voor een gegeven probleem de nulhypothese en de alternatieve hypothese formuleren;
uitleggen wat de kansverdeling van een statistiek “onder de nulhypothese” is;
uitleggen wat een \(P\)-waarde is en hoe die gebruikt wordt om bewijs tegen een nulhypothese te kwantificeren;
uitleggen dat iedere hypothesetoets gebaseerd is op een statistisch model;
de algemene anatomie van hypothesetoetsen beschrijven;
uitleggen dat hypothesetoetsen vaak gebruikt worden als besluitprocedures, waarbij een nulhypothese “verworpen” wordt als de \(P\)-waarde kleiner is dan een vooraf gekozen significantieniveau;
uitleggen wat daarvan de voor- en nadelen zijn;
fouten van type I en type II onderscheiden.
25.2 De ontdekking van John Arbuthnot
Figuur 25.1: John Arbuthnot, geschilderd door John Kneller. Bron: WikiMedia Commons.
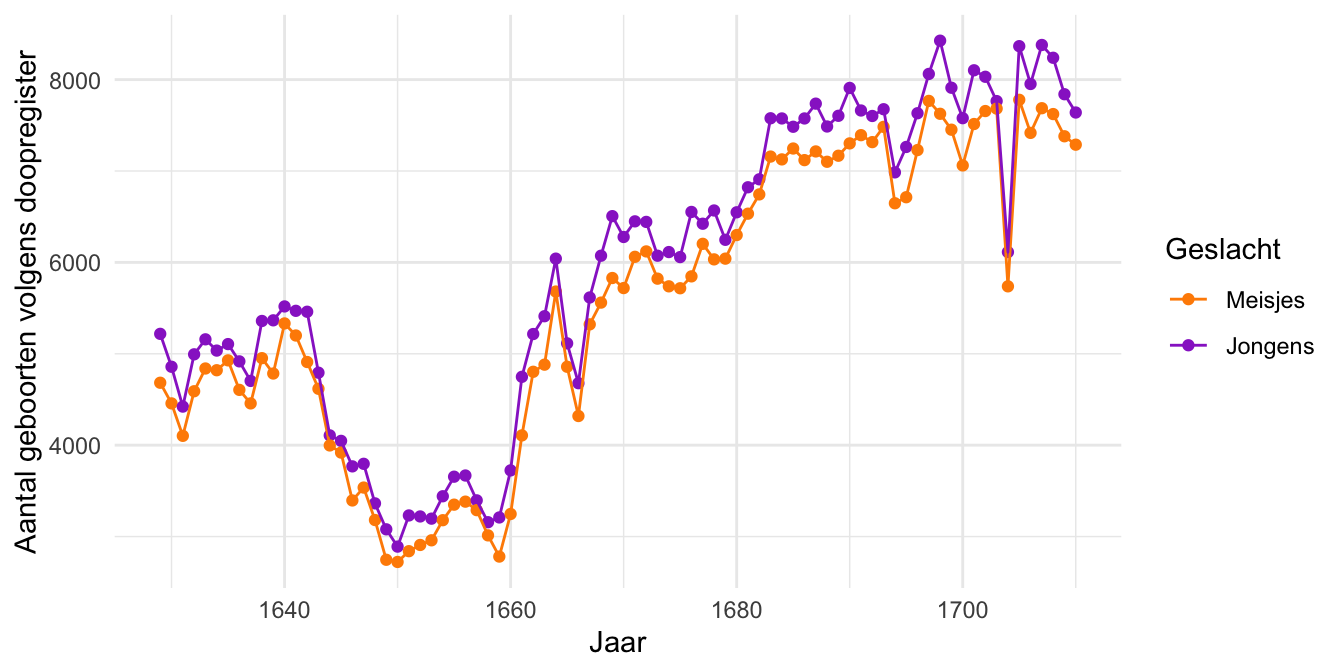
In het jaar 1710 deed de Schotse arts en schrijver John Arbuthnot een interessante ontdekking toen hij de geboortecijfers van Londen over de periode 1629–1710 bestudeerde.1 Tot zijn verbazing waren er in die periode ieder jaar meer jongetjes dan meisjes geboren! Figuur 25.2 laat de cijfers zien die destijds op Arbuthnots bureau lagen.
Code
# Laad de Arbuthnot-datadata("Arbuthnot")# Zet de data om in lang formaat voor ggplot2arbuthnot_lang <-pivot_longer( Arbuthnot,cols =c("Males", "Females"),names_to ="Geslacht",values_to ="Geboorten")# Maak de plotggplot(arbuthnot_lang, aes(x = Year, y = Geboorten, color = Geslacht)) +geom_point() +# Voeg punten toe voor ruwe datageom_line() +# Voeg lijnen toe om trends te laten zienlabs(title =NULL,x ="Jaar",y ="Aantal geboorten volgens doopregister",color ="Geslacht" ) +scale_color_manual(values =c("Males"="DarkOrchid", "Females"="darkorange"),labels =c("Males"="Jongens", "Females"="Meisjes") ) +theme_minimal()
Figuur 25.2: Geboortecijfers (doopregister) van Londen in de periode 1629–1710.
De cijfers suggereren dat de kans op een jongetje structureel groter is dan de kans op een meisje. Maar er is ook een andere verklaring: zelfs als iedere baby met gelijke kans een jongetje of meisje is, kan het gebeuren dat er een paar jaar achtereen toevallig meer jongetjes worden geboren. Was de periode 1629–1710 misschien zo’n toevallige periode?
Arbuthnot zag in dat het wel erg toevallig zou zijn als de balans 82 jaar achter elkaar naar dezelfde kant was doorgeslagen. Om dat aan te tonen deed hij de volgende berekening. Neem aan dat de kans op meer jongetjes dan meisjes in een gegeven jaar gelijk is aan \(\frac{1}{2}\). De kans dat dit 82 keer achter elkaar gebeurt is gelijk aan de kans om met een muntje 82 keer achter elkaar “kop” te gooien, oftewel \((\frac{1}{2})^{82} = 2 \times 10^{-25}\).2
Is dat een kleine kans? Als je vanaf nu iedere seconde een muntje gooit, zul je gemiddeld \(3 \times 10^{17}\) jaar moeten wachten op zo’n lucky streak. (Dat is ongeveer 22 miljoen keer langer dan de huidige leeftijd van het heelal.)
Dat die kans zo klein is, geeft aan dat “toeval” wel mogelijk is, maar geen geloofwaardige verklaring. Zo toonde Arbuthnot aan dat er iets anders aan de hand moest zijn.
Arbuthnots argumentatie tegen “toeval” was zijn tijd ver vooruit. Die redenering is namelijk een voorbeeld van een hypothesetoets—een techniek die pas in de 20e eeuw formeel werd ontwikkeld!
Oefening 25.1 (Vijf jaar)
Stel dat Arbuthnot gegevens tot zijn beschikking had voor slechts 5 jaar (in plaats van 82). In alle vijf de jaren waren de baby-jongetjes in de meerderheid.
Als in werkelijkheid iedere baby met gelijke kans een jongetje of een meisje wordt, wat is dan de kans dat vijf keer achter elkaar de jongetjes in de meerderheid zijn?
Wat zou jij op basis van die kans concluderen? Zou je “toeval” in dit geval ook afschrijven als een mogelijke verklaring?
25.3 Hypothesetoetsen
Een hypothese is een veronderstelling of voorlopige verklaring. Hypotheses vormen vaak de aanleiding voor wetenschappelijke studies en kunnen, afhankelijk van de onderzoeksresultaten, worden bevestigd, verworpen of aangepast.
In zijn argument toetst Arbuthnot de hypothese dat er in elk willekeurig jaar een gelijke kans bestaat op meer jongetjes of juist meer meisjes. Zijn berekeningen laten zien dat, áls deze hypothese zou kloppen, de waargenomen geboortecijfers extreem onwaarschijnlijk zouden zijn. Dat resultaat wordt vervolgens aangevoerd als bewijs tegen de hypothese.
