kun je uitleggen dat biologische gegevens onzeker zijn door steekproevenvariabiliteit en meetfouten;
ben je vertrouwd met basisbegrippen die te maken hebben met steekproeven, zoals populatie, eenheden, variabele, populatieparameter, steekproef, schatting en schatter;
ken je de eigenschappen van een eenvoudige aselecte steekproef;
begrijp je het onderscheid tussen precisie en nauwkeurigheid, en tussen toevallige en systematische fouten;
kun je in voorbeelden verschillende oorzaken van bias herkennen en benoemen;
kun je uitleggen waarom het essentieel is om bij iedere schatting de mate van onzekerheid te rapporteren.
21.2 Onzekerheid in biologische gegevens
In de inleiding hebben we benadrukt dat biologische gegevens onzeker zijn. Dat komt doordat gegevens vaak het resultaat zijn van steekproeven (samples), en daarnaast geplaagd worden door meetfouten (measurement error). Beide situaties gaan we apart bekijken. We beginnen bij steekproeven.
21.3 Onzekerheid in schattingen op basis van steekproeven
Na iedere cursus word je gevraagd om een Caracal-enquête in te vullen. Een belangrijk doel van die enquête is om te bepalen hoe studenten de cursus gemiddeld beoordelen. In de praktijk vult een minderheid van de studenten de enquête daadwerkelijk in, en dus rijst de vraag: wat kunnen we leren over het gemiddelde oordeel van alle deelnemers van een cursus op basis van een beperkt aantal respondenten?
Laten we wat begrippen doornemen die helpen om over dit probleem na te denken.
In veel onderzoeken zijn we geïnteresseerd in een bepaalde populatie. Dat kan bijvoorbeeld de studentenpopulatie zijn, of een populatie eksters, of alle Nederlandse diabetespatiënten. Een populatie is een verzameling van eenheden (units). De eenheden hoeven geen personen of organismen te zijn; we kunnen ook onderzoek doen naar de “populatie” van zakken chips. Zit er gemiddeld wel echt 200g chips in, zoals de fabrikant beweert?
Het onderzoek gaat vervolgens over één of meerdere variabelen. In deze context is een variabele een eigenschap van de eenheden in de populatie, zoals bloedgroep, bloedsuikerwaarde na tenminste 8 uur vasten — of de inhoud van een zak chips.
De waarde van een variabele verschilt meestal per eenheid in de populatie. We kunnen ons daarom afvragen wat de verdeling is van de variabele in de populatie.
Zoals je in Hoofdstuk 20 hebt gezien, kunnen je je de verdeling van de variabele in de populatie voorstellen als een staafdiagram (als variabele categorisch is) of als een histogram (als de variabele numeriek is). We kunnen die verdeling ook karakteriseren met kengetallen, zoals gemiddelde en standaardafwijking. Dit soort kenmerken van de verdeling van een populatie worden ook wel populatieparameters genoemd.
Het doel van veel onderzoeken is om een populatieparameter te bepalen. Zo kan een onderzoek uitzoeken wat de gemiddelde opbrengst is van aardappelplanten van een bepaald ras, of wat de standaarddeviatie is van de dikte van schroeven die in een bepaalde fabriek worden geproduceerd.
Om een populatieparameter exact te bepalen zouden we de waarde van de variabele moeten meten voor iedere eenheid in de populatie. In de praktijk is dat meestal onmogelijk, omdat populaties vaak groot zijn en de onderzoeksmiddelen (geld, menskracht, tijd, …) beperkt. Bovendien zijn metingen vaak destructief: planten moeten worden geoogst, proefdieren geofferd, en proefpersonen blootgesteld aan risico’s. Daarom onderzoeken we meestal een beperkt aantal individuen uit de populatie—een steekproef. De waarden uit de steekproef gebruiken we vervolgens om de populatieparameter te schatten (to estimate). Dat doen we door voor de steekproef bepaalde statistieken uit te rekenen, zoals het gemiddelde. Als we een statistiek gebruiken om een parameter te schatten dan noemen we die statistiek een schatter (an estimate).
Dat we alleen toegang hebben tot een steekproef betekent helaas dat het resultaat nooit exact is. Ten eerste hangt de schatting af van de specifieke steekproef. Als je het onderzoek opnieuw zou uitvoeren, op dezelfde manier, dan zou de steekproef anders uitpakken en je schatting dus ook. Deze variatie tussen steekproeven noemt men steekproevenvariabiliteit (sampling variability). Ten tweede kan het zijn dat je steekproef niet representatief is voor de populatie. Door beide oorzaken zal een schatting op basis van een steekproef meestal afwijken van de ware populatieparameter.
Oefening 21.1 (De terminologie van steekproeven)
De begrippen die hierboven zijn behandeld zijn enorm belangrijk. Benoem daarom van de onderstaande onderzoeken
de populatie,
de eenheden van de populatie,
de variabele waarnaar onderzoek wordt gedaan,
de populatieparameter die geschat wordt.
Om te bepalen of de sterren in het “Virgo Cluster” tegelijk zijn ontstaan bepalen sterrenkundigen hun temperatuur. Als de temperatuur van deze sterren niet te veel varieert kunnen ze de conclusie trekken dat de sterren ongeveer even oud zijn.
In een glasfabriek wordt glas gerecycled. Het is moeilijk te voorkomen dat daarbij glas gemengd wordt met andere materialen, zoals keramiek. Voor gebruik in bierflesjes mag die verontreiniging gemiddeld niet meer zijn dan 2,5%. Om dat te garanderen neemt de fabriek regelmatig een steekproef van bierflesjes en meet daarin de verontreiniging.
Kinesin-1 is een moleculaire machine die binnen de neurons materiaal verplaatsen door over microtubili te “lopen”. Een bioloog wil bepalen hoe snel kinesin-1 gemiddeld loopt.
