI van een gemiddelde kunt berekenen.
In deze paragraaf behandelen we een situatie die niet vaak voorkomt, maar waarbij de berekening van het BHI gemakkelijk te begrijpen is. We gaan er namelijk vanuit dat we de standaarddeviatie van de populatie, \(\sigma_{X}\), precies weten. Het is moeilijk een situatie te bedenken waarbij we \(\mu_X\) niet weten, maar \(\sigma_{X}\) wel, dus erg realistisch is deze situatie niet. Maar dit is een opstapje naar de iets ingewikkeldere situatie waarbij we \(\sigma_{X}\)niet kennen; die situatie behandelen we in de volgende paragraaf.
We hebben net gezien dat het steekproefgemiddelde \(\overline{X}\) zelf een kansvariabele is. Deze kansvariabele is normaal verdeeld met verwachtingswaarde \(\mu_X\) en standaarddeviatie \(\sigma_{\overline{X}}\). We hebben geleerd dat we elke normaalverdeelde variabele kunnen transformeren naar een standaardnormaal verdeelde variabele \(Z\) door het gemiddelde eraf te trekken en te delen door de standaarddeviatie. Oftewel, \[ Z = \frac{\overline{X} - \mu_X}{\sigma_{\overline{X}}} \tag{24.3}\] is standaardnormaal verdeeld.
Van de standaardnormale verdeling weten we dat tussen -1,96 en 1,96 een kans van 0,95 ligt: \[
\textrm{Pr}\!\left[-1{,}96 < Z < 1{,}96\right] = 0{,}95.
\] We vullen Vergelijking 24.3 in en krijgen: \[
\textrm{Pr}\!\left[-1{,}96 < \frac{\overline{X} - \mu_X}{\sigma_{\overline{X}}} < 1{,}96\right] = 0{,}95.
\] We werken de ongelijkheid verder uit. Eerst vermenigvuldigen we alle kanten van de ongelijkheid met \(-\sigma_{\overline{X}}\): \[
\textrm{Pr}\!\left[1{,}96 \sigma_{\overline{X}} > \mu_X -\overline{X} > -1{,}96 \sigma_{\overline{X}}\right] = 0{,}95.
\] Omdat we met een negatief getal vermenigvuldigd hebben, zijn de tekens van de ongelijkheden omgeklapt. Het is overzichtelijker om de volgorde van de ongelijkheden om te draaien: \[
\textrm{Pr}\!\left[-1{,}96 \sigma_{\overline{X}} < \mu_X -\overline{X} < 1{,}96 \sigma_{\overline{X}}\right] = 0{,}95.
\] Ten slotte tellen we \(\overline{X}\) bij alle kanten van de ongelijkheid op: \[
\textrm{Pr}\!\left[\overline{X} -1{,}96\, \sigma_{\overline{X}} < \mu_X < \overline{X} + 1{,}96\, \sigma_{\overline{X}}\right] = 0{,}95.
\]
Dit is precies de vergelijking waarnaar we op zoek waren! De vergelijking zegt namelijk: elke keer dat we een steekproef nemen en \(\overline{X}\) uitrekenen, hebben we een kans van 0,95 dat het populatiegemiddelde \(\mu_X\) tussen de grenzen \(\overline{X} -1{,}96\, \sigma_{\overline{X}}\) en \(\overline{X} + 1{,}96\, \sigma_{\overline{X}}\) ligt. Dat betekent dat het volgende interval een 95%-BHI is: \[\left[\overline{X} -1{,}96\, \sigma_{\overline{X}}, \overline{X} + 1{,}96\, \sigma_{\overline{X}} \right].\] Het interval wordt ook vaak genoteerd als \[ \mu_X = \overline{X} \pm 1{,}96\, \sigma_{\overline{X}}. \] Laten we dit resultaat weer even samenvatten.
Belangrijk95%-BHI voor de situatie dat \(\sigma_{X}\) bekend is
We gaan uit van het Normale Model, waarin variabele \(X\) normaal verdeeld is in de populatie en de steekproef bestaat uit \(n\) eenheden die onafhankelijk uit die normale verdeling zijn getrokken.
We weten het populatiegemiddelde \(\mu_X\) niet, maar de standaarddeviatie \(\sigma_{X}\) wel.
Dan wordt het 95%-BHI van het populatiegemiddelde \(\mu_X\) gegeven door:
Oefening 24.4 (BHI van de spanwijdte van buizerds)
Neem aan, net als in Oefening 24.3, dat de spanwijdte van buizerds in de populatie normaal verdeeld is met standaarddeviatie \(\sigma_{X} = 9\textrm{\,cm}\). Maar in deze opgave weten we het populatiegemiddelde \(\mu_X\) niet.
Je vangt 9 buizerds (eenvoudig aselect) en meet hun spanwijdte. De meetwaarden zijn, in cm:
Bereken het betrouwbaarheidsinterval voor \(\mu_X\).
Stel dat de standaarddeviatie van de populatie niet \(9\textrm{\,cm}\) maar \(18\textrm{\,cm}\) is. (De spreiding is dus 2 keer zo groot.)
Hoe verandert dan het betrouwbaarheidsinterval?
Ga weer uit van een standaarddeviatie van \(9\textrm{\,cm}\). Stel dat je niet 9 maar 18 vogels gevangen had, maar wel hetzelfde steekproefgemiddelde had gevonden als in onderdeel a.
Hoe verandert dan het betrouwbaarheidsinterval?
Reflecteer op je antwoorden bij c en d. Welke factoren bepalen de onzekerheid in onze schatting van \(\mu_X\)?
24.8 BHI als de variantie van de populatie niet bekend is
In de vorige paragraaf hebben we een 95%-BHI afgeleid voor de situatie waarin de populatievariantie \(\sigma_{X}\) bekend is. De afleiding voor de gebruikelijke situatie, waarin \(\sigma_{X}\)niet bij voorbaat gegeven is, volgt dezelfde route — maar met een twist.
In feite gaat de afleiding van de vorige paragraaf ook op voor deze situatie, tot en met het eindresultaat van Vergelijking 24.4. Het probleem is alleen dat we nu niets aan deze formule hebben. Om de grenzen van dat interval uit te rekenen, zullen we namelijk een waarde moeten invullen voor \(\sigma_{\overline{X}} = \sigma_{X}/\sqrt{n}\), en dat gaat niet als we \(\sigma_{X}\) niet weten.
Om verder te kunnen komen zullen we \(\sigma_{X}\) op een of andere manier moeten schatten; daarover gaat de volgende paragraaf.
De standaardfout van het steekproefgemiddelde
Om \(\sigma_{X}\) te schatten maken we gebruik van de standaarddeviatie van de steekproef, \(s_X\). Je verwacht namelijk dat \(s_X\) een redelijke benadering is van \(\sigma_{X}\).
Omdat we \(s_X\) kunnen gebruiken als schatter voor \(\sigma_{X}\) kunnen we ook \(\sigma_{\overline{X}} = \sigma_{X}/\sqrt{n}\) schatten door voor \(\sigma_{X}\) de waarde van \(s_X\) in te vullen. Het resultaat wordt de standaardfout van het gemiddelde genoemd: \[
\mathrm{SE}_{\overline{X}} = \frac{s_X}{\sqrt{n}}.
\tag{24.5}\] Hier gebruiken we de notatie \(\mathrm{SE}_{\overline{X}}\); in de literatuur kom je ook de afkorting SEM tegen, wat staat voor Standard Error of the Mean.
BelangrijkDefinitie: Standaardfout van het gemiddelde.
In de situatie waarbij \(\sigma_{X}\) bekend was, konden we de kansvariabele \(\overline{X}\) transformeren naar een standaard-normaal verdeelde variabele door middel van Vergelijking 24.3: \[ Z = \frac{\overline{X} - \mu_X}{\sigma_{\overline{X}}}. \] Om uiteindelijk een formule voor een BHI te krijgen waarin in plaats van \(\sigma_{\overline{X}}\) de standaardfout \(\mathrm{SE}_{\overline{X}}\) voorkomt, moeten we in de noemer \(\sigma_{\overline{X}}\) vervangen door zijn schatter \(\mathrm{SE}_{\overline{X}}\). Helaas heeft dat ook tot gevolg dat de getransformeerde variabele nu niet meer standaardnormaal verdeeld is. We noemen het resultaat van de transformatie daarom niet meer \(Z\), maar \(t\): \[
t = \frac{\overline{X} - \mu_X}{\mathrm{SE}_{\overline{X}}}.
\tag{24.7}\] De keuze voor \(t\) als de naam van deze getransformeerde variabele is niet willekeurig. Er kan namelijk worden aangetoond dat \(t\) onder het Normale Model een \(t\)-verdeling volgt met \(n - 1\) vrijheidsgraden. Dat wil zeggen: als je
een steekproef neemt van \(n\) eenheden,
het gemiddelde \(\overline{X}\) en de standaarddeviatie \(s\) van die steekproef berekent
dan is \(t\) een kansvariabele met als kansverdeling de \(t\)-verdeling met \(n-1\) vrijheidsgraden.