In het algemeen is een hypothesetoets een methode om te evalueren in welke mate een verzameling waarnemingen —zoals meetgegevens of steekproeven— bewijs levert tegen een hypothese.
BelangrijkDefinitie: hypothesetoets
Een hypothesetoets is een methode die gebruikt wordt om te evalueren in hoeverre een verzameling waarnemingen —bijvoorbeeld meetresultaten of gegevens uit een steekproef— bewijs levert tegen een specifieke hypothese.
25.4 De nulhypothese \(H_\textrm{0}\) en de alternatieve hypothese \(H_\textrm{A}\)
Laten we de kans dat er in een gegeven jaar meer jongetjes geboren worden dan meisjes \(p_\textrm{J}\) noemen. Arbuthnot wilde aantonen dat \(p_\textrm{J}\)niet gelijk is aan \(\frac{1}{2}\). Hij deed dat door bewijs te leveren tegen de hypothese dat dat wel zo was.
Die hypothese dat \(p_\textrm{J} = \frac{1}{2}\) is de hypothese van een scepticus3 die niet zomaar bereid is te geloven dat er verschil is tussen de kans op jongetjes en meisjes. Zo’n sceptische hypothese wordt een nulhypothese genoemd en wordt vaak genoteerd als \(H_\textrm{0}\). Het doel van iedere hypothesetoets is om te zien in hoeverre de gegevens bewijs leveren tegen de \(H_\textrm{0}\).
Tegenover de nulhypothese staat de alternatieve hypothese, \(H_\textrm{A}\). \(H_\textrm{A}\) is de ontkenning van \(H_\textrm{0}\). Als \(H_\textrm{0}\) de hypothese is dat \(p_\textrm{J} = \frac{1}{2}\), dan is \(H_\textrm{A}\) de hypothese dat \(p_\textrm{J} \neq \frac{1}{2}\). Bewijs tegen \(H_\textrm{0}\) geldt als bewijs vóór \(H_\textrm{A}\).4
Oefening 25.2 (Wat is de nulhypothese?)
Een farmaceutisch bedrijf heeft een vaccin ontwikkeld en doet onderzoek naar het effect daarvan op de kans op infectie.
Een groep proefpersonen wordt gevaccineerd, en een andere groep niet. Beide groepen worden regelmatig getest en het aantal infecties wordt nauwkeurig bijgehouden.
Hier volgen twee hypothesen:
A. De kans op infectie is voor proefpersonen in beide groepen even groot.
B. De kans op infectie is voor proefpersonen in beide groepen niet even groot.
Welke van deze twee hypotheses is de nulhypothese, welke de alternatieve hypothese?
Welke hypothese wil het bedrijf aantonen?
Tegen welke hypothese hoopt het bedrijf bewijs te vinden?
25.5 De kansverdeling “onder \(H_\textrm{0}\)”
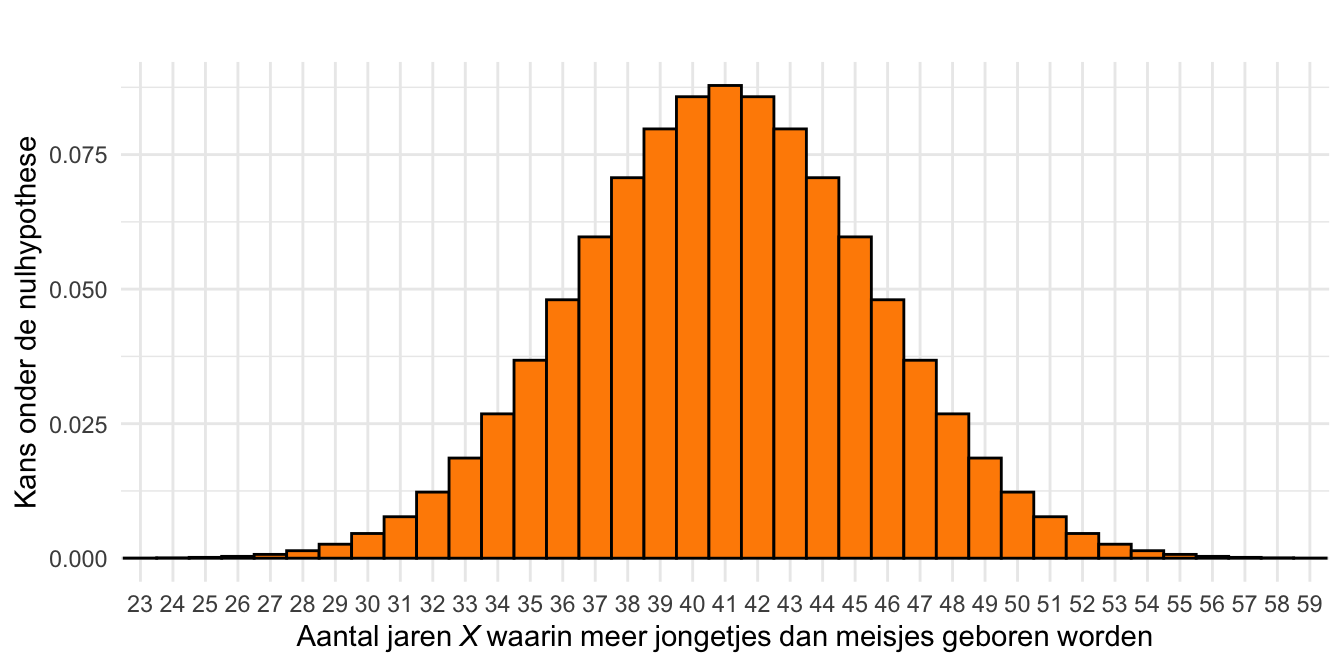
Laten we het aantal jaren waarin jongetjes in de meerderheid zijn \(X\) noemen. Als we ervan uitgaan dat \(H_\textrm{0}\) waar is, dan kunnen we de kans op \(X\) voor iedere mogelijke waarde van 0 tot 82 uitrekenen.5 Het resultaat is weergegeven in Figuur 25.3. Deze kansverdeling laat zien dat “onder \(H_\textrm{0}\)” (dat betekent: onder de aanname dat \(H_\textrm{0}\) waar is) een waarde van \(X\) tussen, zeg, 32 en 50 redelijk in de verwachting ligt. Waarden van \(X\) die verder in de staarten van de verdeling liggen zijn onder \(H_\textrm{0}\) onwaarschijnlijk. Vind je in werkelijkheid een waarde ver in één van de staarten dan is dat dus een indicatie dat \(H_\textrm{0}\) niet waar is.
Code
# Parameters definiëren voor de binomiale verdelingn <-82p <-0.5mean <- n * psd <-sqrt(n * p * (1- p))standaard_deviaties <-4# Aantal standaarddeviaties als parameter# Limieten voor de x-as bepalen (ongeveer 3 standaarddeviaties rond het gemiddelde)x_min <-ceiling(mean - standaard_deviaties * sd)x_max <-floor(mean + standaard_deviaties * sd)# Mogelijke uitkomsten en kansen berekenenuitkomsten <-seq(x_min, x_max)kansen <-dbinom(uitkomsten, size = n, prob = p)# Data frame maken met de uitkomsten en kansenkansen_binomiaal <-data.frame(uitkomsten =factor(uitkomsten),kansen = kansen)# Maak de plotverdelingBinomiaal <-function(kleur) {ggplot(kansen_binomiaal, aes(x = uitkomsten, y = kansen)) +geom_bar(stat ="identity", # Balken representeren kanswaarden directwidth =1, # Volledige breedte van de categoriefill = kleur, # Kleur voor de balkencolor ="black"# Randkleur voor de balken ) +labs(title ="",x =expression(Aantal~jaren~italic(X)~waarin~meer~jongetjes~dan~meisjes~geboren~worden), # Titel voor de x-asy ="Kans onder de nulhypothese"# Titel voor de y-as ) +theme_minimal() # Minimalistisch thema voor de plot}# Kleur voor de balkenkleur <- opvulkleur# Plot de binomiale verdelingverdelingBinomiaal(kleur)
Figuur 25.3: De kansverdeling onder \(H_\textrm{0}\) van het aantal jaren (van in totaal 82 jaren) waarin meer jongens dan meisjes geboren worden.