Onderzoekers doen een steekproef om te bepalen welk deel van de populatie bepaalde kabinetsplannen steunt.
21.4 Onzekerheid door meetfouten
In de vorige paragraaf hebben we besproken hoe onzekerheid ontstaat bij schattingen die zijn gebaseerd op steekproeven. In andere situaties maken we echter geen gebruik van steekproeven, maar gebruiken we meetinstrumenten om een grootheid te bepalen. Denk bijvoorbeeld aan het meten van een fysische constante, zoals de lichtsnelheid, of het meten van een individuele eigenschap, zoals je ochtendgewicht vandaag.
Wanneer je dezelfde meting meerdere keren uitvoert, zijn de uitkomsten niet altijd exact gelijk. Dit komt door meetfouten: afwijkingen die ontstaan door imperfecties in het meetproces. Sommige meetfouten zijn willekeurig, veroorzaakt door fluctuaties in omgevingsfactoren of ruis in het meetinstrument. Andere meetfouten zijn systematisch, bijvoorbeeld doordat het meetinstrument niet perfect gekalibreerd is en dus consistent een te hoge of te lage waarde geeft. Deze meetfouten maken dat schattingen op basis van metingen ook onzeker zijn.
In sommige onderzoeken spelen meetfouten en steekproevenvariabiliteit allebei een rol. Stel dat we voor een bepaald gebied de gemiddelde totale biomassa willen weten van de planten die groeien op één vierkante meter. We nemen dan een steekproef in het gebied—willekeurig gekozen “plotjes” van één vierkante meter—en meten de biomassa op die plotjes. Nu speelt steekproevenvariabiliteit en rol, omdat het resultaat afhangt van de willekeurig gekozen plotjes, maar gaan ook meetfouten meespelen, omdat bij het afmeten, oogsten en wegen van de planten toevallige afwijkingen zullen ontstaan.
Kortom, meetfouten zijn een belangrijke oorzaak van onzekerheid, zowel in individuele metingen als in schattingen die gebaseerd zijn op steekproeven.
21.5 Schattingen: precisie, nauwkeurigheid, zuiverheid en bias
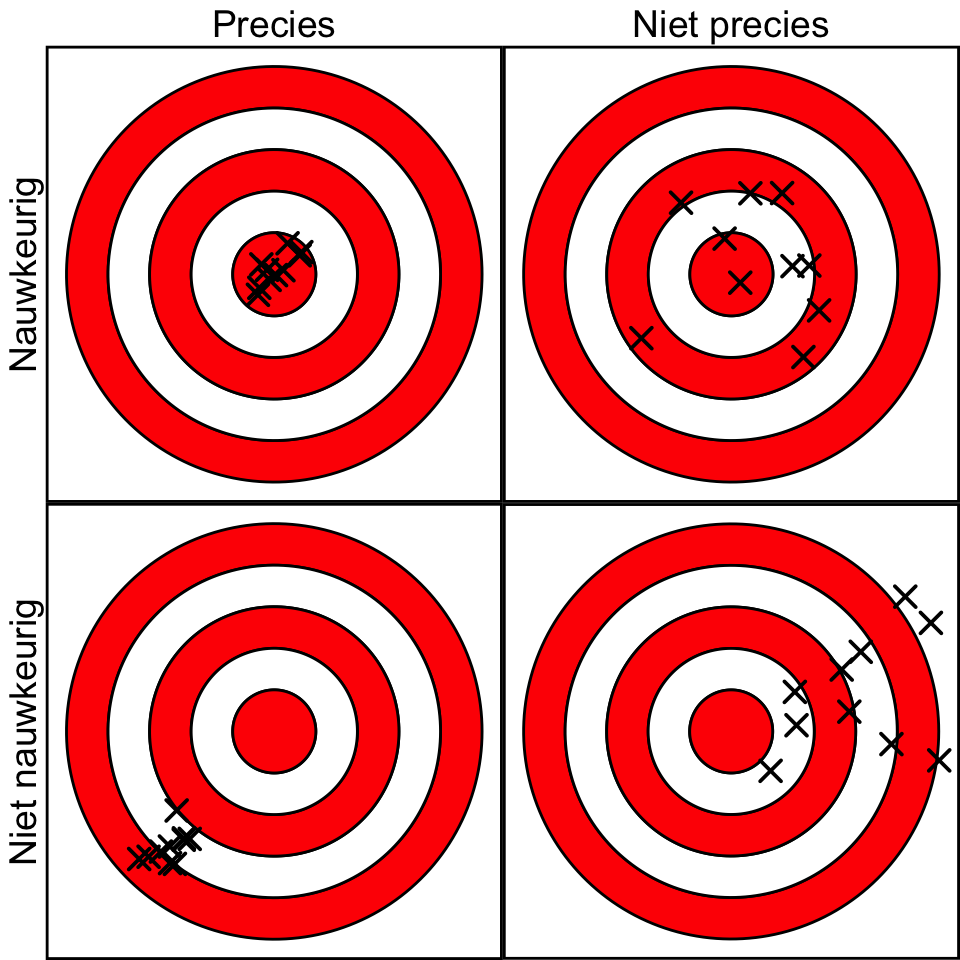
Schattingen kunnen op verschillende manieren afwijken van de ware parameter. Daarbij maken we onderscheid tussen precisie (precision) en nauwkeurigheid (accuracy). Deze begrippen worden in Figuur 21.1 hieronder geïllustreerd.