Helaas voert het bewijs voor deze stelling te ver voor deze cursus; je zult daarop moeten vertrouwen. Maar in de spirit van trust, but verify kun je de bewering wel controleren met behulp van simulaties.
TipDe \(t\)-verdeling controleren met simulaties
We verifiëren dat de \(t\) uit Vergelijking 24.7 onder het Normale Model een \(t\)-verdeling volgt met \(n - 1\) vrijheidsgraden.
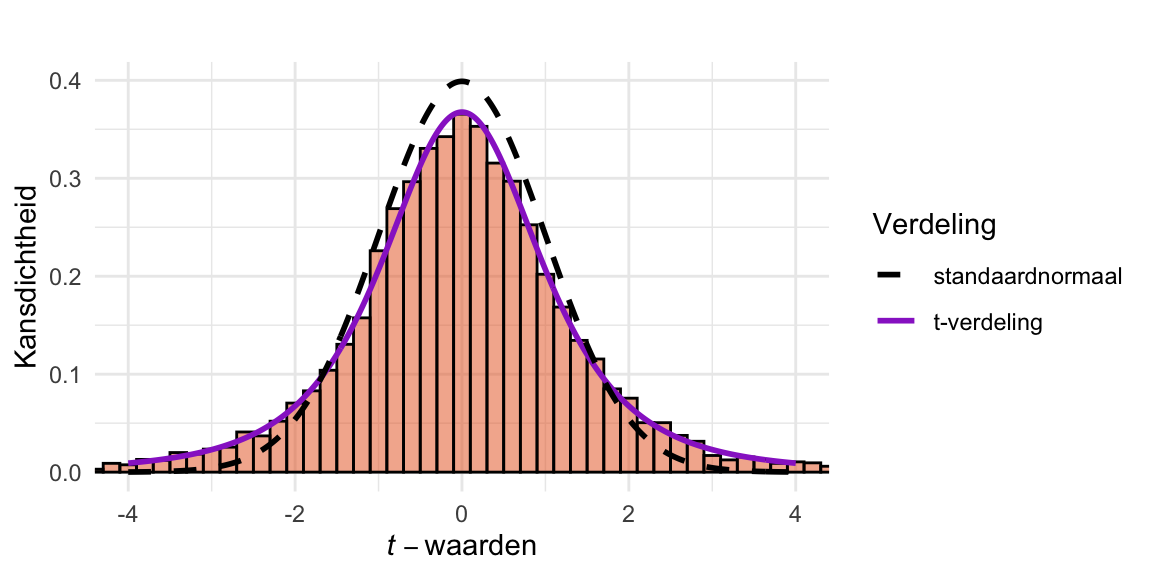
De code hieronder (klik op “Code” om die zichtbaar te maken) neemt \(10^4\) keer een (kleine) steekproef (\(n = 4\)) uit een normale verdeling, en berekent op basis van die steekproeven steeds \(\overline{X}\), \(s\), \(\mathrm{SE}_{\overline{X}}\), en uiteindelijk \(t\). Het histogram van de verkregen \(t\) waarden zou dan de \(t\)-verdeling met \(\mathrm{df}= n -1 = 3\) vrijheidsgraden moeten volgen. Om dat te verifiëren plot de code bovenop het histogram ook die \(t\)-verdeling (in paars).
Code
# Parameters instellenaantal_iteraties <-10^4# Aantal herhalingensteekproefgrootte <-4# Grootte van de steekproefmu <-100# Populatiegemiddeldesigma <-10# Populatiestandaarddeviatievrijheidsgraden <- steekproefgrootte -1# Vrijheidsgraden voor t-verdelingstaafbreedte <-0.2# Binbreedte voor het histogramdomein <-seq(-4, 4, length.out =400) # Verfijnd domein voor gladde lijnen# Genereer t-waardenset.seed(42) # Voor reproduceerbaarheidt_waarden <-replicate(aantal_iteraties, {# Trek een steekproef steekproef <-rnorm(steekproefgrootte, mean = mu, sd = sigma)# Bereken steekproefgemiddelde en standaarddeviatie van de steekproef gemiddelde <-mean(steekproef) s <-sd(steekproef)# Bereken standaardfout SE <- s /sqrt(steekproefgrootte)# Bereken t-waarde t <- (gemiddelde - mu) / SEreturn(t)})# Zet t-waarden in een data framedata <-data.frame(t_waarden)# Bereid theoretische verdelingen voortheoretische_data <-data.frame(x = domein,t_verdeling =dt(domein, df = vrijheidsgraden),standaard_normaal =dnorm(domein))# Maak het histogram en voeg de theoretische verdelingen toeggplot(data, aes(x = t_waarden)) +geom_histogram(aes(y = ..density..), # schaal het histogram, totale oppervlakte 1 binwidth = staafbreedte, fill = opvulkleur, color ="black", alpha =0.5,show.legend =FALSE ) +geom_line(data = theoretische_data, aes(x = x, y = t_verdeling, color ="t-verdeling"), linewidth =1 ) +geom_line(data = theoretische_data, aes(x = x, y = standaard_normaal, color ="standaardnormaal"), linewidth =1, linetype ="dashed" ) +scale_color_manual(values =c("t-verdeling"="DarkOrchid", "standaardnormaal"="black"),name ="Verdeling" ) +coord_cartesian(xlim =c(-4, 4)) +# Beperk het domein van de plotlabs(x =expression(italic(t)-waarden),y ="Kansdichtheid",title ="" ) +theme_minimal()
Figuur 24.5: Histogram van \(t\)-waarden vergeleken met de \(t\)-verdeling en standaardnormale verdeling.
Ter vergelijking is ook de standaardnormale verdeling toegevoegd (zwarte stippellijn). Zoals je geleerd hebt in Paragraaf 23.10 heeft de \(t\)-verdeling een lagere piek en dikkere staarten, en dus een grotere spreiding. In dit geval komt dat doordat in de noemer van Vergelijking 24.7 niet \(\sigma_{\overline{X}}\) staat maar de schatter daarvan, \(\mathrm{SE}_{\overline{X}}\). Nu is niet alleen de teller maar ook de noemer onzeker. Daardoor is \(t\) (Vergelijking 24.7) onzekerder dan \(Z\) (Vergelijking 24.3).
We vatten de situatie weer even samen:
BelangrijkBelangrijk:
Onder het Normale Model is de kansverdeling van de kansvariabele \[
t = \frac{\overline{X} - \mu_X}{\mathrm{SE}_{\overline{X}}}
\tag{24.8}\] de \(t\)-verdeling met \(n - 1\) vrijheidsgraden.
Afleiding van het 95%-BHI
Nu we dit alles weten, kunnen we de afleiding van het 95%-BHI eindelijk afmaken.
Omdat de \(t\) uit Vergelijking 24.8 verdeeld is volgens de \(t\)-verdeling met \(n-1\) vrijheidsgraden, geldt \[
\textrm{Pr}\!\left[ -t_{0{,}05 (2) \mathrm{(n-1)}} < t < t_{0{,}05 (2) \mathrm{(n-1)}} \right] = 0{,}95.
\] We hebben hier de kritieke waarden gebruikt voor de \(t\)-verdeling (zie Vergelijking 23.14 en de paragraaf daar omheen).
Als we Vergelijking 24.8 hierin invullen, krijgen we \[
\textrm{Pr}\!\left[
-t_{0{,}05 (2) \mathrm{(n-1)}} < \frac{\overline{X} - \mu_X}{\mathrm{SE}_{\overline{X}}} < t_{0{,}05 (2) \mathrm{(n-1)}} \right] = 0{,}95.
\] De afleiding is verder helemaal analoog aan die van Paragraaf 24.7. We vermenigvuldigen de ongelijkheden eerst met \(-\mathrm{SE}_{\overline{X}}\): \[
\textrm{Pr}\!\left[t_{0{,}05 (2) \mathrm{(n-1)}}\, \mathrm{SE}_{\overline{X}} > \mu_X - \overline{X} > -t_{0{,}05 (2) \mathrm{(n-1)}}\,\mathrm{SE}_{\overline{X}}\right] = 0{,}95.
\] Het is overzichtelijker om de ongelijkheden om te draaien: \[
\textrm{Pr}\!\left[-t_{0{,}05 (2) \mathrm{(n-1)}}\, \mathrm{SE}_{\overline{X}} < \mu_X - \overline{X} < t_{0{,}05 (2) \mathrm{(n-1)}}\,\mathrm{SE}_{\overline{X}}\right] = 0{,}95.
