In het vorige hoofdstuk hebben we het uitgebreid gehad over relaties tussen variabelen. In dit hoofdstuk kijken we specifiek naar relaties tussen twee continue variabelen. De focus zal sterk liggen op lineaire relaties. Dat zijn relaties waarbij het verband tussen de variabelen beschreven kan worden met een rechte lijn. Maar als afsluiter zullen we ook een voorbeeld bekijken waarbij de relatie niet lineair is.
28.1 Leerdoelen
Na het bestuderen van dit hoofdstuk kun je:
uitleggen wat een lineaire relatie is;
de covariantie tussen twee variabelen berekenen en interpreteren;
voor een gegeven dataset Pearsons correlatiecoëfficiënt \(r\) berekenen en interpreteren;
toetsen of de correlatiecoëfficiënt van een steekproef groot genoeg is om te concluderen dat er in de populatie ook een correlatie is;
uitleggen welk statistisch model daarvoor gebruikt wordt, en beoordelen of de aannames van dat model redelijk zijn;
uitleggen wat een regressielijn is en hoe die gebruikt kan worden om voorspellingen te doen;
relaties tussen de covariantie, de correlatiecoëfficiënt, en de regressielijn beschrijven en toepassen;
de regressiecoëfficiënten berekenen met R, inclusief betrouwbaarheidsintervallen;
uitleggen welk statistisch model daarvoor gebruikt wordt, en beoordelen of de aannames van dat model redelijk zijn;
het onderscheid tussen interpolatie en extrapolatie uitleggen en de gevaren ervan benoemen;
uitleggen dat ook de parameters van niet-lineaire modellen geschat kunnen worde door ze te “fitten” aan gegevens.
28.2 Lineaire relaties
We beginnen met een voorbeeld.
Voorbeeld 28.1 (De ontdekking van Sir Francis Galton.)
Portret van Francis Galton, geschilderd door Octavius Oakley (1840) Publiek domein.
In Hoofdstuk 27 zijn we Francis Galton al tegengekomen. Rond 1888 deed Galton onderzoek naar de erfelijkheid van lichaamslengte. Iedereen weet dat lange ouders vaak lange kinderen krijgen, maar ook dat er soms opvallende verschillen zijn tussen ouders en hun kinderen. Galton verzamelde als eerste systematisch gegevens om te zien in welke mate de lengte van de ouders