Code
# Functie om een ring (donut) te genereren als polygongenereer_ring <-function(x, y, straal_binnen, straal_buiten, punten =100) { theta <-seq(0, 2* pi, length.out = punten)data.frame(x =c(x + straal_buiten *cos(theta), NA, x + straal_binnen *cos(rev(theta))),y =c(y + straal_buiten *sin(theta), NA, y + straal_binnen *sin(rev(theta))) )}# Functie om een volledig doelwit te genererengenereer_doelwit <-function(punten =100) { kleuren <-c("red", "white", "red", "white", "red") straal_randen <-list(c(4, 5), c(3, 4), c(2, 3), c(1, 2), c(0, 1))bind_rows(lapply(1:5, function(i) {genereer_ring(0, 0, straal_randen[[i]][1], straal_randen[[i]][2], punten) %>%mutate(kleur = kleuren[i], groep = i) }))}# Functie om een steekproef te schalen en verschuivenscale_and_shift_sample <-function(n, desired_mean, desired_variance) { sample <-as.data.frame(MASS::mvrnorm(n, mu =c(0, 0), Sigma =diag(2))) scaled_sample <-sweep(sample, 2, sqrt(desired_variance /apply(sample, 2, var)), `*`)sweep(scaled_sample, 2, desired_mean, `+`) %>%setNames(c("x", "y"))}# Genereer gegevens voor het doelwitdoelwit_data <-genereer_doelwit(punten =200)# Maak een basisplot voor het doelwitbasis_doelwit <-ggplot() +geom_polygon(data = doelwit_data,aes(x = x, y = y, group = groep, fill = kleur),color ="black", size =0.5 ) +scale_fill_identity() +coord_fixed() +theme_void() +theme(panel.border =element_rect(color ="black", fill =NA, size =1))# Genereer steekproevenset.seed(134)steekproeven <-list(links_boven =scale_and_shift_sample(10, c(0, 0), 0.15),rechts_boven =scale_and_shift_sample(10, c(0, 0), 2),links_onder =scale_and_shift_sample(10, c(-2.5, -2.5), 0.15),rechts_onder =scale_and_shift_sample(10, c(3, 1), 2))# Functie om doelwit met steekproef te makenmaak_plot_met_steekproef <-function(basis, steekproef) { basis +geom_point(data = steekproef, aes(x = x, y = y),shape =4, size =3, stroke =1, color ="black")}# Maak de individuele doelwitplotsdoelwit_plots <-lapply(steekproeven, function(sp) maak_plot_met_steekproef(basis_doelwit, sp))# Labels en lege groblabels <-list(prec =textGrob("Precies", gp =gpar(fontsize =14)),not_prec =textGrob("Niet precies", gp =gpar(fontsize =14)),acc =textGrob("Nauwkeurig", gp =gpar(fontsize =14), rot =90),not_acc =textGrob("Niet nauwkeurig", gp =gpar(fontsize =14), rot =90))empty_grob <-rectGrob(gp =gpar(col =NA))# Combineer in gridgridExtra::grid.arrange(grobs =list( empty_grob, labels$prec, labels$not_prec, labels$acc, doelwit_plots[[1]], doelwit_plots[[2]], labels$not_acc, doelwit_plots[[3]], doelwit_plots[[4]] ),ncol =3,widths =c(0.1, 1, 1),heights =c(0.1, 1, 1))
Figuur 21.1: Illustratie van de begrippen precies en nauwkeurig.
Stel je voor dat je heel vaak dezelfde methode gebruikt om een parameter te schatten. Het resultaat zal iedere keer net iets anders uitvallen. De methode of schatting wordt precies genoemd als de verschillende resultaten weinig van elkaar verschillen. Precisie heeft dus te maken met de spreiding van resultaten bij herhaling. Je kunt je dat vast voorstellen: als je direct na elkaar meerdere keren op dezelfde weegschaal gaat staan en de resultaten meerdere kilo’s van elkaar verschillen, dan zul je concluderen dat de weegschaal niet erg precies is.
Als de verschillende schattingen dicht bij elkaar liggen wil dat nog niet zeggen dat ze ook dicht bij de waarde van de ware parameter liggen. In beide plaatjes in de linker-kolom van Figuur 21.1 is de methode precies, want de verschillende schattingen liggen dicht bij elkaar. Toch wijken in het onderste plaatje de waarden sterk af van de juiste waarde (gesymboliseerd door de bull’s-eye).
Een methode wordt nauwkeurig genoemd als het gemiddelde van de verschillende resultaten dicht bij de juiste waarde ligt. Nauwkeurigheid heeft dus te maken met de locatie van de resultaten bij herhaling. In beide plaatjes in de eerste rij van Figuur 21.1 zijn de resultaten geclusterd rond de bull’s-eye. In die gevallen is de methode dus nauwkeurig. Merk op dat een nauwkeurige methode niet precies hoeft te zijn, zoals in het plaatje rechtsboven.
Twee verschillende aspecten dragen dus bij aan de afwijking van schattingen van de juiste waarde. De eerste is er de toevallige fout (random error): wanneer dezelfde methode herhaaldelijk wordt toegepast, levert dit steeds een iets andere waarde op. Een precieze methode geeft een kleine toevallige fout.
Ten tweede is er een systematische fout (systematic error): daar is sprake van als de methode gemiddeld een te hoge of te lage waarde oplevert. Een nauwkeurige methode geeft een kleine systematische fout.
Als een methode of een schatter een systematische fout heeft dan zegt men ook wel dat deze bias heeft of “gebiast” is. Bias is een Engels woord; de beste vertalingen zijn misschien “vertekening” of “vooroordeel”. Maar omdat de Nederlandse woorden de lading vaak niet goed dekken zullen we de Engelse term bias ook blijven gebruiken. Bias kan op heel veel manieren ontstaan en is een heel belangrijk onderwerp. Daarom komen we er hieronder nog uitgebreid op terug.
Als een methode of schatter geen bias heeft dan noemen we de schatter zuiver.
Oefening 21.2 (Systematische fout of toevallige fout?)
Geef van de volgende voorbeelden aan of het systematische of toevallige fouten zijn.