\] Tot slot tellen we \(\overline{X}\) bij de ongelijkheden op: \[
\textrm{Pr}\!\left[\overline{X} -t_{0{,}05 (2) \mathrm{(n-1)}}\, \mathrm{SE}_{\overline{X}} < \mu_X < \overline{X} + t_{0{,}05 (2) \mathrm{(n-1)}}\, \mathrm{SE}_{\overline{X}}\right] = 0{,}95.
\] Dit is precies de vergelijking waarnaar we op zoek waren! De vergelijking zegt dat er iedere keer dat we een steekproef nemen een kans van 0,95 is dat de populatieparameter \(\mu_X\) tussen de grenzen \(\overline{X} -t_{0{,}05 (2) \mathrm{(n-1)}}\) en \(\overline{X} + t_{0{,}05 (2) \mathrm{(n-1)}}\) ligt. Oftewel, het 95%-BHI is: \[
\left[\overline{X} -t_{0{,}05 (2) \mathrm{(n-1)}}\, \mathrm{SE}_{\overline{X}}, \overline{X} + t_{0{,}05 (2) \mathrm{(n-1)}}\, \mathrm{SE}_{\overline{X}} \right].
\] Dit wordt ook vaak geschreven als \[
\mu_X = \overline{X} \pm t_{0{,}05 (2) \mathrm{(n-1)}}\, \mathrm{SE}_{\overline{X}}.
\]
Laten we dit eindresultaat maar weer eens samenvatten:
Belangrijk95%-BHI voor de situatie dat \(\sigma_{X}\) onbekend is
We gaan uit van het Normale Model, waarin variabele \(X\) normaal verdeeld is in de populatie en de steekproef bestaat uit \(n\) eenheden die onafhankelijk uit die normale verdeling zijn getrokken.
Het populatiegemiddelde \(\mu_X\) en de standaarddeviatie \(\sigma_{X}\) van de populatie zijn ons onbekend.
Dan wordt het 95%-BHI van het populatiegemiddelde \(\mu_X\) gegeven door:
Vergelijk Vergelijking 24.9 eens met Vergelijking 24.4, de formule die we hadden afgeleid voor de (onwaarschijnlijke) situatie dat \(\sigma_{X}\) vooraf bekend is. De formules lijken erg op elkaar, maar er zijn twee verschillen.
Ten eerste, waar in Vergelijking 24.4\(\sigma_{\overline{X}}\) staat, staat in Vergelijking 24.9 de standaardfout \(\mathrm{SE}_{\overline{X}}\). Ten tweede wordt in Vergelijking 24.9 de kritieke waarde van de \(t\)-verdeling gebruikt in plaats van de kritieke waarde van de standaard-normale verdeling, 1,96. Omdat de kritieke \(t\)-waarde altijd groter is dan 1,96 zorgt dit voor bredere betrouwbaarheidsintervallen. Die bredere betrouwbaarheidsintervallen reflecteren het feit dat we zonder kennis van \(\sigma_{X}\) ook onzekerder zijn over de waarde van \(\mu_X\).
Maar als het aantal waarnemingen niet al te klein is, is dat effect klein. In Figuur 23.13 zagen we al dat de kritieke \(t\)-waarde al bij 10 vrijheidsgraden dicht bij 2 ligt. Als grove schatting is \(\mu_X = \overline{X} \pm 2 \mathrm{SE}_{\overline{X}}\) dus meestal een redelijke benadering van het 95%- BHI.
Om concreet te maken hoe je een 95%-BHI kunt berekenen, werken we nu een eenvoudig voorbeeld uit.
Voorbeeld 24.1 (95%-BHI voor de opbrengst van aardappelplanten)
StSP6A is een transgene lijn van aardappelplanten. Onderzoekers willen weten wat het effect van de mutatie is op de aardappelopbrengst. Daarom planten ze 5 planten in een kas en laten die 100 dagen groeien onder gecontroleerde condities. Daarna worden de aardappels gerooid en wordt van iedere plant het totale gewicht aan aardappels bepaald.
De resultaten zijn:
Plant
Tubergewicht (g)
1
112
2
125
3
119
4
89
5
102
We berekenen het 95%-BHI van het gemiddelde tubergewicht. We volgen de volgende stappen:
De steekproefgrootte is \(n = 5\).
Het steekproefgemiddelde (Vergelijking 20.1) van de aardappelen is \(\overline{x} = 109{,}4\textrm{\,g}\).
De standaarddeviatie (Vergelijking 20.6) van de steekproef is \(s_X = 14{,}26\textrm{\,g}\).
De standaardfout (Vergelijking 24.6) is \(\mathrm{SE}_{\overline{X}} = s_X / \sqrt{n} = 6{,}38\textrm{\,g}\).
Het aantal vrijheidsgraden is \(\mathrm{df}= n - 1 = 4\).
Voor de kritieke waarde \(t_{0{,}05 (2) \mathrm{4}}\) raadplegen we R (Paragraaf 23.11.3):
alpha <-0.05qt(1- alpha/2, df =4)
[1] 2.776445
De ondergrens van het 95%-BHI is \(\overline{X} - t_{0{,}05 (2) \mathrm{4}} \mathrm{SE}_{\overline{X}} = 91{,}7\textrm{\,g}\).
De bovengrens van het 95%-BHI is \(\overline{X} + t_{0{,}05 (2) \mathrm{4}} \mathrm{SE}_{\overline{X}} = 127{,}1\textrm{\,g}\).
Het betrouwbaarheidsinterval is dus \([91{,}7\textrm{\,g}; 127{,}1\textrm{\,g}]\), oftewel \((109{,}4 \pm 17{,}7)\textrm{\,g}\).
Oefening 24.5 (BHI van de gemiddelde spanwijdte van buizerds (alweer???))
Neem aan, net als in Oefening 24.4, dat de spanwijdte van buizerds in de populatie normaal verdeeld is. We weten het populatiegemiddelde \(\mu_X\) niet. Deze keer weten we ook de standaarddeviatie van de populatie \(\sigma_X\) niet.
Je vangt 9 buizerds (eenvoudig aselect) en meet hun spanwijdte. De meetwaarden zijn hetzelfde als in Oefening 24.4.
Volg de stappen 1 t/m 8 van Voorbeeld 24.1 om het BHI van de gemiddelde spanwijdte te berekenen. Je mag hiervoor een scriptje in R gebruiken.
Een BHI berekenen met R
In Voorbeeld 24.1 bestond de dataset uit maar vijf waarnemingen. Daarom was het goed mogelijk om het BHI met de hand uit te rekenen. Maar zelfs dan moesten we van R gebruik maken om de kritieke waarde op te zoeken. In de praktijk is het dus veel gemakkelijker en betrouwbaarder om de hele berekening in R uit te voeren.
In Oefening 24.5 heb je de berekening zelf ingeprogrammeerd. Maar het kan gemakkelijker: er bestaat standaard in R een functie die de hele berekening voor je uitvoert.
Het volgende blokje code laat zien hoe gemakkelijk dat is:
# creëer een vector met de gewichten (in g)gewichten <-c(112, 125, 119, 89, 102)# voer de functie t.test uit en sla de resultaten opuitvoer_t.test <-t.test(gewichten)# selecteer uit de resultaten het 95%-BHIuitvoer_t.test$conf.int
Je maakt gebruik van de functie t.test() die we in de volgende hoofdstukken nog vaker gaan terugzien. Deze functie berekent allerlei statistieken, waaronder het BHI. We slaan eerst de uitvoer van t.test() op in een variabele. In de code hierboven heet die variabele uitvoer_t.test. Vervolgens vragen we uit deze uitvoer het betrouwbaarheidsinterval (conf.int) op. Als het goed is, komt de uitvoer precies overeen met de getallen die in Voorbeeld 24.1 berekend hadden. Klopt dat?
Oefening 24.6 (Weer 9 buizerds)
Controleer je antwoord op Oefening 24.5 met behulp van de functie t.test().
24.9 Het Normale Model is ook geschikt voor herhaalde experimenten met meetfouten
In dit hoofdstuk hebben we het uitgebreid gehad over schattingen van populatieparameters op basis van een steekproef. In ander onderzoek in de biologie maken we geen gebruik van steekproeven maar proberen we een bepaalde grootheid te meten. In Hoofdstuk 21 hebben we besproken dat zulke metingen vaak worden geplaagd door meetfouten. Als de meetmethode goed gekalibreerd is, is de toevallige fout het grootste probleem.
Om de toevallige fout te verminderen wordt meestal dezelfde meting meerdere keren gerepliceerd (herhaald) en worden de uitkomsten gemiddeld. Als we een heel erg groot aantal replicaties zouden kunnen uitvoeren zou de toevallige fout uitmiddelen en het gemiddelde van de meetwaarden dus de échte waarde van grootheid aangeven. Maar in de praktijk moeten we het doen met een beperkt aantal replicaties.