Oefening 25.3 (De kansverdeling onder \(H_\textrm{0}\))
We vragen je niet om de berekeningen te reproduceren waarmee de kansen van Figuur 25.3 berekend zijn. Maar de volgende eigenschappen kun je prima zelf beredeneren.
Wat was ook al weer de nulhypothese die hoort bij Figuur 25.3?
Als die nulhypothese waar is (dus “onder \(H_\textrm{0}\)”), in hoeveel jaren verwacht je dan dat de jongens in de meerderheid zijn? (Dat wil zeggen: wat is de verwachtingswaarde van \(X\)?) Klopt dit met de verdeling in Figuur 25.3?
Kun je begrijpen waarom Figuur 25.3 een symmetrische vorm heeft?
25.6 De overschrijdingskans of \(P\)-waarde
Hoe opmerkelijk of onverwacht een bepaalde waarde van \(X\) is onder \(H_\textrm{0}\) kan worden uitgedrukt in een getal dat de overschrijdingskans of \(P\)-waarde genoemd wordt. (In dit boek schrijven we de \(P\) met een hoofdletter, maar in andere literatuur kom je ook \(p\) tegen.) De \(P\)-waarde is gedefinieerd als de kans onder \(H_\textrm{0}\) om een uitkomst te vinden die minstens even extreem is als de waarde die daadwerkelijk gevonden is. Dat getal kan gebruikt worden als maat voor het bewijs tegen \(H_\textrm{0}\). Een kleine \(P\)-waarde wordt geïnterpreteerd als sterk bewijs tegen \(H_\textrm{0}\).
BelangrijkDefinitie: de \(P\)-waarde
De overschrijdingskans of \(P\)-waarde is de kans onder de nulhypothese op een uitkomst die minstens zo extreem is als de uitkomst die daadwerkelijk heeft plaatsgevonden.
Laten we een voorbeeld nemen. Arbuthnot had 82 jaar aan geboortecijfers. In alle 82 jaren werden er meer jongetjes geboren dan meisjes. Stel dat dit maar in 47 jaren het geval was geweest. Natuurlijk is 47 nog steeds meer dan de helft van de jaren (\(82/2 = 41\)), maar het is een stuk beter voor te stellen dat deze afwijking puur toevallig ontstaat. Hoe sterk was het bewijs tegen \(H_\textrm{0}\) bij \(X = 47\) geweest?
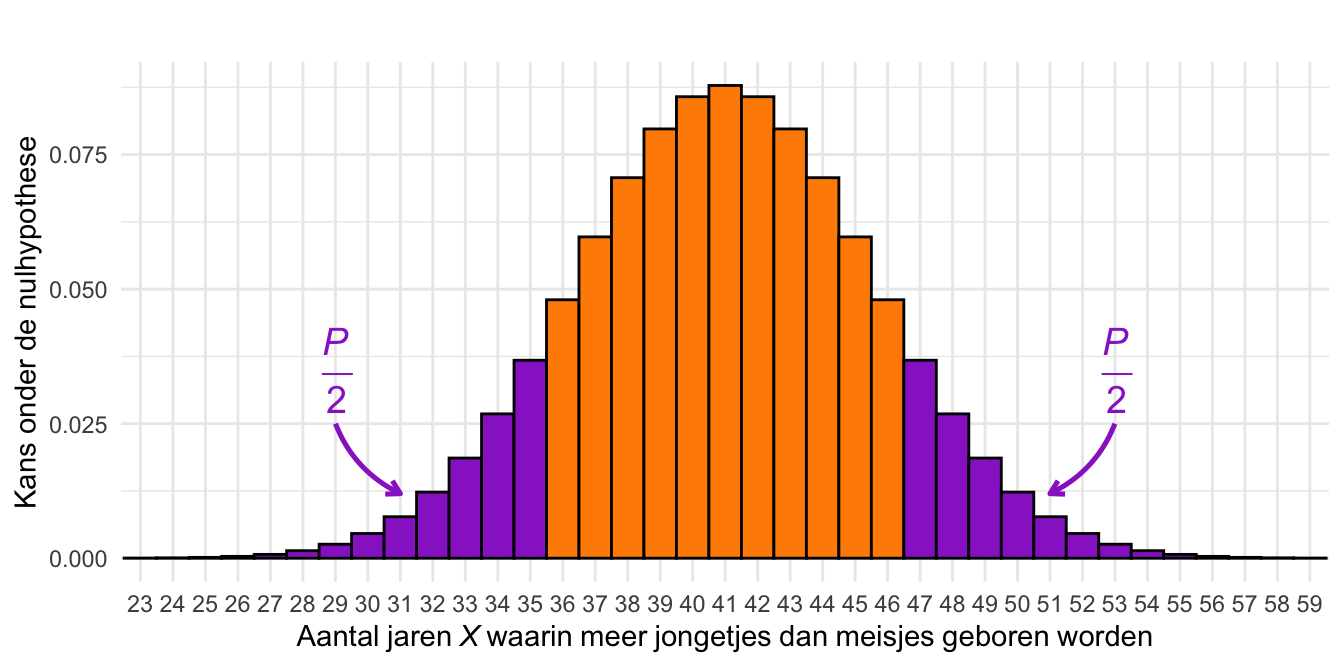
Om dat te bepalen, berekenen we de \(P\)-waarde. De \(P\)-waarde is de kans om, aangenomen dat \(H_\textrm{0}\) waar is, een waarde van \(X\) te vinden die minstens zo extreem is als de werkelijke observatie \(X = 47\). Dat zijn de uitkomsten die minstens even ver als \(X = 47\) in de staarten van de verdeling liggen. Die kans is in Figuur 25.4 weergegeven als de oppervlakte van de paarse staven.
Code
m <-41X <-47y_pijl <-0.025y_end_pijl <-0.012# Maak een vector van kleurenkleur_vector <-ifelse(abs(uitkomsten - m) <abs(m - X), opvulkleur, "DarkOrchid" )verdelingBinomiaal(kleur_vector) +# Kromme pijltjes toevoegenannotate("curve",x =7, y = y_pijl, xend =9, yend = y_end_pijl, curvature =0.2,arrow =arrow(length =unit(0.2, "cm")),color = lijnkleur1,size =0.9 ) +annotate("curve",x =31, y = y_pijl, xend =29, yend = y_end_pijl,curvature =-0.2,arrow =arrow(length =unit(0.2, "cm")),color = lijnkleur1,size =0.9 ) +# Annotaties toevoegenannotate("text", x =7,y = y_pijl +0.01, # Plaats annotatie net boven de pijllabel =expression(frac(italic(P),2)),color = accentkleur2,hjust =0.5,size =5 ) +annotate("text",x =31,y = y_pijl +0.01, # Plaats annotatie net boven de pijllabel =expression(frac(italic(P),2)),color = accentkleur2,hjust =0.5,size =5 )
Figuur 25.4: Illustratie van de \(P\)-waarde voor de waarneming \(X = 47\). De staven geven de kansverdeling onder \(H_\textrm{0}\) weer. De totale oppervlakte van de paarse staven is de \(P\)-waarde. De kansverdeling is symmetrisch; daarom hebben beide paarse staarten een oppervlakte van \(P/2\).