Vier studentassistenten kijken dezelfde opdracht na aan de hand van dezelfde rubric, maar komen toch op verschillende cijfers uit.
Amerikaanse pollsters probeerden in 1936 de uitslag van de presidentsverkiezingen te voorspellen door een groot aantal mensen per telefoon te benaderen. Ze gebruikten daarvoor de telefoonlijst met abonnees van het tijdsschift Literary Digest. Op basis van die enquête werd verwacht dat Landon ruim van Roosevelt zou winnen. Het liep heel anders: Landon won alleen in Maine en Vermont en sleepte zo maar 8 van de 531 kiesmannen binnen.1 Achteraf bleek dat de leden van Literary Digest die zich een telefoon konden permitteren geen representatieve doorsnede waren van de Amerikaanse: zij stemden veel vaker Republikeins dan de gehele bevolking.
Het exacte tijdstip van aardschokken wordt bijgehouden, maar de klok die daarbij gebruikt wordt staat 4 minuten voor.
Bij het bepalen van een chemische reactiesnelheid speelt de concentratie van de reactanten een cruciale rol. Ondanks heel precies pipetteren verschillen die concentraties een klein beetje tussen herhalingen van het experiment.
Gewapend met deze begrippen keren we terug naar schattingen op basis van steekproeven. Waar komen bij schattingen op basis van steekproeven de toevallige en de systematische fouten vandaan?
21.6 Toevallige fouten in schattingen op basis van steekproeven
We beginnen met toevallige fouten in steekproeven.
In de aanloop naar de Tweede Kamerverkiezingen voeren we een peiling uit. We nemen een steekproef van 1000 stemgerechtigde Nederlanders en vragen hen op welke partij zij zouden stemmen als de verkiezingen vandaag zouden plaatsvinden. Van deze 1000 mensen geven er 33 aan CDA te gaan stemmen. Op basis hiervan schatten we dat het CDA momenteel 3,3% van de stemmen zou krijgen.
Stel je nu voor dat we op dezelfde dag op exact dezelfde manier nóg een steekproef zouden nemen. Zouden we in die tweede steekproef weer precies 33 personen aantreffen die voor het CDA kiezen?
Dat hoeft natuurlijk niet zo te zijn. Het is best mogelijk dat we de tweede keer toevallig maar 25 CDA-stemmers vinden, of juist 40. In dat geval zouden we op basis van de tweede steekproef uitkomen op een schatting van 2,5% of juist 4,0%. Schattingen op basis van steekproeven worden dus geplaagd door toevallige fouten, simpelweg omdat het resultaat afhangt van de toevallige steekproef. Omdat het woord “toeval” op verschillende manieren geïnterpreteerd kan worden, hebben we het liever over steekproevenvariabiliteit.
Dat steekproeven variabel zijn wil niet zeggen dat we op basis van een steekproef helemaal geen betrouwbare schattingen kunnen maken. Als in de gehele populatie 20% van de stemgerechtigden op de VVD wil stemmen, dan is de kans om in een steekproef van 1000 personen maar 33 VVD-stemmers aan te treffen enorm klein. (We verwachten er namelijk zo’n 200.) Die redenering kun je ook omdraaien: als we in die steekproef 33 VVD-stemmers vinden dan kunnen we vrijwel uitsluiten dat het in de gehele populatie om 20% gaat. (Dan hadden we er namelijk zo’n 200 verwacht).
Het punt is: schattingen kunnen ondanks hun onzekerheid heel informatief zijn, maar bij het interpreteren moeten we ons wel bewust zijn van de mate van onzekerheid. In Hoofdstuk 24 leer je te berekenen hoe groot de onzekerheid in een schatting is.
21.7 Systematische fouten in schattingen op basis van steekproeven
Systematische fouten en bias ontstaan als individuen met bepaalde eigenschappen een grotere kans hebben om in de steekproef terecht te komen. Bijvoorbeeld, om de gezondheid van een populatie vogels te onderzoeken, vang je er een aantal in netten. In dat geval zou het kunnen dat zieke vogels zich gemakkelijker laten vangen en daarom een grotere kans hebben om te worden opgenomen in je steekproef. Het gevolg is dat je steekproef een vertekend beeld geeft van de populatie als geheel. In andere woorden, de steekproef is dan niet representatief voor de populatie. Dat levert systematische fouten op, oftewel bias.
Eenvoudige aselecte steekproeven
Om bias te voorkomen is het dus belangrijk om ervoor te zorgen dat je bij het samenstellen van een steekproef niet bewust of onbewust eenheden met bepaalde eigenschappen een grotere kans geeft geselecteerd te worden. Dit kun je doen door de steekproef willekeurig te kiezen. Stel dat we een steekproef van \(n\) eenheden samenstellen. Als de manier van selecteren ervoor zorgt dat iedere mogelijke verzameling van \(n\) eenheden een gelijke kans heeft om te worden gekozen, dan noemen we dit een eenvoudige aselecte steekproef (EAS; simple random sample). Een gevolg daarvan is dat iedere eenheid gelijke kans heeft om in de steekproef opgenomen te worden.
Een EAS heeft verschillende voordelen. De eerste is dat zo’n steekproef geen bias introduceert. Hoewel de verdeling van een variabele in een EAS meestal niet perfect overeen komt met die van de populatie, is er geen systematische afwijking. Dat maakt het mogelijk om nauwkeurige schattingen te maken. De tweede is dat je voor een eenvoudige aselecte steekproef vaak kunt uitrekenen hoe precies de schatting is. (We gaan daar in Hoofdstuk 24 verder op in.) Vanwege deze voordelen gaan veel statistische analyses ervan uit dat de steekproef eenvoudig aselect is.