en die van hun kinderen samenhangen.
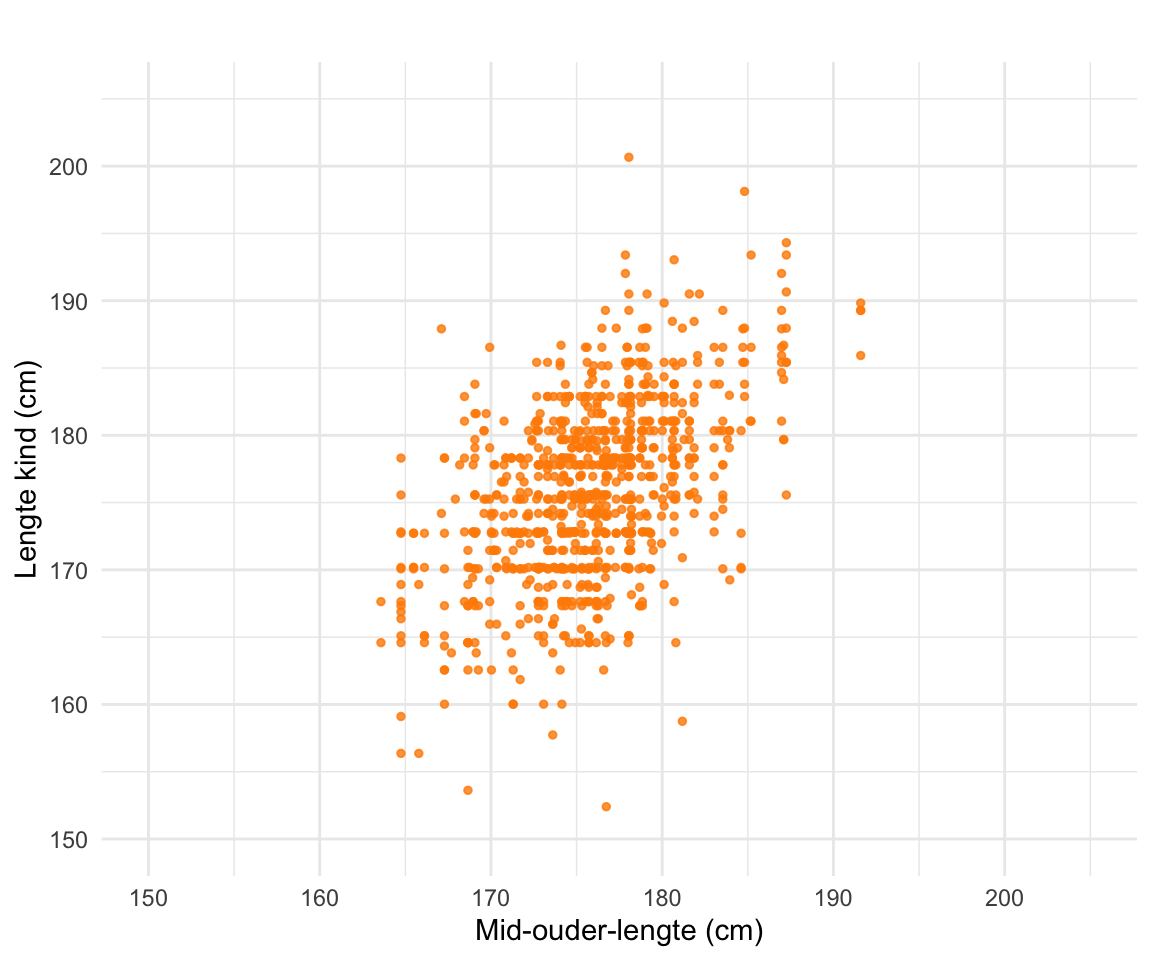
In het figuur hieronder zijn de gegevens van Galton te zien. Op de \(x\)-as staat de uitgezet. Dat is het gemiddelde van de lengte van beide ouders. Op de \(y\)-as staat de lengte van hun (volwassen) kinderen.
Code
# Laad de GaltonFamilies-datasetdata("GaltonFamilies")# Definieer omrekenfactoreninch <-2.54factor_vrouw <-1.08# Corrigeer ouderlengte naar cm en pas factor toe voor moedersGaltonFamilies$mid_parent_height <- inch * ( GaltonFamilies$father + factor_vrouw * GaltonFamilies$mother) /2# Corrigeer kindlengte naar cmGaltonFamilies$childHeightCorrected <- inch * GaltonFamilies$childHeight# Pas correctie toe voor vrouwelijke kinderenGaltonFamilies$childHeightCorrected[ GaltonFamilies$gender =="female"] <- factor_vrouw * GaltonFamilies$childHeightCorrected[ GaltonFamilies$gender =="female" ]# Hernoem eindvariabelen voor plotGaltonFamilies$lengte_ouders <- GaltonFamilies$mid_parent_heightGaltonFamilies$lengte_kinderen <- GaltonFamilies$childHeightCorrected# Maak scatterplotggplot( GaltonFamilies,aes(x = lengte_ouders, y = lengte_kinderen)) +geom_point(alpha =0.8,size =1,color = puntkleur1 ) +# geom_abline(# slope = 1,# intercept = 0,# linetype = "dashed",# color = "black"# ) +xlim(150, 205) +ylim(150, 205) +labs(x ="Mid-ouder-lengte (cm)",y ="Lengte kind (cm)",title ="" ) +theme_minimal()
Figuur 28.1: De lichaamslengte van volwassen kinderen is gecorreleerd met de lichaamslengte van de ouders. Op de \(x\)-as staat de mid-ouder-lengte; dat is het gemiddelde van beide ouders. De lichaamslengtes van alle vrouwen (moeders en kinderen) is vermenigvuldigd met 1,08 om te corrigeren voor het feit dat mannen iets langer zijn dan vrouwen.
Het figuur laat zien dat lange ouders gemiddeld lange kinderen krijgen. Maar je kunt ook zien dat kinderen van even lange ouders flink in lengte kunnen verschillen.