In andere woorden, iedere meting is een kansexperiment, het meetresultaat is een kansvariabele, en we zijn geïnteresseerd in de verwachtingswaarde van die kansvariabele, \(\mu_X\), die we zouden vinden als we de meting oneindig vaak zouden herhalen. Ons doel is om die parameter te schatten op basis van een eindig aantal experimenten.
Om dat te doen, hebben we weer een statistisch model nodig. Vaak worden daarbij de volgende aannames gemaakt:
BelangrijkDefinitie: het Normale Model voor herhaalde metingen
De uitkomsten van de metingen zijn normaal verdeeld. Resultaten van herhaalde metingen hebben vaak een klokvormige verdeling. Dit model gaat ervan uit dat die verdeling benaderd kan worden door een normale verdeling.
Iedere meting \(X_i\) is onafhankelijk uit die normale verdeling getrokken. Dit is het geval als de verschillende replicaties daadwerkelijk onafhankelijk van elkaar zijn uitgevoerd. Dat is niet altijd het geval. We gaan het hier uitgebreid over hebben in Paragraaf 24.10.1.
Als je deze modelaannames vergelijkt met het Normale Model voor steekproeven (Paragraaf 24.4) dan zie je dat die twee modellen precies overeenkomen! In beide gevallen behandelen we de gegevens als uitkomsten van een kansexperiment. In het ene geval bestaat dat kansexperiment uit het aselect trekken van een individu uit een populatie, in het andere geval uit het uitvoeren van een meting met een toevallige fout. Maar in beide gevallen veronderstelt het model dat de waarnemingen onafhankelijk getrokken zijn uit een normale verdeling.
BelangrijkConclusie:
Het Normale Model voor steekproeven en het Normale Model voor herhaalde metingen komen op hetzelfde neer. Alle resultaten uit dit hoofdstuk, inclusief de formules voor BHI’s, kunnen dus net zo goed gebruikt worden voor gegevens die het resultaat zijn van een steekproef als voor gegevens die het resultaat zijn van herhaalde metingen.
Oefening 24.7 (Het meten van de smelttemperatuur van een DNA-sequentie)
Je meet de smelttemperatuur van een specifieke DNA-sequentie met behulp van UV-absorptie-metingen. Je repliceert de meting tien keer in onafhankelijke experimenten.
De resultaten zijn in de volgende vector gegeven (in \(\degree\)C):
Ga ervan uit dat de toevallige fout normaal verdeeld is.
Bereken in R het 95%-betrouwbaarheidsinterval voor de smelttemeratuur.
24.10 Afwijkingen van het Normale Model
Bij de afleiding van de formule voor het BHI (Vergelijking 24.9) zijn we steeds uitgegaan van het Normale Model. In de praktijk zijn de aannames van het Normale Model zelden exact waar. Met name wijkt de verdeling van de variabele in de populatie vaak af van de normale verdeling.
Daarom is het essentieel om, voordat je een BHI uitrekent met Vergelijking 24.9, eerst zorgvuldig na te gaan of dat wel verstandig is. We zullen het daarom eerst hebben over manieren waarop je afwijkingen van het Normale Model kunt herkennen. Daarna laten we zien dat zulke afwijkingen niet altijd een probleem zijn; de formule voor het BHI is behoorlijk “robuust” voor afwijkingen.
Is het Normale Model bij voorbaat wel plausibel?
Een eerste stap voordat je een BHI uitrekent is om te bedenken of de aannames van het Normale Model bij voorbaat wel plausibel zijn.
Een belangrijke aanname is dat de variabele in de populatie normaal verdeeld is. Voor sommige variabelen is dat niet aannemelijk. Dat kan verschillende redenen hebben:
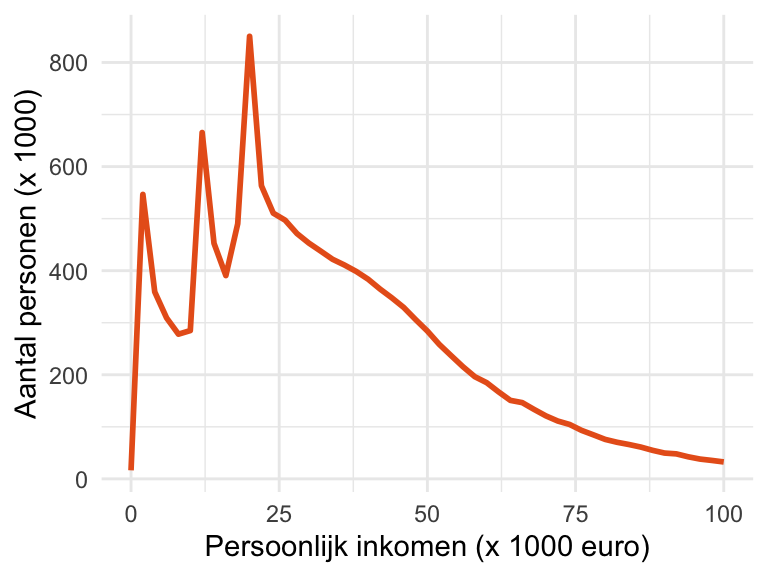
Het is bekend dat de verdeling van de variabele scheef is. Bijvoorbeeld, het is algemeen bekend dat de verdeling van inkomen in de meeste landen erg rechts-scheef is. In Figuur 24.6 is de verdeling van persoonlijk inkomen in Nederland weergegeven.1 Wanneer je een BHI wilt uitrekenen voor zo’n variabele moet je dus op je hoede te zijn.
Code
VerdelingPersoonlijkInkomen_CBS_2022 <-read_csv("data/VerdelingPersoonlijkInkomen-CBS-2022.csv", locale =locale(decimal_mark =","))ggplot(VerdelingPersoonlijkInkomen_CBS_2022, aes(y = Totaal, x =`persoonlijk inkomen (1000 euro)`)) +geom_line(color = lijnkleur0, linewidth =1) +labs(x ="Persoonlijk inkomen (x 1000 euro)", y ="Aantal personen (x 1000)") +theme_minimal()
Figuur 24.6: Verdeling van persoonlijk inkomen in Nederland, 2022
De populatie bestaat uit meerdere deelpopulaties met vermoedelijk sterk verschillende gemiddelden. In dat geval zou de verdeling van de variabele multimodaal kunnen zijn of anderszins kunnen afwijken van een normale verdeling.
De variabele kan alleen waarden aannemen in een bepaald interval. Een normaal-verdeelde variabele kan iedere mogelijke waarde hebben, van \(-\infty\) tot \(\infty\). Dat geldt zelden voor biologische variabelen. Concentraties en populatiegroottes kunnen bijvoorbeeld nooit negatief zijn. Een normale verdeling kan dan nog steeds een goede benadering zijn, maar alleen als de bulk van de verdeling ver verwijderd is van de grenzen van het toelaatbare interval.
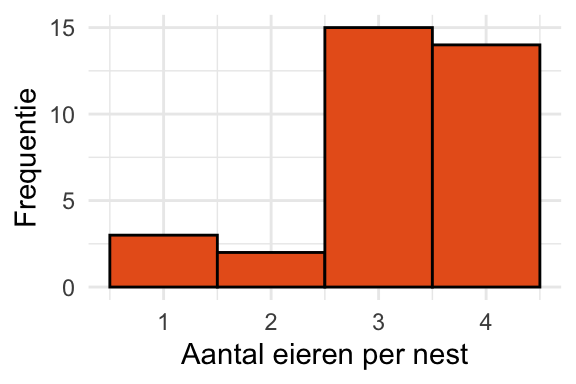
De variabele is discreet. Discrete variabelen kunnen bij benadering normaal verdeeld zijn als ze een groot gemiddelde hebben. Maar als de discrete waarden typisch klein zijn is dat duidelijk niet het geval. Bijvoorbeeld, de vink (Fringilla Coelebs Africana) legt typisch 3 of 4 eieren; zie Figuur 24.7. Het Normale Model is voor aantal eieren dus zeker niet geschikt.
Figuur 24.7: Aantal eieren in 34 nesten van de vink Fringilla Coelebs Africana2.
De tweede aanname van het Normale Model was dat iedere waarde onafhankelijk uit de verdeling is getrokken. Ook over die aanname moet je goed nadenken. Dee opzet van de steekproef of van het experiment geeft soms aanleiding om daaraan te twijfelen. Voorbeelden:
Pseudo-replicatie. In het kort verwijst pseudo-replicatie naar metingen of experimenten die meerdere keren zijn uitgevoerd onder dezelfde omstandigheden, zoals in één batch, op dezelfde dag, of met dezelfde materialen. Eventuele toevallige invloeden van die omstandigheden zijn daardoor bij al die pseudo-replicaties gelijk en dus zijn de replicaties niet onafhankelijk. De uitkomsten van zulke pseudo-replicaties zullen daardoor dichter bij elkaar liggen dan bij replicaties die daadwerkelijk onafhankelijk zijn uitgevoerd. Dat leidt onterecht tot een smaller BHI.