We kunnen de \(P\)-waarde dus berekenen door de kansen van alle paarse staven op te tellen: \[
\begin{align}
P & = \textrm{Pr}\!\left[X \le 35\right] + \textrm{Pr}\!\left[X \ge 47\right]\\
& = \left(\textrm{Pr}\!\left[X = 0\right] + \ldots + \textrm{Pr}\!\left[X = 35\right]\right) + \left(\textrm{Pr}\!\left[X = 47\right] + \ldots + \textrm{Pr}\!\left[X = 82\right]\right).
\end{align}
\] Na veel rekenwerk vinden we in dit geval dat \[
P = 0{,}224.
\]
Deze \(P\)-waarde zegt dat, als \(H_\textrm{0}\) waar is, een \(X\)-waarde die minstens zo extreem is als \(X = 47\) een kans heeft van \(P = 0{,}224\). Dat wil zeggen dat \(X = 47\) onder \(H_\textrm{0}\) niet heel erg verrassend is: we verwachten dit soort afwijkingen vaker dan 1 op de 5 keer. Deze \(P\)-waarde vormt dan ook nauwelijks bewijs tegen \(H_\textrm{0}\). Als Arbuthnot \(X = 47\) had gevonden, dan had Arbuthnot niet kunnen uitsluiten dat dit simpelweg toeval was.
In werkelijkheid waren jongens in alle 82 jaren in de meerderheid. De \(P\)-waarde is in dat geval \[P = \textrm{Pr}\!\left[X = 82\right] + \textrm{Pr}\!\left[X = 0\right] = 4\times 10^{-25}.\] (De gebeurtenis \(X = 0\) is precies even onwaarschijnlijk als de gebeurtenis \(X = 82\) en moet in de berekening van de \(P\)-waarde dus ook worden meegenomen.) Die kans is zo klein dat \(H_\textrm{0}\) er volstrekt ongeloofwaardig door wordt. \(X = 82\) is dus wél sterk bewijs tegen \(H_\textrm{0}\).
Oefening 25.4 (\(P\)-waarde voor \(X = 34\))
Stel dat de jongens in 34 jaren in de meerderheid waren, en in de andere jaren in de minderheid. (Oftewel: de toetsingsgrootheid is \(X = 34\).)
Welke uitkomsten zijn net zo extreem of extremer dan \(X = 34\)?
Welke staven in Figuur 25.4 horen bij die uitkomsten?
In de tekst hierboven is vermeld wat de totale oppervlakte is van de paarse staven in Figuur 25.4. Gebruik die waarde en Figuur 25.4 om de \(P\)-waarde te schatten de hoort bij de waarneming \(X = 34\).
Hoe sterk vind je dat bewijs?
25.7 Significant bewijs tegen \(H_\textrm{0}\)
Hoe klein moet de \(P\)-waarde zijn om als sterk bewijs tegen \(H_\textrm{0}\) te gelden?
In de biologie en veel andere vakgebieden wordt vaak als richtlijn gebruikt dat een \(P\)-waarde opmerkelijk is als deze kleiner of gelijk is aan \(0{,}05\). Dan wordt het resultaat statistisch significant genoemd.
Een \(P\)-waarde van 0,05 betekent dat je onder \(H_\textrm{0}\) zo’n extreme uitkomst maar 1 op de 20 keer verwacht. Dat is een kleine kans; een \(P\)-waarde van 0,05 is dus zeker een reden om nog eens kritisch naar de \(H_\textrm{0}\) te kijken. Het woord “significant” drukt dat goed uit.
Maar, gebeurtenissen met een kans van 1 op 20 zijn ook weer niet zó bijzonder. Een \(P\)-waarde van 0,05 vormt op zichzelf geen heel zwaarwegend bewijs tegen \(H_\textrm{0}\). Als de \(P\)-waarde significant is, wil dat dus nog zeker niet zeggen dat \(H_\textrm{0}\) onwaar is en \(H_\textrm{A}\) dus waar.
Oefening 25.5 (“Significant” en “highly significant”.)
Sir Ronald A. Fisher (1890–1962)
Een van de grondleggers van de statistiek was Ronald A. Fisher (1890–1962). Fisher noemde een \(P\)-waarde significant als die kleiner was dan 0,05, en highly significant als die kleiner was dan 0,01.
Wat betekent \(P=0{,}01\) volgens de definitie van een \(P\)-waarde?
Vind jij highly significant een passende beschrijving voor zo’n \(P\)-waarde?
25.8 Iedere toets is gebaseerd op een statistisch model
Bij het berekenen van de kansverdeling van Figuur 25.3 en de \(P\)-waarde hierboven hebben we impliciet enkele aannames gemaakt.
Ten eerste namen we aan dat in elk jaar de kans op meer jongens dan meisjes gelijk was aan de kans op meer meisjes dan jongens. Zo kwamen we op de nulhypothese \(p_\textrm{J}=\frac{1}{2}\). Daarbij hebben we de (kleine) kans genegeerd dat er in een jaar precies evenveel jongens als meisjes geboren worden. Als we dat meenemen, moet \(p_\textrm{J}\) iets kleiner zijn dan \(\frac{1}{2}\).
Ten tweede zijn we er stilzwijgend vanuit gegaan dat de uitkomsten van verschillende jaren onafhankelijk zijn. Bij de berekening \(\textrm{Pr}\!\left[X = 82\right] = \left(\frac{1}{2}\right)^{82}\) maakten we namelijk gebruik van de vermenigvuldigingsregel (Vergelijking 22.7) en die is alleen geldig voor onafhankelijke gebeurtenissen. Deze aanname is op zich niet onredelijk, maar ook weer niet vanzelfsprekend. Bij allerlei dieren is aangetoond dat de geslachtsverhouding afhankelijk is van ecologische en fysiologische condities, zoals beschikbaarheid van voedsel, stress, en populatiedichtheid. Dat geldt mogelijk ook voor mensen: er zijn aanwijzingen dat tijdens periodes van hongersnood naar verhouding meer meisjes geboren worden.6 De kans op een jongetje zou dus van jaar tot jaar iets kunnen verschillen, en variatie daarin zou meerdere jaren kunnen aanhouden. Dan zouden de uitkomsten van de verschillende jaren niet onafhankelijk zijn.
De \(P\)-waarde die we voor de gegevens van Arbuthnot berekenden is dus weer gebaseerd op een statistisch model. Dat model is waarschijnlijk niet exact waar, maar goed genoeg: subtiele afwijkingen van het model zullen de minuscule \(P\)-waarde niet betekenisvol veranderen. In andere gevallen kan een verkeerd model de kansen wél sterk vertekenen. Evalueer de aannames dus altijd kritisch voordat je conclusies trekt.
Iedere hypothesetoets is gebaseerd op een statistisch model. Een kansmodel dat gebruikt wordt om een hypothese mee te toetsen wordt vaak een nulmodel genoemd:
BelangrijkHet nulmodel
Iedere hypothesetoets is gebaseerd op een statistisch model. Zo’n model is gestoeld op bepaalde aannames. Die aannames gaan zowel over de manier waarop de gegevens zijn verzameld als over de (biologische) werkelijkheid en zijn altijd nodig om de kansen op uitkomsten te kunnen bepalen.
Omdat bij een hypothesetoets altijd de kans “onder \(H_\textrm{0}\)” wordt berekend, wordt zo’n model een nulmodel genoemd.
De nulhypothese van een hypothesetoets is altijd een uitspraak over een parameter van het nulmodel. Bijvoorbeeld, onze berekeningen op basis van de gegevens van Arbuthnot gingen uit van het volgende model:
Ieder jaar zijn ofwel de jongetjes ofwel de meisjes in de meerderheid.
De uitkomst van ieder jaar is onafhankelijk van de uitkomst van andere jaren,
De kans op meer jongetjes dan meisjes is ieder jaar gegeven door parameter \(p_\textrm{J}\).