De gegevens roepen allerlei vragen op. Kunnen we de relatie tussen twee variabelen kwantificeren? Is er een manier om te toetsen of deze samenhang ook het toevallige gevolg kan zijn van steekproevenvariabiliteit? Op deze en andere vragen gaan we hieronder in.
Wat is een lineaire relatie?
Stel dat we uit een populatie een steekproef van grootte \(n\) hebben genomen en van iedere eenheid twee variabelen hebben gemeten: \(X\) en \(Y\). De gemeten waarden van eenheid \(i\) noemen we \(x_i\) en \(y_i\). We tekenen vervolgens een spreidingsdiagram waarbij we \(Y\) uitzetten tegen \(X\).
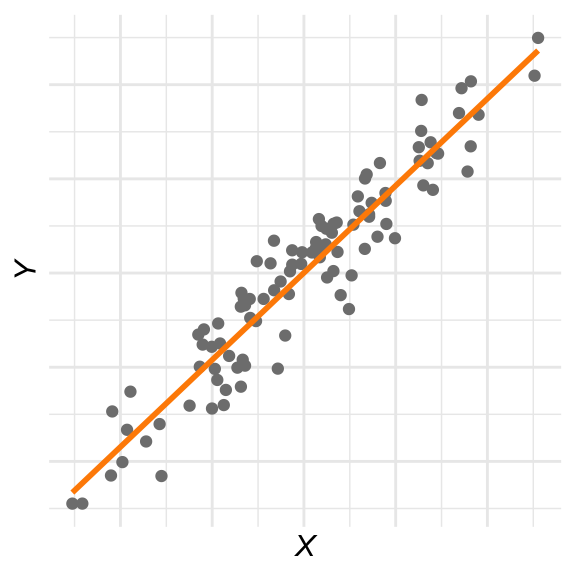
We zeggen dat de twee variabelen een lineaire relatie hebben als de datapunten op of in de buurt van een rechte lijn liggen die stijgt of daalt. (De lijn moet wel stijgen of dalen, want als de lijn horizontaal loopt hangen de waarden van \(Y\) niet af van die van \(X\), en is er dus geen relatie.) Figuur 28.2 laat een duidelijk voorbeeld zien.
Code
# Stel parameters insteekproef_grootte <-100gemiddelden <-c(0, 0)covariantie_matrix <-matrix(c(1, 0.95, 0.95, 1), nrow =2)# Genereer bivariate normale steekproefset.seed(122) # voor reproduceerbaarheiddata <-as.data.frame(mvrnorm(n = steekproef_grootte,mu = gemiddelden,Sigma = covariantie_matrix))names(data) <-c("X", "Y")# Maak de plotggplot(data, aes(x = X, y = Y)) +geom_point(color = puntkleur3) +geom_smooth(method ="lm", se =FALSE, color = lijnkleur0, linewidth =1) +labs(x =expression(italic(X)), y =expression(italic(Y))) +theme_minimal() +theme(axis.text.x =element_blank(),axis.text.y =element_blank() )
Figuur 28.2: Variabelen \(X\) en \(Y\) met een lineaire relatie.
Pearsons correlatiecoëfficiënt \(r\)
Als twee variabelen een lineaire relatie hebben, kunnen we de sterkte van die relatie kwantificeren door Pearsons correlatiecoëfficiënt\(r\) uit te rekenen. (In de praktijk zeggen we vaak kortaf correlatiecoëfficiënt.)
Hier zijn een paar eigenschappen:
De correlatiecoëfficiënt is dimensieloos en heeft dus geen eenheid.
De waarde van \(r\) ligt altijd in het interval \([-1, 1]\).
Het teken van \(r\) (positief of negatief) geeft aan of het om een stijgend (positief) of een dalend (negatief) verband gaat.
De absolute waarde van \(r\) geeft aan hoe sterk het verband is; dat wil zeggen, hoe precies de punten op een lijn liggen.
Als \(r = 1\) of \(-1\), dan is er een perfect lineair verband en liggen alle punten exact op een rechte lijn. Als \(r = 0\), dan is er géén lineair verband tussen de variabelen.