Tijdseries. Metingen over de tijd van dezelfde variabele zullen vaak niet onafhankelijk zijn. Een voorbeeld is de lichaamstemperatuur van één en dezelfde persoon gemeten op opeenvolgende dagen. Wie vandaag koorts heeft, heeft dat vaak morgen ook; metingen op opeenvolgende dagen zijn dus niet onafhankelijk. Je kunt er bij het berekenen van een tijdsgemiddelde dus niet zomaar van uitgaan dat de metingen onafhankelijk zijn.
Steekproeven die bestaan uit groepjes. Een andere situatie is een steekproef die bestaat uit samenhangende groepjes. Bijvoorbeeld, stel dat een reisorganisatie alle reizigers om hun mening vraagt, maar de reizigers vaak reizen in paren of als gezin. Dan is er een gevaar dat de meningen van reisgezellen niet onafhankelijk zijn.
Kortom, het is belangrijk om goed na te denken over de aard van de variabele en de manier waarop de gegevens tot stand zijn gekomen om zo te bepalen of het Normale Model van toepassing lijkt.
Geven de gegevens aanleiding tot twijfel?
Vervolgens is het belangrijk om de gegevens zelf te bekijken om te zien of die aanleiding geven tot twijfel over het Normale Model.
Als de populatie een verdeling heeft die sterk afwijkt van een normale verdeling, dan verwacht je dat ook te zien in een steekproef uit die populatie (tenzij die steekproef heel klein is). Voordat je een BHI berekent of welke statistische analyse dan ook uitvoert moet je dus altijd eerst je gegevens goed bestuderen.
In Hoofdstuk 20 heb je geleerd hoe je de verdeling van een variabele kunt beschrijven en visualiseren. Voordat je een BHI berekent pas je dus altijd die methoden toe. Dat wil zeggen:
Bereken kengetallen.
Bekijk het aantal waarnemingen \(n\).
Bereken maten van ligging en spreiding en bekijk die kritisch. Als de mediaan bijvoorbeeld sterk afwijkt van het gemiddelde, dan is dat een indicatie van een scheve verdeling of bijzondere uitbijters.
Visualiseer de gegevens.
Maak een histogram en/of een boxplot en bekijk die goed. Ziet de histogram er symmetrisch en klokvormig uit? Zijn de snorharen van de boxplot ongeveer symmetrisch, ligt de mediaan ongeveer in het midden van de box, en zijn er opvallende uitbijters? Als de verdeling er vreemd of scheef uitziet is het Normale Model mogelijk niet van toepassing.
Bestudeer een Normale Kwantiel-Kwantiel-plot.
Er bestaat een grafiek die speciaal ontworpen is om afwijkingen van de normale verdeling beter zichtbaar te maken. Deze grafiek heet de Normale Kwantiel-Kwantiel-plot (Normal QQ plot). We zullen die plot in het de volgende paragraaf even apart bespreken.
Door altijd de bovenstaande beschrijvende statistieken en figuren te bestuderen krijg je een goed beeld van de toepasbaarheid van het Normale Model.
Het Normale Kwantiel-Kwantiel-plot (normal QQ-plot)
Een Kwantiel-Kwantiel-plot (Quantile-Quantile plot, QQ-plot) is een grafiek waarmee je op het oog kunt controleren of een dataset een bepaalde verdeling volgt, zoals een normale verdeling.
Stel, je hebt in een experiment 101 waarnemingen verzameld. We sorteren de waarden van klein naar groot. De mediaan is dan de 51e waarde.
We willen controleren of deze gegevens uit een normale verdeling getrokken zijn. Als dat zo is, dan verwachten we dat de mediaan van de waarnemingen in de buurt ligt van het gemiddelde van de waarnemingen, want de normale verdeling is symmetrisch. Het eerste kwartiel (Q1) van de waarnemingen verwachten we ongeveer 0,67 standaarddeviaties onder het gemiddelde, want daar ligt voor de normale verdeling het eerste kwartiel.
Op deze manier kunnen we de kwantielen van de gegevens vergelijken met de kwantielen die we theoretisch hadden verwacht als de gegevens uit een normale verdeling getrokken waren.
Dat is in een notendop wat een QQ-plot doet. Voor iedere waarneming wordt op de \(y\)-as het kwantiel geplot dat bij die waarneming hoort, en op de \(x\)-as het kwantiel dat je had verwacht als de gegevens normaal verdeeld waren. Hier zijn twee voorbeelden:
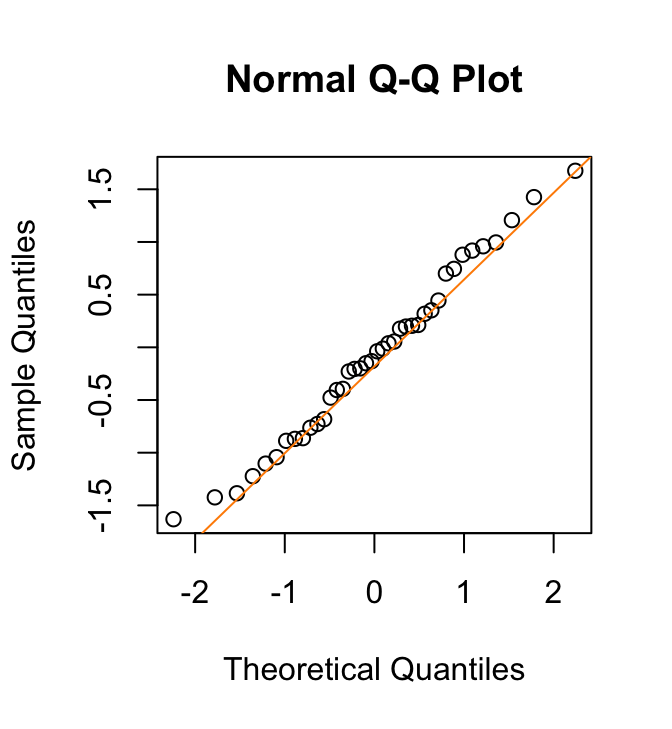
(a) QQ-plot van een steekproef uit een normale verdeling
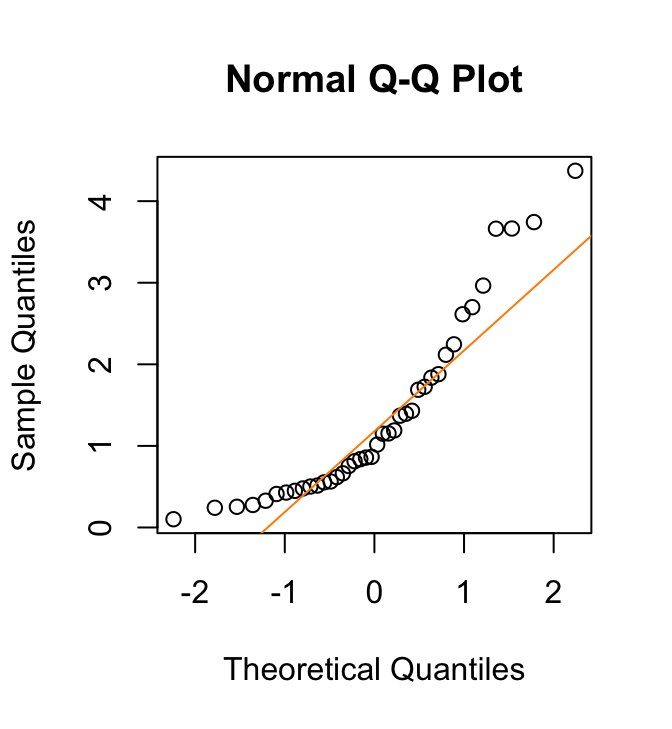
(b) QQ-plot van een steekproef uit een rechts-scheve verdeling
Figuur 24.8: QQ-plots van steekproeven uit (a) een normale verdeling en (b) een rechts-scheve verdeling. De steekproef uit de normale verdeling levert een rechte lijn op. Die van de rechts-scheve verdeling wijkt systematisch af
Als de gegevens uit een normale verdeling getrokken zijn komen de kwantielen van de waarnemingen grofweg overeen met de theoretische kwantielen. In dat geval vallen de datapunten ongeveer op een rechte lijn, zoals in Figuur 24.8 (a). Systematische afwijkingen van die rechte lijn geven aan dat de gegevens afwijkingen vertonen van een normale verdeling, zoals in Figuur 24.8 (b). Zo kun je beoordelen of de gegevens er “normaal” uitzien.