Maar in de praktijk is het vaak niet gemakkelijk om een eenvoudige aselecte steekproef te organiseren. Dat kan wel als je een lijst hebt van alle eenheden in de populatie. Iedere eenheid wordt dan genummerd, en we vragen een computer om uit de lijst met nummers er aselect \(n\) te kiezen, op basis van random getallen.
In veel gevallen bestaat zo’n lijst met alle eenheden uit de populatie niet, en in dat geval is de eenvoudige aselecte steekproef vaak niet exact mogelijk. Wel kun je er dan bij het ontwerp van je experiment naar streven om het ideaal van een eenvoudige aselecte steekproef zoveel mogelijk te benaderen.
Overigens maken veel onderzoeken gebruik van meer ingewikkelde steekproeven, zoals een gestratificeerde steekproef. We gaan daar in deze cursus niet op in.
Oorzaken van bias in schattingen op basis van steekproeven
Bias in steekproeven kan op allerlei manieren ontstaan. We noemen hieronder een paar oorzaken die zo vaak voorkomen dat ze een naam hebben gekregen.
Vrijwilligers-bias (volunteer bias) of zelfselectiebias (self-selection bias): Wanneer de steekproef bestaat uit personen die daar zelf voor hebben gekozen, kan vrijwilligers-bias optreden. Individuen die vrijwillig aan een onderzoek deelnemen verschillen vaak van de algehele populatie in sommigen van hun eigenschappen. Dat kan bijvoorbeeld zijn omdat ze speciaal interesse hebben in het onderwerp van het onderzoek.
Vrijwilligers-bias is vaak een gevaar bij onderzoeken in de psychologie. Dat komt doordat veel onderzoeken worden uitgevoerd met als proefpersonen studenten die zich vrijwillig voor dat onderzoek inschrijven. (Bij veel opleidingen psychologie moeten studenten tijdens hun studie punten verdienen door als proefpersoon deel te nemen aan onderzoeken. Ze kunnen dan wel zelf kiezen voor welk onderzoek ze zich inschrijven.)
Een specifiek voorbeeld dat goed onderzocht is, is vrijwilligers-bias in psychologisch onderzoek naar seksualiteit. In een grote studie2 kregen studenten de kans zich vrijwillig op te geven voor één tot drie verschillende onderzoeken naar hun houding ten opzichte van seksualiteit, de effecten van erotica, of fysieke metingen van opwinding. De vrijwilligers bleken, in vergelijking met de studenten die hier niet voor kozen, meer ervaring te hebben met seks, en minder seksuele schuldgevoelens. Het is niet vanzelfsprekend dat resultaten behaald met zo’n groep vrijwilligers representatief zijn voor de gehele populatie.
Non-respons-bias: Dit kan een rol spelen wanneer een deel van de benaderde groep mensen niet reageert op een enquête of onderzoek. Als de mensen die niet reageren verschillen in mening of kenmerken van degenen die wel reageren, kan dit leiden tot een vertekend beeld in de resultaten. Het onderzoek kan dan bijvoorbeeld alleen de standpunten van een specifieke groep vertegenwoordigen, terwijl de perspectieven van de niet-reagerende groep ontbreken. Merk op: non-response-bias heeft veel weg van vrijwilligers-bias.
Overlevingsbias (survivorship bias) treedt op wanneer de focus in een analyse ligt op eenheden die een bepaalde selectie hebben doorstaan, terwijl eenheden die niet door de selectie zijn gekomen buiten beschouwing worden gelaten. Hierdoor ontstaat een vertekend beeld, omdat alleen de kenmerken van de “overlevers” worden meegenomen, wat tot onjuiste conclusies kan leiden.
Een klassiek voorbeeld van overlevingsbias komt uit de Tweede Wereldoorlog. Tijdens de oorlog wilden de geallieerden de bepantsering van hun gevechtsvliegtuigen verbeteren om verliezen te verminderen. Onderzoekers bekeken de teruggekeerde vliegtuigen en noteerden waar de meeste kogelgaten zaten. Hun eerste gedachte was om extra pantser aan te brengen op die beschadigde plekken, omdat de vliegtuigen blijkbaar op die plekken het vaakst werden geraakt.
De statisticus Abraham Wald realiseerde zich dat het anders zat. De vliegtuigen die terugkeerden waren immers alleen de toestellen die ondanks hun schade in staat waren geweest om veilig terug te keren. De plekken waar zij beschadigd waren, waren dus niet de meest kwetsbare delen van het vliegtuig. De zwakste plekken waren juist de delen die, in de teruggekeerde vliegtuigen, géén kogelgaten hadden: de vliegtuigen die niet terugkeerden waren waarschijnlijk juist op die plekken fataal geraakt.
Dit inzicht leidde tot een tegen-intuïtieve conclusie: juist die onbeschadigde plekken moesten worden versterkt om de overlevingskansen van de vliegtuigen te vergroten.
Waarnemersbias (observer bias) is een vertekening die optreedt als de verwachtingen, overtuigingen of vooroordelen van een waarnemer invloed hebben op de manier waarop deze gegevens verzamelt of interpreteert. Dit kan bijvoorbeeld gebeuren als een onderzoeker resultaten verwacht die passen bij een bepaalde hypothese en daardoor informatie niet meer volledig objectief kan beoordelen.
Een voorbeeld komt van een studie waarbij experimentatoren de opdracht kregen om volgens een vast protocol te meten hoe goed ratten een taak konden leren.3 De helft van de experimentatoren kreeg vooraf te horen dat hun ratten speciaal gefokt waren voor intelligentie, de andere helft dat hun dieren juist geselecteerd waren op hun sloomheid. In werkelijkheid waren de ratten willekeurig verdeeld. Toch lieten de resultaten betere prestaties zien voor de “intelligente” dieren dan voor de “slome” dieren. Dat geeft aan dat, op een of andere manier, de verwachting van de experimentatoren effect had op de scores van de ratten.