Deze aannames leggen samen de kansverdeling van \(X\) vast; daarmee kan dus ook de \(P\)-waarde berekend worden.
25.9 De algemene vorm van een hypothesetoets
Voor het uitvoeren van de hypothesetoets van Arbuthnot hebben we niet gebruik gemaakt van alle details van de gegevens. We weten voor ieder jaar het aantal jongetjes en meisjes dat geboren werd, maar bij de berekening maakten we alleen gebruik van het kengetal \(X\). Zo’n kengetal dat gebruikt wordt binnen een statistische toets wordt een toetsingsgrootheid genoemd.
Welke toetsingsgrootheid gebruikt wordt hangt af van de nulhypothese die getoetst wordt en van de methode die wordt toegepast.
Hoewel iedere toetsmethode een andere toetsingsgrootheid en andere berekeningen vereist, is de logische structuur van een hypothesetoets altijd hetzelfde. We presenteren die hier in het volgende zes-stappenplan.
BelangrijkDe anatomie van hypothesetoetsen in 6 stappen
Kies een statistisch model dat past bij de casus.
Stel de hypotheses \(H_\textrm{0}\) en \(H_\textrm{A}\) op in termen van een parameter van het statistisch model.
Kies een toetsingsgrootheid en bepaal de kansverdeling van de toetsinggrootheid aangenomen dat \(H_\textrm{0}\) waar is (“onder \(H_\textrm{0}\)”).
Bereken de toetsingsgrootheid op basis van de daadwerkelijke waarnemingen.
Bereken de \(P\)-waarde.
Trek je conclusies: hoe sterk is het bewijs tegen \(H_\textrm{0}\)?
In de laatste stap trek je je conclusies over \(H_\textrm{0}\) op basis van de \(P\)-waarde. Hoe kleiner \(P\) is, hoe opmerkelijker de gevonden toetsingsgrootheid is onder de nulhypothese, en hoe meer je de nulhypothese dus in twijfel zult trekken.
25.10 Hypothesetoetsen als besluitprocedures
In veel statistiekboeken worden hypothesetoetsen gepresenteerd als besluitprocedures. Een besluitprocedure is een formele procedure om tot een besluit te komen. Bij hypothesetoetsen gaat het om het besluit of we de nulhypothese op basis van de gegeven verwerpen. Met verwerpen bedoelen we dat we \(H_\textrm{0}\) niet meer geloofwaardig vinden. Als \(H_\textrm{0}\) wordt verworpen, dan word \(H_\textrm{A}\)aangenomen. In deze paragraaf gaan we in op de begrippen die met deze besluitprocedure samenhangen.
De \(P\)-waarde als criterium voor het verwerpen van \(H_\textrm{0}\)
De \(P\)-waarde van de toets van Arbuthnot was enorm klein; daarom kwamen we tot de conclusie dat toeval geen geloofwaardige verklaring is. We gebruikten de \(P\)-waarde dus als criterium voor het besluit om de nulhypothese te verwerpen.
Precies die logica volgen we als we een hypothesetoets gebruiken als een besluitprocedure: als de \(P\)-waarde klein is, dan verwerpen we \(H_\textrm{0}\), omdat de waargenomen toetsingsgrootheid onder \(H_\textrm{0}\) dan blijkbaar erg onwaarschijnlijk is.
Als de \(P\)-waarde juist groot is, dan zijn de waarnemingen juist niet verwonderlijk onder \(H_\textrm{0}\), en hebben we dus geen reden om \(H_\textrm{0}\) te verwerpen. Dit wil niet zeggen dat \(H_\textrm{0}\) waar is; wel dat onze gegevens geen sterk bewijs vormen tegen\(H_\textrm{0}\) en \(H_\textrm{0}\) dus niet uitsluiten.
De vraag die nu nog open staat is: hoe klein moet de \(P\)-waarde zijn om over te gaan tot het verwerpen van \(H_\textrm{0}\)? We moeten hiervoor een bepaalde drempelwaarde kiezen. Deze drempelwaarde wordt het significantieniveau genoemd en meestal genoteerd met de Griekse letter \(\alpha\). De nulhypothese wordt verworpen als \(P \le \alpha\).
WaarschuwingVerwarring over de letter \(\alpha\)
We hebben de letter \(\alpha\) eerder ook al gebruikt bij de notatie van kritieke waarden. Dat kan een beetje verwarrend zijn.
Dat voor de notatie van kritieke waarden dezelfde letter wordt gebruikt die ook het significantieniveau aanduidt, is geen toeval: in de praktijk hebben we vaak de kritieke waarde nodig die hoort bij het significantieniveau \(\alpha\).
Om te begrijpen wat het effect is van de keuze van het significantieniveau moeten we eerst beter begrijpen op welke manieren een besluit onjuist kan uitpakken.
Fouten van type 1 en type 2
Wanneer je een hypothesetoets gebruikt om de nulhypothese al-dan-niet te verwerpen, is er altijd een kans dat je tot de verkeerde beslissing komt. Tabel 25.1 hieronder vat de mogelijkheden samen.
Tabel 25.1: Samenvatting van de verschillende manieren waarop het besluit om \(H_\textrm{0}\) te verwerpen juist of onjuist kan zijn.
\(H_\textrm{0}\) waar
\(H_\textrm{0}\) onwaar
Je verwerpt \(H_\textrm{0}\)niet
Correcte beslissing (juist-negatief)
type-2-fout (onjuist negatief)
Je verwerpt \(H_\textrm{0}\)wel
type-1-fout (onjuist-positief)
Correcte beslissing (juist-positief)
Als in werkelijkheid \(H_\textrm{0}\) waar is dan kunnen er twee dingen gebeuren.
De gegevens geven geen aanleiding om \(H_\textrm{0}\) te verwerpen. In dat geval komen we tot een juiste beslissing. We noemen het besluit dan juist-negatief.
De gegevens geven wél aanleiding om \(H_\textrm{0}\) te verwerpen. In dat geval maken we een fout; het besluit is onjuist-positief. We noemen dit een type-1-fout.
Als in werkelijkheid \(H_\textrm{0}\) onwaar is, zijn er weer twee mogelijkheden.
De gegevens geven geen aanleiding om \(H_\textrm{0}\) te verwerpen. Dat is in dit geval een onjuiste beslissing, want \(H_\textrm{0}\) is onwaar. Het besluit is onjuist-negatief; het type fout noemen we een type-2-fout.
De gegevens gevel wél aanleiding om \(H_\textrm{0}\) te verwerpen. Het besluit is juist-positief.
Een besluitprocedure is erop gericht om het zo vaak mogelijk bij het rechte eind te hebben. Maar omdat onzekere gegevens geen volledig uitsluitsel geven, kun je fouten nooit volledig uitsluiten.
Je kunt fouten van type I grotendeels uitsluiten door \(H_\textrm{0}\) enkel te verwerpen als er héél zwaarwegend bewijs is—bij een héél kleine \(P\)-waarde. Daarvoor moeten we het significantieniveau \(\alpha\) dus heel klein kiezen. Maar de consequentie is dat je \(H_\textrm{0}\) ook vaak niet verwerpt terwijl dat wel zou moeten. Dat leidt tot een grote kans op een type-2-fout.
Andersom kun je ervoor kiezen om \(H_\textrm{0}\) al te verwerpen bij de minste verdenking. Dan moeten we het significantieniveau \(\alpha\) relatief groot kiezen, bijvoorbeeld \(\alpha = 0{,}1\), zodat we \(H_\textrm{0}\) ook al verwerpen bij een \(P\)-waarde die niet al te opmerkelijk is. Dat maakt de kans op een type-2-fout klein, maar levert natuurlijk een grote kans op een type-1-fout op.
Het punt is: de meest geschikte besluitprocedure zal altijd een compromis zijn tussen het risico op fouten van beide typen. Om een verstandig besluit te kunnen maken, zou je dus eerst moeten bepalen hoe erg je fouten van type 1 of 2 vindt en met je keuze van \(\alpha\) de juiste balans moeten vinden tussen beide risico’s.