Het tekenen van een QQ-plot is met behulp van R erg gemakkelijk. Als gegevens een numerieke vector is, dan werkt het zo:
qqnorm(gegevens) # normale kwantielen-kwantielen-plot (normal QQ-plot)qqline(gegevens) # voeg er een lijn aan toe die de theoretische voorspelling aangeeft
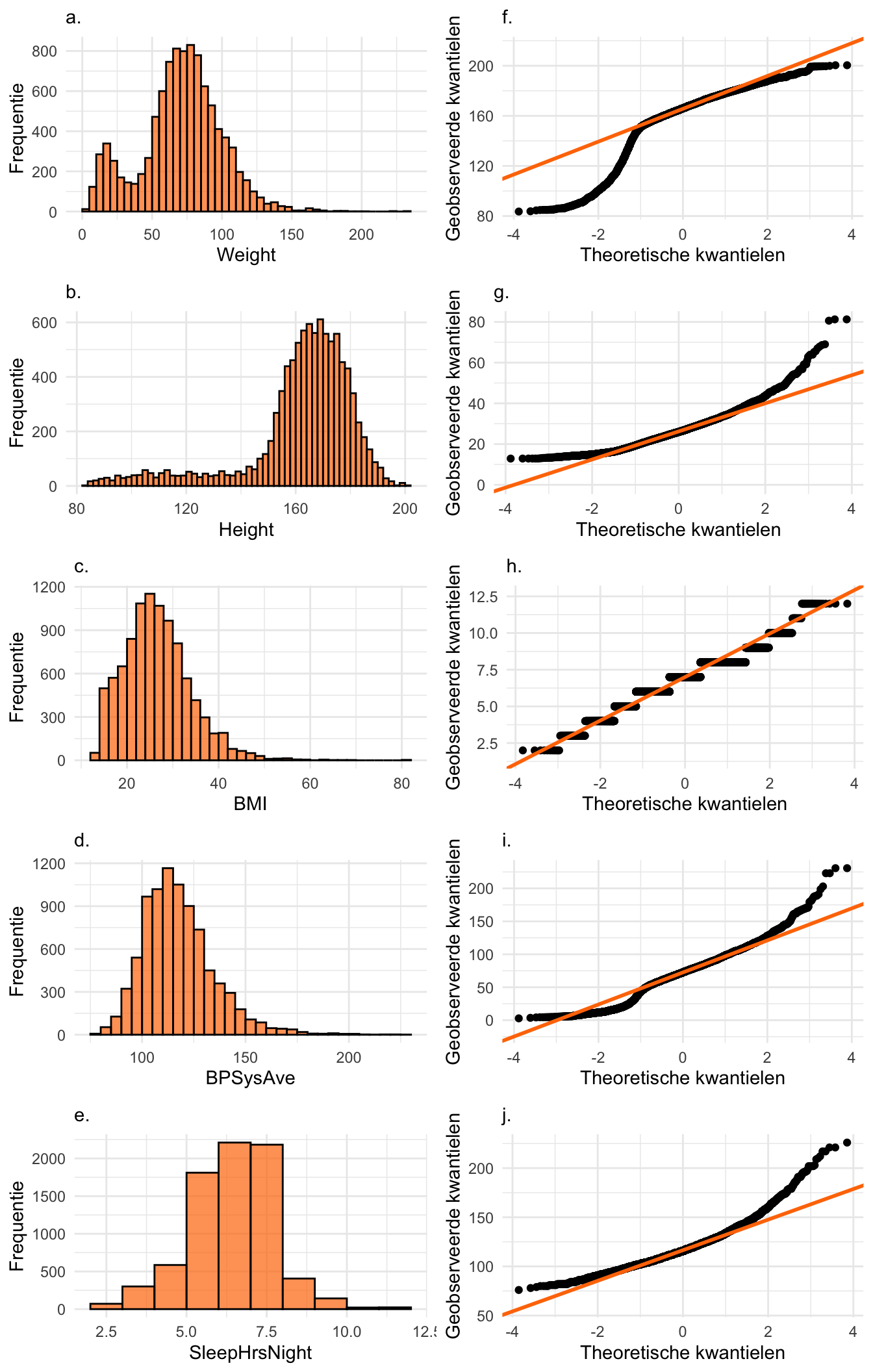
Oefening 24.8 (Normale QQ-plots en histogrammen) Hieronder vind je een figuur met vijf histogrammen en vijf normale QQ-plots van variabelen uit de NHANES dataset. Kun jij uitvinden welke QQ-plot bij welke histogram hoort?
De centrale limietstelling en de robuustheid van het Normale Model
Als de verdeling van de variabele in de populatie niet normaal is, gaat de afleiding van het BHI (Paragraaf 24.8) niet precies op. In deze paragraaf zullen we uitleggen dat de formule voor het BHI dan vaak toch nog een goede benadering is.
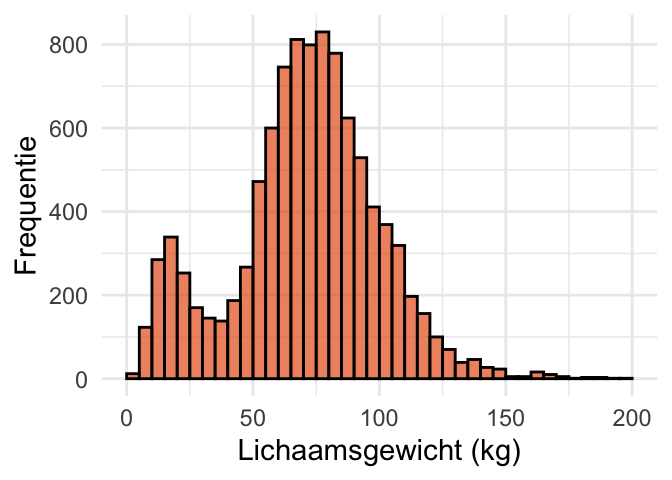
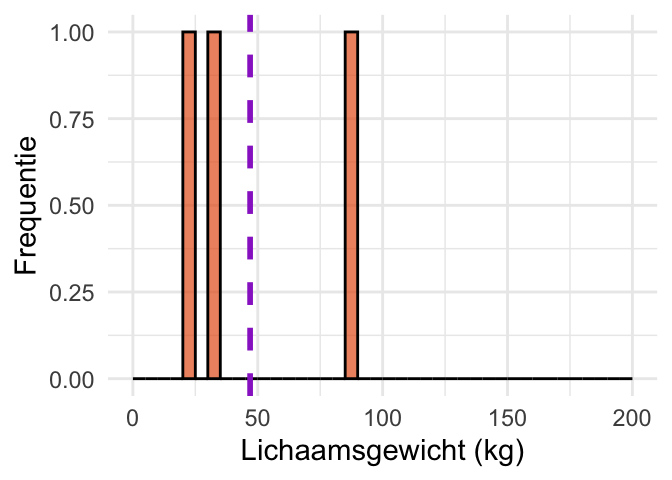
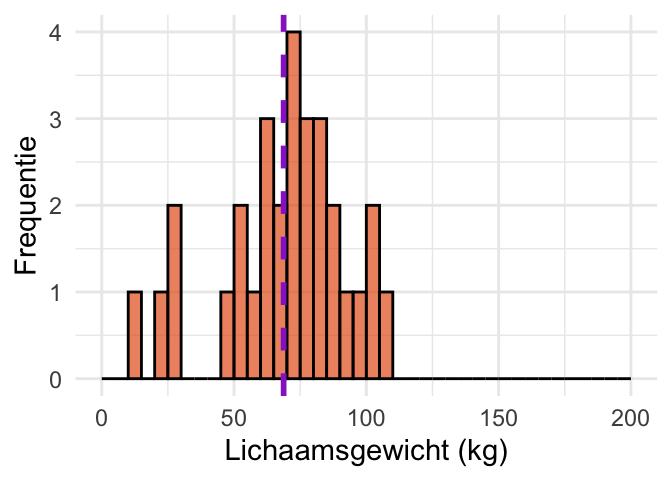
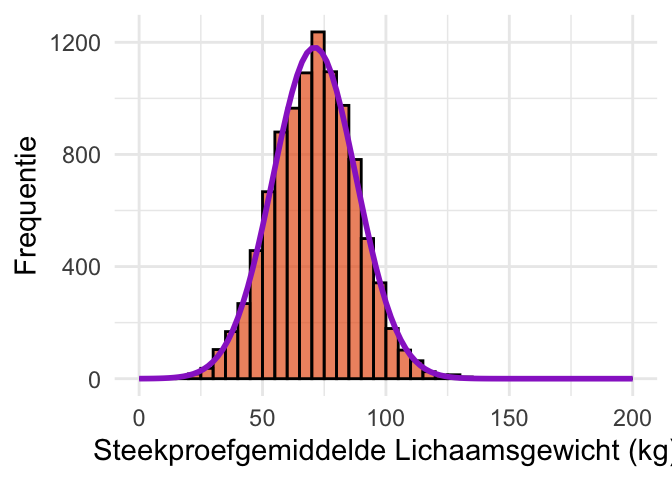
Om dat te laten zien, voeren we weer een aantal simulaties uit. In Figuur 24.9 (a) is de verdeling van lichaamsgewicht (Weight) uit de dataset NHANES weergegeven. We stellen ons voor dat deze verdeling de populatie voorstelt van personen uit de VS, waarvan wij het gemiddelde niet weten. Om iets te weten te komen over het gemiddelde van die populatie voeren we een steekproef uit. Figuur 24.9 (b) laat een kleine steekproef zien van \(n = 3\) personen, en Figuur 24.9 (c) een iets grotere steekproef van \(n = 30\). Paarse lijntjes geven het steekproefgemiddelde aan.