Waarnemers-bias speelt waarschijnlijk vaker een rol in onderzoek naar diergedrag, omdat experimentatoren in de gedragsbiologie kennis of veronderstellingen hebben over de hypotheses van het onderzoek en voorkennis hebben over de onderzochte dieren.4 Bijvoorbeeld, studenten diergeneeskunde kregen de opdracht een kwalitatieve gedragsbeoordeling uit te voeren op basis van video’s van kippen. Over dezelfde video’s rapporteerden de studenten gemiddeld meer positieve en minder negatieve emoties als hen vooraf was verteld dat de video’s afkomstig waren van een biologische boerderij.
Het risico op bias kan worden verminderd door experimenten zorgvuldig te ontwerpen. In Hoofdstuk 27 gaan we daar verder op in.
Oefening 21.3 (Risico op bias) Leg voor de volgende casussen uit welke soorten bias je zou kunnen verwachten.
In een onderzoek beoordelen psychiaters na een behandeling van 10 weken in hoeverre de klachten van hun cliënten zijn gewijzigd.
Dagelijks kunnen luisteraars van NPO Radio 1 Stand.nl via telefoon of een website stemmen op een actuele stelling, zoals “Alle roofkunst moet terug naar het land van herkomst”. De respons wordt op de radio besproken.
Tijdens de pandemie kregen veel bedrijven financiële ondersteuning van de overheid, de coronasteun. Om te beoordelen of die steun het gewenste effect heeft gehad wordt in 2024 een steekproef van bedrijven bestudeerd. De steekproef wordt getrokken uit het register van de Kamer van Koophandel uit 2024.
De opleidingsadviescommissie Biologie (OAC-B) evalueert na afloop van ieder vak van de bachelor Biologie de resultaten van de Caracal-enquête, waaronder het gemiddelde cijfer dat het vak van de respondenten krijgt.
Op een conferentie voor managers uit de ICT sector concludeert de CEO van een succesvol bedrijf dat het slim is om je studie niet af te maken, aangezien hij en veel van zijn succesvolle collega’s dat ook niet hebben gedaan.
21.8 Bias in de schatting van de variantie
In Paragraaf 20.8.3 heb je geleerd hoe je de variantie in een steekproef berekent. De formule was (Vergelijking 20.4): \[
V_X = \frac{\sum_{i=1}^n \left(x_i - \overline{x}\right)^2}{n-1}.
\tag{21.1}\] Je kunt dit interpreteren als de gemiddelde gekwadrateerde afwijking van de waarnemingen ten opzichte van hun steekproefgemiddelde \(\overline{x}\). Maar, zoals we in Paragraaf 20.8.3 al opmerkten, dan zou je in de noemer \(n\) verwachten in plaats van \(n-1\). We kunnen nu begrijpen wat daar achter zit.
Je weet inmiddels dat het doel van een steekproef meestal is om een populatieparameter te schatten. De variantie van een steekproef berekenen we dan ook meestal om de variantie in de populatie te schatten. Als het even kan, gebruiken we daarvoor een zuivere schatter, dus een schatter zonder bias.
Wiskundig kun je aantonen dat de formule Vergelijking 21.1 inderdaad een zuivere schatter is voor de populatievariantie. Maar daarvoor is de noemer \(n - 1\) essentieel. Als we \(n\) zouden gebruiken in plaats van \(n - 1\), dan zouden we systematisch een te lage schatting krijgen.
De oorzaak van het probleem is dat we de afwijkingen van de waarnemingen berekenen ten opzichte van het steekproefgemiddelde \(\overline{x}\). Als we de afwijkingen konden berekenen ten opzichte van het ware populatiegemiddelde, dan konden we in de noemer gewoon \(n\) gebruiken. Maar omdat we het ware populatiegemiddelde niet kennen, zit er niets anders op dan dat we \(\overline{x}\) gebruiken, onze beste schatting. Dat levert bias op. Door in de noemer \(n - 1\) te gebruiken compenseren we voor die bias, en krijgen we weer een zuivere schatting van de populatievariantie.
Dat de formule met \(n\) in de noemer een systematisch te lage schatting geeft, kun je ook intuïtief begrijpen. We hebben namelijk gezien dat het steekproefgemiddelde \(\overline{x}\) het getal is dat de som van de gekwadrateerde afwijkingen minimaliseert. (Zie Paragraaf 20.7.3 en Vergelijking 20.2.) Als we de afwijkingen berekenen ten opzichte van \(\overline{x}\), dan zal de som van de gekwadrateerde afwijkingen dus altijd kleiner zijn dan wanneer we ze berekenen ten opzichte van het ware populatiegemiddelde.5
21.9 Kansen en de interpretatie van onzekere gegevens
Hierboven gebruikten we het voorbeeld van een peiling voor de Tweede Kamerverkiezingen:
“Als in de gehele populatie 20% van de stemgerechtigden op de VVD wil stemmen, dan is de kans om in een steekproef van 1000 personen maar 33 VVD-stemmers aan te treffen enorm klein. (We verwachten er namelijk zo’n 200.)”
Een kritische lezer kan hier hebben gedacht: Is dat wel zo? Hoe klein is die kans dan, en hoe klein moet een kans zijn om enorm klein genoemd te worden?
Vervolgens concludeerden we:
“Die redenering kun je ook omdraaien: als we in die steekproef 33 VVD-stemmers vinden dan kunnen we vrijwel uitsluiten dat het in de gehele populatie om 20% gaat. (Dan hadden we er namelijk zo’n 200 verwacht).”
De kritische lezer heeft daar vast gedacht: Kunnen we ook uitsluiten dat het in de gehele populatie om 10% gaat? Of 5%? Of is de kans op 33 VVD-ers in een steekproef van 1000 dan niet “enorm klein”? Waar trek je dan de grens?