De kans op een type-1-fout
We kunnen de relatie tussen het significantieniveau \(\alpha\) en de kans op een type-1-fout precies maken door nog iets verder door te denken.
Een type-1-fout is het verwerpen van \(H_\textrm{0}\) terwijl die eigenlijk waar is. Als \(H_\textrm{0}\) niet waar is, kun je dus geen type-1-fout maken. We hoeven daarom alleen de kans op een type-1-fout te beschouwen voor de situatie dat \(H_\textrm{0}\) waar is. Laten we dus aannemen dat \(H_\textrm{0}\) waar is. Dan is het nulmodel van toepassing en kunnen we dus kansberekeningen maken.
Stel dat we voor het significantieniveau \(\alpha = 0{,}15\) kiezen. We verwerpen \(H_\textrm{0}\) dus als \(P \le 0{,}15\), en maken in dat geval een type-1-fout. De vraag is nu: wat is de kans dat dit gebeurt?
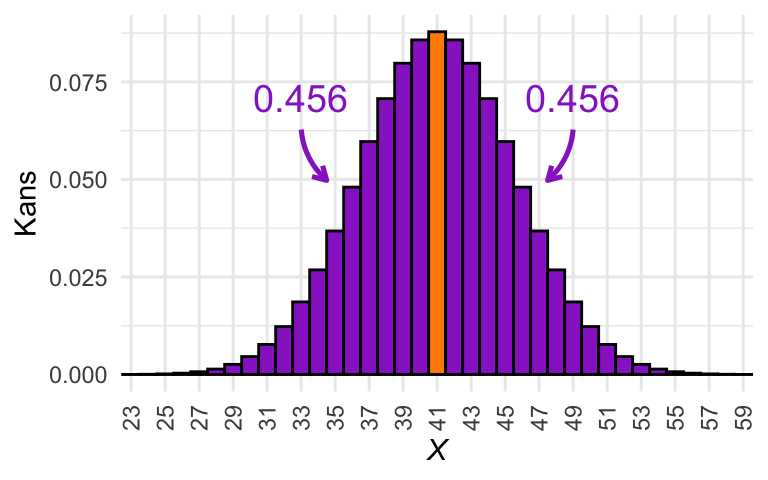
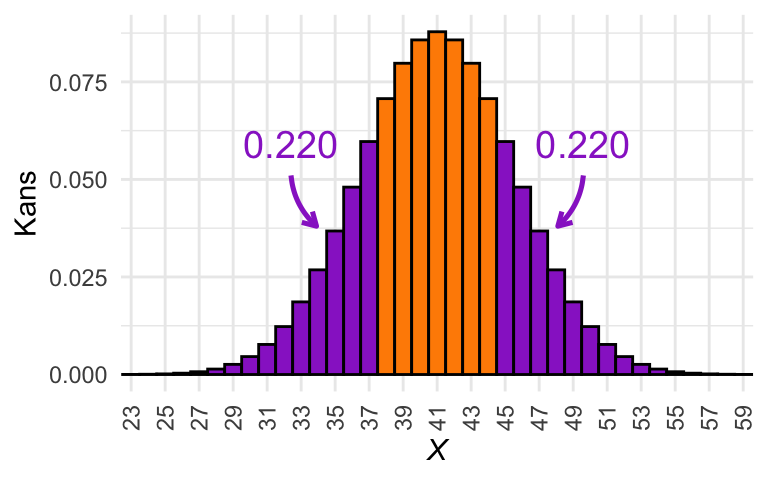
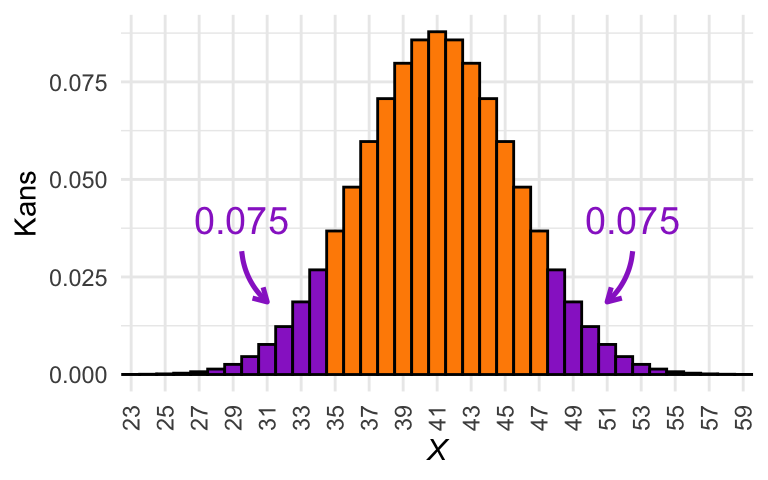
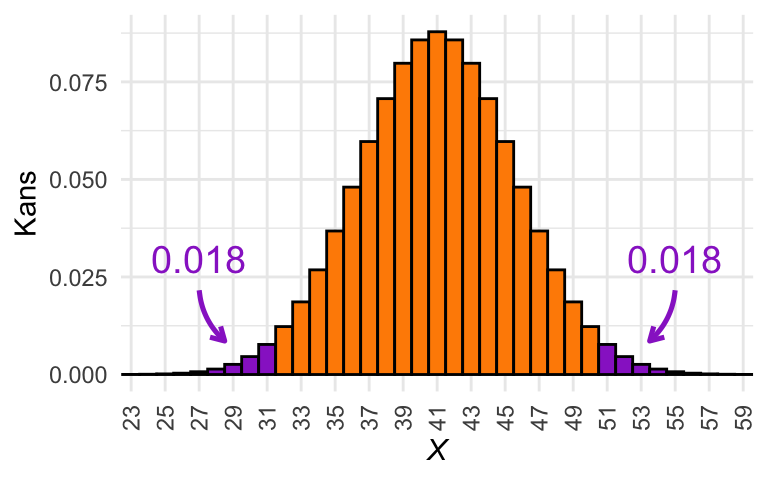
Het helpt om er een paar plaatjes bij te tekenen. In Figuur 25.5 zijn vier schetsen te zien van de kansverdeling van het nulmodel voor de casus van Arubuthnot. In Figuur 25.5 (a) tot Figuur 25.5 (d) is met paars de \(P\)-waarde aangegeven die hoort bij de uitkomst \(X = 42\), \(X = 45\), \(X = 48\), en \(X = 51\). In welke van deze gevallen is \(P \le \alpha\)?
(a) Illustratie van de \(P\)-waarde voor \(X = 42\).
(b) Illustratie van de \(P\)-waarde voor \(X = 45\).
(c) Illustratie van de \(P\)-waarde voor \(X = 48\).
(d) Illustratie van de \(P\)-waarde voor \(X = 51\).
Figuur 25.5: \(P\)-waarden voor verschillende waarden van de toetsingsgrootheid \(X\).