Wat zegt zo’n steekproefgemiddelde over het gemiddelde van de populatie? In Paragraaf 24.5.1 hebben we dat onderzocht door heel vaak een steekproef trekken en telkens het steekproefgemiddelde uitrekenen. De verdeling van die steekproefgemiddelden vertelde ons hoe ver een steekproefgemiddelde typisch van het populatiegemiddelde afligt. Voor een variabele die in de populatie normaal verdeeld is, hadden we gezien dat het steekproefgemiddelde dat óók is. Dat feit hebben we gebruikt in de afleiding van de formule voor het BHI, Vergelijking 24.9.
De verdeling van lichaamsgewicht is echter bimodaal en bovendien scheef. De aannames van het Normale Model zijn dus niet van toepassing. Hoe zou de steekproevenverdeling van het gemiddelde er in dit geval uitzien?
Om dat te demonstreren nemen we heel vaak een steekproef van gewichten uit de NHANES dataset, berekenen steeds het gemiddelde, en tekenen een histogram van de steekproefgemiddelden. Het resultaat voor steekproeven met \(n = 3\) is weergegeven in Figuur 24.9 (d), het resultaat voor \(n = 30\) in Figuur 24.9 (e).
Het resultaat is heel verrassend: hoewel de populatie verre van normaal verdeeld is, ziet de verdeling van de steekproefgemiddelden er wel behoorlijk normaal uit! Om dat te illustreren is in de figuren in het paars een normale verdeling toegevoegd.
(a) Histogram van lichaamsgewicht (Weight) in de NHANES dataset.
(b) Steekproef met \(n = 3\). De paarse streep geeft het steekproefgemiddelde aan.
(c) Steekproef met \(n = 30\). De paarse streep geeft het steekproefgemiddelde aan.
(d) Verdeling van het steekproefgemiddelde met \(n = 3\). De paarse lijn is een normale verdeling.
(e) Verdeling van het steekproefgemiddelde met \(n = 30\). De paarse lijn is een normale verdeling.
Figuur 24.9: Steekproeven uit een populatie die niet normaal verdeeld is. We nemen steekproeven uit lichaamsgewichten (Weight) uit de dataset NHAMES. Hoewel de populatie niet normaal verdeeld is (Figuur 24.9 (a)), zijn de verdelingen van het steekproefgemiddelde dat bij benadering wel (Figuur 24.9 (d) en Figuur 24.9 (e)).
Waar komen die normale verdelingen vandaan? Intuïtief kun je je misschien voorstellen dat de bimodaliteit van de populatie niet terug te zien is in de gemiddelden van de steekproeven. Als de steekproef groot genoeg is, zal de steekproef typisch zowel kinderen bevatten (uit de linkerpiek van de verdeling) als volwassenen (uit de rechterpiek van de verdeling). Het gemiddelde komt daardoor meestal in het midden terecht.
Wiskundig kan daadwerkelijk worden aangetoond dat de verdeling van de steekproefgemiddelden meer op een normale verdeling gaat lijken naarmate de steekproef groter wordt; dat geldt ongeacht de verdeling van de populatie (behalve in heel pathologische gevallen waarover wij ons niet druk hoeven te maken). Dit volgt uit de centrale limietstelling, die we ook al kort tegenkwamen in Paragraaf 23.8.2.
Een consequentie van deze stelling is dat de afleiding van de formule voor het BHI (Paragraaf 24.8) bij goede benadering ook opgaat als de verdeling van de variabele in de populatie niet normaal is, mits \(n\) groot genoeg is. Precies hoe groot \(n\) moet zijn hangt af van de mate waarin de verdeling van de populatie afwijkt van de normale verdeling. Als de populatieverdeling heel erg scheef is en/of extreme uitbijters kent, dan is een grotere \(n\) nodig. Als vuistregel kun je aannemen dat bij steekproeven van \(n = 30\) of meer de formule voor het BHI ook van toepassing is als de populatie niet normaal verdeeld is. In Oefening 24.11 hieronder zul je zien dat zelfs bij behoorlijk vreemde verdelingen het BHI al bij veel kleinere \(n\) betrouwbaar is.
Wat als het statistische model echt niet van toepassing is?
We hebben hierboven gezien dat het Normale Model vaak correcte resultaten geeft zelfs als de variabele niet daadwerkelijk normaal verdeeld is. Maar wat nou als de verdeling van de variabele sterk van de normale verdeling afwijkt en het aantal waarnemingen beperkt is?
Er zijn verschillende opties. In deze cursus zullen we die niet in detail kunnen behandelen, maar het is belangrijk om te weten dat er oplossingen bestaan die je in een vervolgcursus zou kunnen leren. Hier zijn een paar voorbeelden:
Andere statistische modellen: Als de normale verdeling geen goed model is voor de toepassing, kunnen we een ander statistisch model formuleren dat uitgaat van een andere kansverdeling, zoals de Poisson-verdeling of de Binomiale verdeling (zie Paragraaf 23.12). Voor zulke aangepaste modellen gelden andere formules voor het BHI, die we hier niet zullen behandelen.
Transformeren van de variabele: Als een variabele \(X\) rechts-scheef is, kan soms \(\log{X}\) of \(\sqrt{X}\) wél ongeveer normaal verdeeld zijn. Als \(X\) een grote waarde heeft, dan is \(\log{X}\) een stuk kleiner, en \(\sqrt{X}\) ook. Uitbijters in de rechter-staart van de verdeling van \(X\) worden daardoor minder extreem, waardoor de staart als het ware wordt ingetrokken. Een functie zoals de log toepassen op alle waarnemingen heet het transformeren van de variabele. Als de getransformeerde variabele wél ongeveer normaal verdeeld is, kun je een het Normale Model dus wel op die variabele toepassen. Dat levert je een BHI op voor de getransformeerde variabele.
Computer-intensieve methoden: Als het statistische model te ingewikkeld is, dan kan het moeilijk zijn om een formule af te leiden voor het BHI. Maar in die gevallen kun je vaak wel een BHI schatten door middel van simulaties. Voorbeelden van zulke computer-intensieve methoden zijn bootstrapping, **likelihood*-methoden, en methoden gebaseerd op Monte-Carlo-simulaties**.
24.11 Samenvatting
Betrouwbaarheidsintervallen algemeen
Puntschatting: Een waarde die berekend is op basis van een steekproef of een reeks metingen, en als schatting dient voor een populatieparameter.
95%-betrouwbaarheidsinterval: Een interval om de puntschatter dat zo berekend is dat het in 95% van de gevallen de populatieparameter bevat. Geeft de onzekerheid in de schatting aan.
Het Normale Model
Van een steekproef van \(n\) eenheden is de variabele \(X\) gemeten.
Het Normale Model neemt dan aan dat:
De variabele \(X\) is normaal verdeeld in de populatie.
Iedere waarde \(X_i\) van de steekproef is onafhankelijk uit deze normale verdeling getrokken.
Hetzelde model kan ook gebruikt worden voor \(n\) herhaalde metingen die door toevallige meetfouten van elkaar verschillen:
De uitkomsten van de metingen zijn normaal verdeeld.
Iedere meting \(X_i\) is onafhankelijk uit die normale verdeling getrokken.
Notatie
Populatieparameters: Eigenschappen van de verdeling van de populatie waaruit de steekproef wordt getrokken. Parameters worden in de statistiek meestal aangeduid met een Griekse letter.
Voorbeelden: gemiddelde \(\mu_X\) en standaarddeviatie \(\sigma_X\) van de populatie.
Eigenschappen van steekproeven: Eigenschappen van een steekproef worden meestal aangeduid met een gewone (Romaanse) letter. Het gemiddelde van een steekproef wordt aangeduid met \(\overline{X}\), de standaarddeviatie van de steekproef met \(s_X\).
95%-betrouwbaarheidsintervallen voor het populatiegemiddelde
We hebben variabele \(X\) gemeten voor een steekproef van grootte \(n\) uit een populatie. We gebruiken die steekproef om het populatiegemiddelde \(\mu_X\) te schatten.
Of:
We hebben een serie van \(n\) metingen (\(X_i\)) van een grootheid en gebruiken die metingen om de verwachtingswaarde \(\mu_X\) te schatten.