De kritische lezer heeft gelijk. Als we onderbouwd keuzes willen maken, dan moeten we de kansen waarover we redeneren ook echt berekenen, en preciezer uitwerken welke conclusies we vervolgens kunnen trekken. Daarom gaan de volgende twee hoofdstukken over kansen en kansverdelingen. Daarna zijn we goed voorbereid om de draad weer op te pakken!
21.10 Samenvatting
Onzekerheid in gegevens ontstaat door
variabiliteit en bias in steekproeven
meetfouten
Meetfouten kunnen systematisch of toevallig zijn.
Terminologie van steekproeven
Ieder onderzoek gaat over een populatie die bestaat uit eenheden, en focust op zekere variabelen van die eenheden. Die variabelen hebben een verdeling in de populatie die wordt gekarakteriseerd door populatieparameters. Het doel van menig onderzoek is het schatten van zo’n populatieparameter op basis van een steekproef. De statistiek die we gebruiken voor de schatting wordt de schatter genoemd.
steekproevenvariabiliteit: De samenstelling van een steekproef wordt (deels) bepaald door toeval, en zal dus toevallig afwijken van die van de populatie. Dit draagt bij aan de onzekerheid in schattingen.
Bias: De samenstelling van een steekproef kan ook, door de manier waarop de steekproef is ontstaan of wordt uitgevoerd, systematisch afwijken van die van de populatie. Dan is de steekproef niet representatief, wat kan leiden tot bias in de schatting.
Voorbeelden zijn:
Vrijwilligersbias (zelfselectiebias)
Non-respons-bias
Overlevingsbias
Waarnemersbias
Eenvoudige aselecte steekproeven (EAS)
Een EAS van grootte \(n\) is een steekproef die zo wordt uitgevoerd dat iedere mogelijke verzameling van \(n\) eenheden een gelijke kans heeft om te worden gekozen. Dit elimineert bias en maakt het mogelijk steekproevenvariabiliteit te berekenen.
Terminologie van afwijkingen
Om de afwijking van schattingen of metingen van de ware parameter te beschrijven maken we onderscheid tussen precisie en nauwkeurigheid. Daarvoor stellen we ons voor dat we dezelfde schatting heel vaak herhalen.
Precisie: De methode/schatter/meting wordt precies genoemd als de resultaten dicht bij elkaar liggen. Precisie heeft dus te maken met de spreiding van resultaten. Toevallige meetfouten en steekproevenvariabiliteit verlagen dus de precisie.
Nauwkeurigheid: De methode/schatter/meting wordt nauwkeurig genoemd als het gemiddelde van de resultaten dicht bij de ware parameter ligt. Nauwkeurigheid heeft dus te maken met de locatie van de resultaten. Systematische meetfouten en bias verlagen dus de nauwkeurigheid.
Een schatting is bruikbaar ondanks onzekerheid als we ons bewust zijn van de mate van precisie en nauwkeurigheid.
Andersom:
Een schatting is nutteloos als we geen beeld hebben van de precisie en nauwkeurigheid.
Een systematische afwijking in een methode of schatter.
eenheid (in de context van een populatie)
unit
Een populatie kan zijn samengesteld uit allerlei soorten objecten en subjecten, van personen tot voorwerpen. In het algemeen gebruiken we het woord eenheid.
eenvoudige aselecte steekproef
simple random sampling
Een steekproef die genomen is zodanig dat alle mogelijk steekproeven even waarschijnlijk zijn.
meetfout
measurement error
Het verschil tussen het resultaat van een meting en de daadwerkelijke waarde van de variabele.
nauwkeurigheid
accuracy
Bij een nauwkeurige methode of schatter is het resultaat gemiddeld dicht bij de echte waarde van de te schatten parameter.
non-respons-bias
nonresponse bias
Een bias die optreedt wanneer de kenmerken van mensen die niet reageren op een enquête of informatieverzoek verschillen van die van mensen die wel reageren.
overlevingsbias
survival bias
Een bias die ontstaat wanneer de steekproef genomen wordt uit eenheden die door een selectieproces zijn gegaan en dus mogelijk niet representatief zijn voor de populatie.
populatie
population
Een groep eenheden (objecten/dieren/mensen) waarvan we bepaalde variabelen statistisch onderzoeken.
populatie-parameter
population parameter
Statistisch kenmerk van de verdeling van variabelen in een populatie, zoals het gemiddelde of de standaardafwijking.
precisie
precision
Een methode of schatter is precies als resultaten bij herhaling dicht bij elkaar liggen.
representatief
representative
Een representatieve steekproef heeft een samenstelling die wat betreft de relevante variabelen lijkt op de populatie.
schatten
to estimate
De waarde van een populatieparameter proberen te bepalen op basis van onvolledige informatie.
schatter
estimate
Statistiek de gebruikt wordt om een populatieparameter te schatten.
steekproef
sample
Een selectie van eenheden uit een populatie.
steekproeven-variabiliteit
sampling variability
Onzekerheid in schattingen die het gevolg is van toevallige verschillen tussen steekproeven.
systematische fout
systematic error
Een systematische fout is een afwijking in het gemiddelde resultaat van een methode of schatter ten opzichte van de werkelijke waarde van de grootheid.
toevallige fout
random error
Een toevallige fout is een afwijking van een methode of schatter van de werkelijke waarde van een grootheid die bij herhaling steeds verschilt.
variabele
variable
Een eigenschap die de eenheden van een populatie hebben.
verdeling
distribution
De manier waarop de waarden die een variabele aanneemt binnen een populatie over de mogelijk waarden verspreid zijn.
vrijwilligers-bias / zelfselectiebias
volunteerbias / self-selection bias
Een bias die ontstaat doordat mensen die aan een onderzoek mee willen doen niet representatief zijn voor de gehele populatie, mogelijk door een speciale interesse in het onderwerp.
waarnemersbias
observer bias
Een bias die ontstaat doordat onderzoekers zelf bepaalde verwachtingen hebben en (onbewust) geneigd zijn daarvan bevestiging te zien.
zuiver
unbiased
Een methode of schatter is zuiver als deze geen bias / systematische fout heeft.