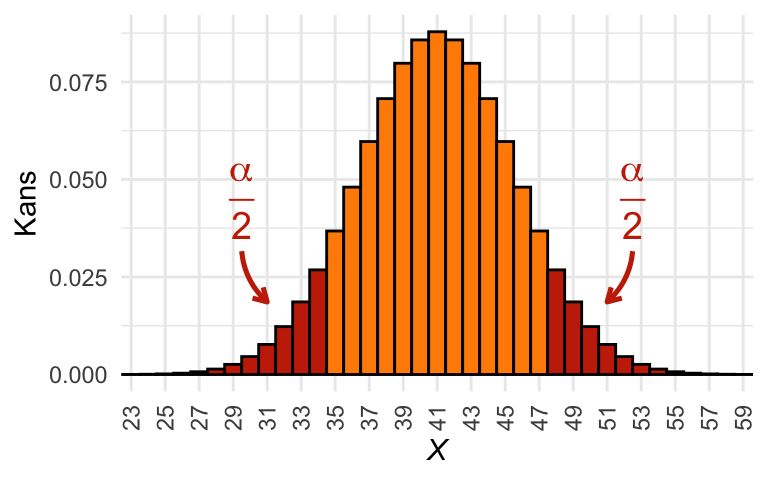
Om dat inzichtelijk te maken, tekenen we nog zo’n plaatje, maar nu zijn de staarten van de verdeling ingekleurd met rood, precies zo dat het rode oppervlak gelijk is aan \(\alpha\). Dat is in dit geval de linkerstaart t/m \(X = 34\) en de rechterstaart vanaf \(X = 48\):
Figuur 25.6: De totale oppervlakte van de rode staafjes is precies \(\alpha = 0{,}15\).
Dan is direct ook duidelijk dat \(P\le \alpha\) precies als de waargenomen \(X\) in het rode gebied ligt. Maar wacht… de kans daarop is gewoon de oppervlakte van het rode gebied, en dat is precies \(\alpha\)!
De conclusie is dat de kans om een type-1-fout te maken aangenomen dat \(H_\textrm{0}\) waar is, precies gelijk is aan \(\alpha\).7 Door \(\alpha\) te kiezen kunnen we dus de kans op een type-1-fout instellen die we acceptabel vinden. Zijn de consequenties van een type-1-fout ernstiger dan die van een type-2-fout, dan is het verstandig om een kleine \(\alpha\) te kiezen.
In de praktijk wordt in biologisch onderzoek bijna altijd een significantieniveau van \(\alpha = 0{,}05\) gebruikt.
BelangrijkHet significantieniveau en de kans op een type-1-fout
Als we de hypothesetoets gebruiken als besluitprocedure verwerpen we de nulhypothese als \(P \le \alpha\), het significantieniveau.
De kans op een type-1-fout als \(H_\textrm{0}\) waar is is dan precies \(\alpha\).
Waarom een besluitprocedure?
Zoals gezegd presenteren de meeste statistiekboeken hypothesetoetsen standaard als besluitprocedures. Waarom is dat eigenlijk zo?
Besluitprocedures kunnen in de praktijk erg belangrijk zijn. Ook als informatie onzeker is, moet er soms een binair besluit genomen worden: een arts moet kiezen welke behandeling een patiënt krijgt, ook bij onzekerheid over de diagnose; de WHO moet besluiten of een stof op de lijst van toxische stoffen moet; een regering moet besluiten over schoolsluitingen tijdens een pandemie. Een formele besluitprocedure kan helpen om zulke besluiten weloverwogen te nemen.
Maar in de wetenschap is het lang niet altijd nodig om een binair besluit te forceren (verwerpen of niet verwerpen). Als het bewijs te wensen overlaat, ligt het meer voor de hand om meer onderzoek te doen en je oordeel uit te stellen. De \(P\)-waarde geeft je de mate van bewijs tegen de nulhypothese; het vergelijken van die waarde met \(\alpha\) voegt geen informatie toe over de sterkte van het bewijs. Bovendien geeft dat onterecht de indruk dat een \(P\)-waarde van 0,045 (Significant! \(H_\textrm{0}\) verwerpen!) wezenlijk verschilt van een \(P\)-waarde van 0,054 (Niet significant! \(H_\textrm{0}\) blijft staan.).
Ook suggereert de besluitprocedure dat een oordeel over een hypothese op één \(P\)-waarde gebaseerd kan worden. Dat is onzinnig: in een oordeel neem je natuurlijk ook resultaten van eerdere onderzoeken mee, en andere kennis die \(H_\textrm{0}\) meer of minder plausibel maakt.
In de rest van dit boek zullen we om zulke redenen geen nadruk leggen op het besluit tot het al-dan-niet verwerpen van de nulhypothese.
Oefening 25.6 (Significant bewijs voor telepathie?)
Om te onderzoeken of telepathie mogelijk is, voer je een klein experiment uit. In een kamer van het Kruytgebouw zit proefpersoon 1 voor een beeldscherm. Een minuut lang verschijnt een (random door de computer gekozen) speelkaart op het scherm. De proefpersoon heeft de instructie gekregen om die speelkaart héél aandachtig te bestuderen.
In het Minnaertgebouw zit op exact hetzelfde moment een andere proefpersoon, proefpersoon 2. Deze proefpersoon krijgt de opdracht om zich te concentreren op gedachten, beelden of gevoelens die tijdens die minuut opkomen en dan te besluiten of de speelkaart waarnaar proefpersoon 1 staart harten, ruiten, klaver, of schoppen is.
Deze procedure wordt 3 keer herhaald. Het blijkt dat proefpersoon 2 het alle drie de keren goed heeft!
Wat zou voor dit onderzoek een voor de hand liggend nulmodel zijn?
Wat is de parameter waarnaar onze interesse uitgaat? Formuleer \(H_\textrm{0}\) en \(H_\textrm{A}\) in termen van deze parameter.
Wat is de \(P\)-waarde van dit resultaat? Zou je bij de gebruikelijke \(\alpha = 0{,}05\) de \(H_\textrm{0}\) moeten verwerpen?
Vind jij het redelijk om op basis van deze resultaten \(H_\textrm{0}\) te verwerpen en \(H_\textrm{A}\) aan te nemen?
25.11 Voor welke hypotheses bestaan er toetsen?
In dit hoofdstuk hebben we één hypothesetoets gezien, gebaseerd op de casus van John Arbuthnot. In de statistiek zijn voor een enorm aantal situaties hypothesetoetsen ontwikkeld. De hypotheses die getoetst worden kunnen bijvoorbeeld gaan over
het gemiddelde van een variabele in de populatie,
de variantie van een variabele in de populatie,
de samenhang tussen twee variabelen,
verschillen in het gemiddelde van een variabele tussen meerdere populaties,
de proportie van een eigenschap in een populatie,
etc.
In deze cursus kunnen we maar een klein aantal toetsen behandelen. In het volgende hoofdstuk bestuderen we toetsen van hypotheses over het populatiegemiddelde van variabelen. Maar het is goed te beseffen dat je slechts een topje van de ijsberg te zien krijgt.
25.12 Samenvatting
Concepten
Hypothese: Veronderstelling of voorlopige verklaring; die kan vervolgens getoetst kan worden door middel van onderzoek, experimenten of observaties.
Hypothesetoets: Methode die gebruikt wordt om te evalueren in hoeverre een verzameling waarnemingen —bijvoorbeeld meetresultaten of gegevens uit een steekproef— bewijs levert tegen een specifieke hypothese.
Nulhypothese en alternatieve hypothese: De nulhypothese \(H_\textrm{0}\) is de sceptische hypothese, \(H_\textrm{A}\) de ontkenning daarvan.
De hypothesetoets bepaalt de mate van bewijs tegen \(H_\textrm{0}\).
Overschrijdingskans of \(P\)-waarde: Kans onder de nulhypothese op een uitkomst die minstens zo extreem is als de uitkomst die daadwerkelijk heeft plaatsgevonden.
De structuur van hypothesetoetsen
Kies een statistisch model dat past bij de casus.
Stel de hypotheses \(H_\textrm{0}\) en \(H_\textrm{A}\) op in termen van een parameter van het statistisch model.
Kies een toetsingsgrootheid en bepaal de kansverdeling van de toetsinggrootheid aangenomen dat \(H_\textrm{0}\) waar is (“onder \(H_\textrm{0}\)”).
Bereken de toetsingsgrootheid op basis van de daadwerkelijke waarnemingen.
Bereken de \(P\)-waarde.
Trek je conclusies: hoe sterk is het bewijs tegen \(H_\textrm{0}\)?