We maken gebruik van het Normale Model.
Dan is het 95%-betrouwbaarheidsinterval:
als de standaarddeviatie van de populatie \(\sigma\) bekend is (zeer ongebruikelijk!):
Bedenk: Verwacht ik dat de Normale verdeling deze variabele redelijk kan beschrijven?
Voorbeelden van gevaren:
De verdeling is
scheef
multimodaal
beperkt tot een interval
discreet
Bedenk: Is het te verwachten dat de waarnemingen (bijna) onafhankelijk zijn?
Voorbeelden van gevaren:
pseudoreplicatie
tijdsseries
de steekproef bestaat uit groepjes
Bestudeer de gegevens om afwijkingen van de normale verdeling te ontdekken
Bereken kengetallen en beoordeel ze.
Visualiseer de gegevens en beoordeel ze.
Maak een QQ-plot en beoordeel die.
Robuustheid van het Normale Model
Als \(n\) groot is, is de steekproevenverdeling van het gemiddelde ongeveer normaal verdeeld, ook als de verdeling van de variabele in de populatie dat niet is. (Centrale limietstelling) Daardoor is het Normale Model vaak ook bruikbaar als de populatie niet normaal verdeeld is.
Vuistregel: als \(n >30\) werken de formules voor het BHI ook goed voor populaties die niet normaal verdeeld zijn.
Een interval om de puntschatter dat zo berekend is dat het in 95% van de gevallen de populatieparameter bevat. Geeft de onzekerheid in de schatting aan.
centrale limietstelling
central limit theorem
Wiskundige stelling die zegt dat het gemiddelde van een groot aantal kansvariabelen convergeert naar een normale verdeling.
repliceren
replicate
herhalen (van een meting of experiment)
pseudoreplicatie
pseudoreplication
Het herhalen van een metingen of experiment op een manier waardoor de metingen niet onafhankelijk zijn.
puntschatting
point estimate
Een schatting zonder betrouwbaarheidsinterval.
standaardfout van het gemiddelde
Standard Error of the Mean (SEM)
Schatting van de standaarddeviatie van het steekproefgemiddelde.
statistische modellen
statistical models
Modellen van de kansprocessen die verantwoordelijk zijn voor de onzekerheid in de gegevens.
steekproevenverdeling van het gemiddelde
sampling distribution of the mean
Het nemen van een steekproef is een kansproces; het gemiddelde van de steekproef een kansvariabele. De steekproevenverdeling van het gemiddelde is de kansverdeling van steekproefgemiddelden.
24.13 Opgaven
Oefening 24.9 (BHI van een steekproef tomaten)
Van zestien aselect gekozen tomaten uit een kas is het gewicht bepaald. Het gemiddelde gewicht in de steekproef is gelijk aan 44,1 g; de standaardafwijking van de steekproef is gelijk aan 8,6 g. Bepaal het 95%-betrouwbaarheidsinterval voor het gemiddelde gewicht \(\mu_X\) van dergelijke tomaten. (Je mag uit gaan van het Normale Model.)
Oefening 24.10 (Een schatting voor de gemiddelde rusthartslag.)
In Paragraaf 24.10 hebben we gezien hoe je kunt onderzoeken of een steekproef van een variabele afwijkingen laat zien van de normale verdeling. Als voorbeeld ga je de variabele Pulse (hartslagfrequentie) onderzoeken uit de NHANES-database.
Om te beginnen: zou je bij voorbaat verwachten dat een normale verdeling een redelijk model is voor de verdeling van hartslagfrequenties?
Zijn er redenen om daaraan te twijfelen?
Laad eerst het pakket NHANES in zoals je dat al vaak hebt gedaan.
Voor sommige personen in de dataset is geen hartslagfrequentie ingevoerd. In sommige regels staat daarom NA (not available). Selecteer alle gegevens die wel beschikbaar zijn:
# Verwijder missende waarden van de variabele 'Pulse'pulse_data <-na.omit(NHANES$Pulse)
Hoeveel waarnemingen blijven er over?
Visualiseer de verdeling met een histogram en een boxplot. Zie je afwijkingen van een normale verdeling?
Bestudeer kengetallen voor de gegevens.
Zijn de maten van locatie zoals verwacht?
Vergelijk de mediaan met het gemiddelde; wat zegt je dat?
Zijn de maten van spreiding (standaarddeviatie, IKA) ongeveer wat je had verwacht?
Voeg een Normale QQ-plot toe en beoordeel die.
Gebruik de functie t.test() om het BHI te berekenen.
Kun je het berekende BHI met een gerust hart gebruiken?
Oefening 24.11 (Robuustheid van het Normale Model controleren)
In Paragraaf 24.10.4 heb je geleerd over de Centrale Limietstelling. Die stelling zegt dat bij grote steekproeven de steekproevenverdeling van het gemiddelde bij benadering normaal verdeeld is, zelfs als de verdeling van populatie dat niet is. We gaan dat in deze opgave met een voorbeeld controleren.
We zagen dat de variabele lichaamsgewicht (Weight) in de dataset NHANES bimodaal was (Figuur 24.9 (a)). Het idee is om de personen in deze dataset te beschouwen als een populatie, en uit deze populatie een steekproef van \(n = 30\) personen te nemen. Op basis van deze steekproef berekenen we een BHI. Als de berekening van het BHI robuust is (ondanks de bimodale verdeling), ligt het ware gemiddelde van de populatie 95% van de keren dat we dit doen binnen het BHI.
Maak een nieuw script in R. Laad daarin de library NHANES.
Voor sommige personen in de dataset mist het gewicht en is NA ingevuld. Sla de gewichten op in een vector gewichten, maar verwijder de NA’s, op dezelfde manier als in Oefening 24.10.
We gaan de gewichten in de dataset nu gebruiken als een populatie waaruit we een kleinere steekproef nemen.
Voeg een regel toe die het gemiddelde van deze “populatie” berekent.
Voeg een regel toe waarmee je een aselecte steekproef van 30 gewichten selecteert uit de populatie:
# replace = FALSE zorgt ervoor dat we niet twee keer dezelfde persoon# in de steekproef kunnen opnemensteekproefgrootte <-30steekproef <-sample( gewichten, size = steekproefgrootte, replace =FALSE )steekproef
Bereken van die steekproef het BHI, zoals je dat hierboven geleerd hebt, met de functie t.test().
Ligt het ware populatiegemiddelde in het berekende BHI?
Als de formule van het Normale Model werkt, zou bij 95% van de keren dat je een steekproef en een BHI berekent, het ware populatiegemiddelde in het interval moeten liggen.
Voer de code een paar keer uit om te zien of dat ongeveer kan kloppen.
Om het BHI goed te controleren, willen we de code heel vaak uitvoeren en tellen hoe vaak het populatiegemiddelde in het interval ligt. Het script hieronder doet dat. Kopieer het, bestudeer het, en voer het uit op je laptop. Lijkt de formule voor het BHI goed te werken?
Code
library("NHANES")data(NHANES)# PARAMETERSaantal_steekproeven <-50000# Aantal steekproevensteekproefgrootte <-30# Grootte van elke steekproef# POPULATIEGEGEVENS gewichten <-na.omit(NHANES$Weight) # filter NA's wegpopulatiegemiddelde <-mean(gewichten) # bereken populatiegemiddelde# SIMULATIE VOORBEREIDEN# Functie om het BHI voor een steekproef te berekenen# en te controleren of het populatiegemiddelde # binnen het betrouwbaarheidsinterval valt.controleer_bhi <-function( steekproef, populatiegemiddelde) { resultaten.t.test <-t.test(steekproef) bhi <- resultaten.t.test$conf.int in_interval <- populatiegemiddelde >= bhi[1] && populatiegemiddelde <= bhi[2]return(in_interval)}# Logical vector om de resultaten in op te slaanresultaten <-logical(aantal_steekproeven)# SIMULEER STEEKPROEVENfor (i in1:aantal_steekproeven) { steekproef <-sample( gewichten, size = steekproefgrootte, replace =FALSE ) resultaten[i] <-controleer_bhi(steekproef, populatiegemiddelde)}# Bereken en print percentageprint("Percentage steekproeven waarbij populatiegemiddelde binnen het BHI valt:")print(mean(resultaten)*100)
Bij kleine steekproeven verwachten we dat het BHI zou kunnen afwijken. Voer het script opnieuw uit, maar dan met steekproeven van grootte 4. Wat concludeer je?
Bron: CBS, gedownload op 17 januari 2025. De gegevens zijn voor het jaar 2022.↩︎
Ramdani, K., M. Kouidri, M. L. Ouakid, and M. Houhamdi. “Breeding Biology of the Chaffinch Fringilla Coelebs Africana in the El Kala National Park (North East Algeria).” Arxius de Miscel·lània Zoològica, July 7, 2019, 109–21. Breeding biology.↩︎