21.12 Extra informatie
Als de verschillende voorbeelden van bias je interesse hebben gewekt, zijn de volgende populair-wetenschappelijke boeken de moeite waard:
“How to Lie with Statistics”* door Darrell Huff (1954)
“The Flaw of Averages”* door Sam L. Savage (2009).
“Thinking Fast and Slow”*, door Daniel Kahneman (2011)
“How Not to Be Wrong: The Power of Mathematical Thinking”* door Jordan Ellenberg (2014).
Zie daarnaast de voetnoten hieronder.
21.13 Opgaven
Oefening 21.4 (Een eenvoudige aselecte steekproef nemen met R)
Als je een lijst hebt van alle eenheden in je populatie, dan kan R je gemakkelijk helpen om een eenvoudige aselecte steekproef te nemen. De functie sample() is daar speciaal voor bedoeld.
Als v een vector is, en n een integer, dan geeft sample(v, n) een willekeurige selectie van n eenheden uit v. Iedere eenheid komt hoogstens één keer in de steekproef voor. (Dat betekent ook dat n niet groter mag zijn dan de lengte van v, want anders kun je niet n elementen uit v selecteren.)
Stel je hebt twintig plotjes land, waarmee je wilt testen wat het effect is van bemesting op de biodiversiteit. Om dit te testen, ben je van plan de helft van de plotjes wel te bemesten en de andere helft niet. Je hebt de plotjes genummerd. Schrijf een simpele R-code met de functie sample() om aselect 10 plotjes uit te kiezen die bemest gaan worden.
Laad de dataset NHANES in, zoals je al vaker hebt gedaan. Selecteer nu aselect 30 individuen uit deze lijst en geef voor deze steekproef weer hoeveel uren zij op doordeweekse dagen zeggen te slapen (SleepHrsNight). Geef ook het gemiddelde voor de steekproef. Dat is een schatting voor het gemiddelde van de populatie.
Om te onderzoeken hoe onzeker zo’n schatting op basis van één steekproef is, herhalen we de schatting heel vaak. Dan kunnen we zien hoeveel de resultaten van elkaar verschillen.
Het volgende script herhaalt de EAS 1000 keer, berekent steeds het gemiddelde binnen de steekproef, en tekent vervolgens een histogram van de resultaten.
Om er voor te zorgen dat de steekproeven geen NA bevatten, filteren we de dataset eerst.
library(NHANES)data(NHANES)# selecteer gegevens die niet NA zijnslaapuren <-na.omit(NHANES$SleepHrsNight)# Instellen van parametersn_herhalingen <-10000# Aantal steekproevenn_steekproef <-30# Grootte van elke steekproefgemiddelden <-numeric(n_herhalingen) # Vector voor opslag van gemiddelden# Herhaal steekproeven en bereken gemiddeldenfor (i in1:n_herhalingen) { steekproef <-sample( slaapuren, size = n_steekproef ) gemiddelden[i] <-mean(steekproef, na.rm =TRUE)}# Plot histogram van de gemiddeldenhist( gemiddelden, col ="darkorange", breaks =20)
Zorg dat je het script begrijpt en voer het dan uit op je computer.
Bestudeer het histogram.
Iedere steekproef geeft een schatting van het populatiegemiddelde van SleepHrsNight in de populatie van NHANES. Maar iedere steekproef geeft net een andere schatting. Hoe komt dat?
Wat is, op basis van het histogram, jouw beste schatting van het gemiddelde van SleepHrsNight in de gehele populatie?
Voeg een regel toe aan de code om het gemiddelde van de populatie daadwerkelijk te berekenen. Zat je er dicht bij?
Kijk nog eens naar het histogram. Iedere steekproef op basis van één steekproef van 30 personen levert een schatting op (het steekproefgemiddelde) met een bepaalde onzekerheid. Dat blijkt uit dit histogram, want die geeft aan hoezeer verschillende steekproefgemiddelden van elkaar verschillen. Wat zou een goede maat zijn van de onzekerheid in een schatting op basis van één steekproef van 30 personen?
Voeg een regel toe aan het script om die maat uit te rekenen.
Tegenwoordig zijn er 538 kiesmannen te verdienen, maar dat is pas sinds 1961 het geval.↩︎
Strassberg, Donald S., and Kristi Lowe. “Volunteer Bias in Sexuality Research.” Archives of Sexual Behavior 24, no. 4 (August 1, 1995): 369–82. https://doi.org/10.1007/BF01541853.↩︎
Rosenthal, Robert. “On the Social Psychology of the Psychological Experiment: The Experimenter’s Hypothesis as Unintended Determinant of Experimental Results.” American Scientist 51, no. 2 (1963): 268–83.
Rosenthal, Robert, and Kermit L. Fode. “Psychology of the Scientist: V. Three Experiments in Experimenter Bias.” Psychological Reports 12, no. 2 (April 1, 1963): 491–511. https://doi.org/10.2466/pr0.1963.12.2.491.↩︎
Tuyttens, F. A. M., S. de Graaf, J. L. T. Heerkens, L. Jacobs, E. Nalon, S. Ott, L. Stadig, E. Van Laer, and B. Ampe. “Observer Bias in Animal Behaviour Research: Can We Believe What We Score, If We Score What We Believe?” Animal Behaviour 90 (April 1, 2014): 273–80. https://doi.org/10.1016/j.anbehav.2014.02.007.↩︎
Uitzondering is als \(\overline{x}\) exact gelijk is aan het populatiegemiddelde; dan zijn de kwadratensommen gelijk.↩︎