Hypothesetoetsen als besluitprocedures
Type-1-fouten en type-2-fouten:
\(H_\textrm{0}\) waar
\(H_\textrm{0}\) onwaar
Je verwerpt \(H_\textrm{0}\)niet
Correcte beslissing (juist-negatief)
type-2-fout (onjuist negatief)
Je verwerpt \(H_\textrm{0}\)wel
type-1-fout (onjuist-positief)
Correcte beslissing (juist-positief)
Significantieniveau \(\alpha\): Grens waaronder de \(P\)-waarde “significant” genoemd wordt en \(H_\textrm{0}\) verworpen wordt.
De kans op een type-1-fout als \(H_\textrm{0}\) waar is, is \(\alpha\). De keuze van \(\alpha\) bepaalt dus het risico op onjuist-positieve resultaten.
Procedure: Als \(P \le \alpha\), dan wordt \(H_\textrm{0}\) verworpen en \(H_\textrm{A}\) aangenomen.
Een formele procedure om tot een besluit te komen. Bij hypothesetoetsen gaat het om het besluit om de nulhypothese al dan niet te verwerpen.
Hypothese
Hypothesis
Veronderstelling of voorlopige verklaring die getoetst kan worden door middel van onderzoek, experimenten of observaties.
Hypothesetoets
Hypothesis test
Een methode die gebruikt wordt om te evalueren in hoeverre een verzameling waarnemingen bewijs levert tegen een specifieke hypothese.
Juist-positief
True-positive
De nulhypothese wordt terecht verworpen.
Juist-negatief
True-negative
De nulhypothese wordt terecht niet verworpen.
Nulhypothese \(H_\textrm{0}\)
null hypothesis
De hypothese die met de hypothesetoets onderzocht wordt. Typisch de “sceptische” hypothese die veronderstelt dat de waarnemingen te verklaren zijn als toevallige steekproefvariatie.
Nulmodel
Null model
Een kansmodel dat gebruikt wordt om een hypothese mee te toetsen.
Overschrijdingskans / \(P\)-waarde
\(P\)-value
De kans onder \(H_\textrm{0}\) dat de toetsingsgrootheid minstens zo onwaarschijnlijk is als de daadwerkelijk waargenomen waarde van de toetsingsgrootheid.
Significantieniveau \(\alpha\)
Significance level
Grenswaarde die aangeeft hoe klein de \(P\)-waarde moet zijn om significant te heten. In besluitprocedures wordt \(H_\textrm{0}\) verworpen als \(P\le \alpha\); \(\alpha\) bepaalt dan de kans op een type-1-fout. Meestal wordt \(\alpha = 0{,}05\) aangehouden.
Statistisch significant
Statistically significant
Een resultaat wordt statistisch significant genoemd als de \(P \le \alpha\).
Toetsingsgrootheid
Test statistic
Het kengetal dat in een hypothesetoets gebruikt wordt om te bepalen of de waarnemingen opmerkelijk zijn onder \(H_\textrm{0}\).
type-1-fout
Type 1 error
De nulhypothese wordt onterecht verworpen.
type-2-fout
Type 2 error
De nulhypothese wordt niet verworpen, maar is in werkelijkheid onjuist.
Verwerpen van \(H_\textrm{0}\)
To reject \(H_\textrm{0}\)
Het concluderen dat \(H_\textrm{0}\) niet meer geloofwaardig is.
25.14 Opgaven
Oefening 25.7 (Kleurenblind)
Twee dobbelstenen – één eerlijk, één vals. Gemaakt met behulp van Dall-E3.
Stel je voor dat je thuis twee dobbelstenen hebt: een rode en een groene. Je weet dat de rode dobbelsteen eerlijk is; de kans dat je er een 6 mee gooit, is gewoon \(\frac{1}{6}\). Maar de groene dobbelsteen is een valse dobbelsteen: één kant is verzwaard, en daardoor is de kans op een 6 bij deze dobbelsteen \(\frac{1}{2}\).
Het probleem is: je bent kleurenblind, en hebt dus geen idee welke dobbelsteen welke is. Daarom doe je een experiment: je pakt willekeurig één van de dobbelstenen en gooit er 4 keer mee. Tot je verbazing gooi je 4 keer een 6.
Er zijn twee hypotheses. De eerste is dat je de rode dobbelsteen hebt gegooid, de tweede dat de groene dobbelsteen hebt gegooid.
Stel dat de eerste hypothese waar is. Wat is dan de kans op de uitkomst “4 keer een 6”?
Stel dat de tweede hypothese waar is. Wat is dan de kans op de uitkomst “4 keer een 6”?
Kun je op basis van de uitkomst “4 keer een 6” met zekerheid zeggen welke hypothese waar is?
Welke hypothese vind jij geloofwaardiger, gezien de uitkomst van het experiment?
Arbuthnot, J. (1710). An argument for divine providence, taken from the constant regularity observ’d in the births of both sexes. Philosophical Transactions of the Royal Society of London, 27, 186–190. https://doi.org/10.1098/rstl.1710.0011↩︎
We verwaarlozen in deze berekening de kans dat er in een jaar exact evenveel jongetjes als meisje geboren worden. Zouden we die kans meenemen, dan zou de kans op meer jongetjes dan meisjes niet \(\frac{1}{2}\) zijn, meer net iets kleiner. Arbuthnot verwaarloost dat effect in zijn berekening ook, maar merkt op dat dit betekent dat de échte kans alleen maar kleiner zal zijn dan de kans die hij voorrekent. Dat zou het argument tegen toeval alleen maar sterker maken.↩︎
Een scepticus is een persoon die de waarheid van beweringen in twijfel trekt totdat overtuigend bewijs geleverd is.↩︎
Je kunt met recht kanttekeningen plaatsen bij deze redenering; zie bijvoorbeeld:
Cohen, Jacob. “The Earth Is Round (\(p<.05\)).” American Psychologist 49, no. 12 (1994): 997–1003.
We gaan daar hier niet verder op in om verwarring te voorkomen.↩︎
De verdeling (Figuur 25.3) heeft een naam: de binomiale verdeling. Deze verdeling kom je altijd tegen als je \(n\) keer iets probeert, steeds met een vaste kans \(p\) op “succes”, en geïnteresseerd bent in het totaal aantal keren succes, \(X\). In deze cursus hebben we geen tijd om hier op in te gaan, maar je kunt hier meer informatie vinden.↩︎
Song, Shige. “Does Famine Influence Sex Ratio at Birth? Evidence from the 1959–1961 Great Leap Forward Famine in China.” Proceedings of the Royal Society B: Biological Sciences 279, no. 1739 (July 22, 2012): 2883–90. https://doi.org/10.1098/rspb.2012.0320.↩︎
Voor de scherpe lezer moeten we helaas kort ingaan op een subtiliteit.
In Figuur 25.6 hebben we de staarten van de verdeling rood gekleurd zodat het totale rode oppervlak gelijk is aan \(\alpha\). Als de variabele \(X\) continu is, kan dat altijd precies, want dan kunnen we de grens van het rode gebied precies leggen waar we willen. Maar als, zoals in dit voorbeeld, de variabele discreet is, kunnen we de grens van het rode gebied alleen in stapjes opschuiven—staafje voor staafje—waardoor we de rode oppervlakte niet op iedere willekeurige waarde kunnen instellen.
We kozen in Figuur 25.6 als voorbeeld \(\alpha = 0{,}15\) omdat het bij die waarde (min of meer toevallig) wél kan; de rode staafjes in Figuur 25.6 hebben (afgerond) daadwerkelijk oppervlak \(0{,}15\).
Als we \(\alpha\) op een willekeurige waarde zetten en de nulhypothese verwerpen als \(P \le \alpha\), zal de kans op een type-1-fout vaak net wat kleiner zijn dan \(\alpha\), omdat de totale oppervlakte van staafjes met \(P \le \alpha\) dan net wat kleiner is dan \(\alpha\).↩︎