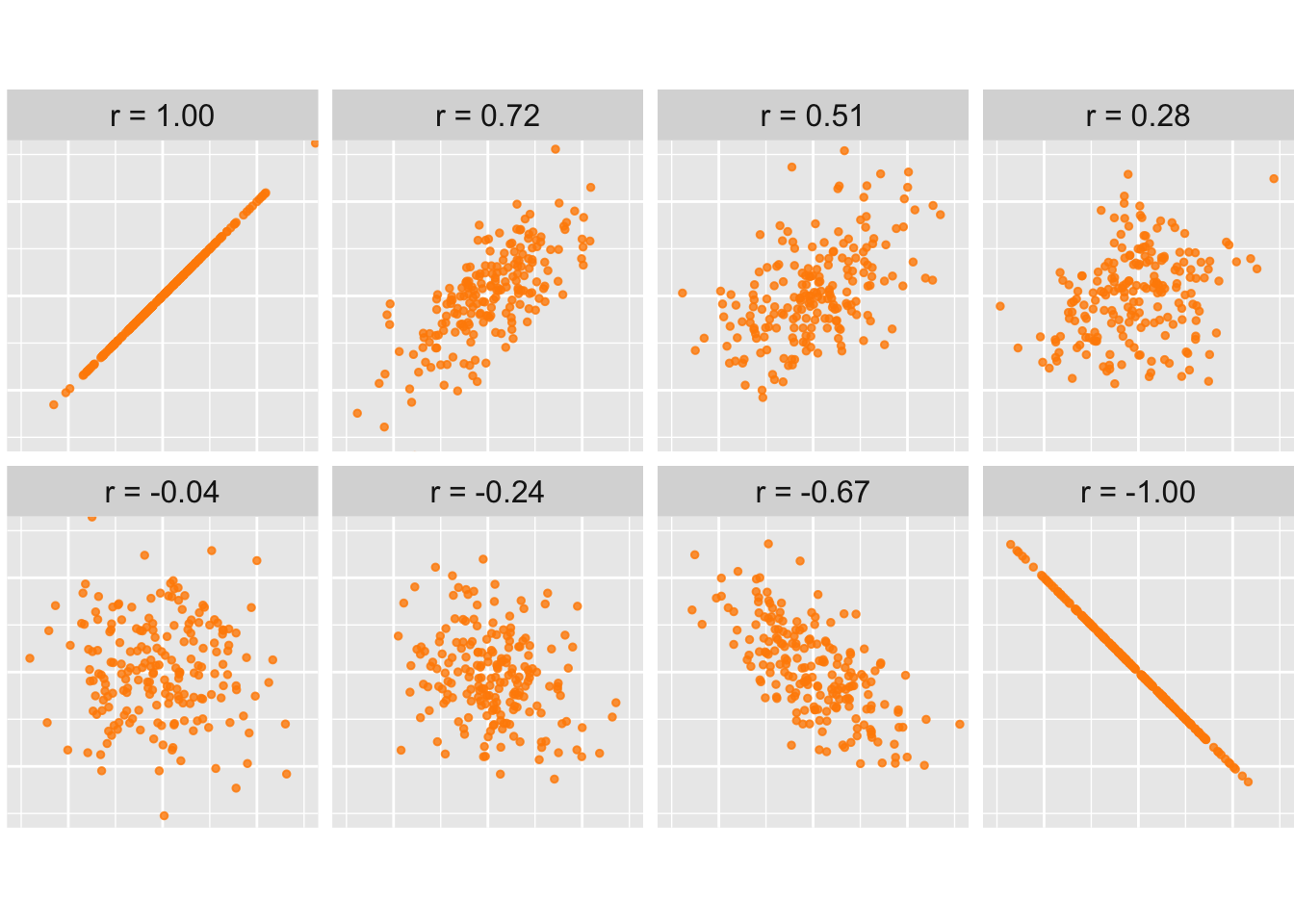
Figuur 28.3 toont een aantal voorbeelden van puntenwolken met de bijbehorende waarden van \(r\).
Code
# Definieer parametersn <-200# Steekproefgroottecorrelaties <-c(1, 0.75, 0.5, 0.25, 0, -0.33, -0.67, -1)set.seed(123)# Functie om een bivariate normale steekproef te genererengenereer_data <-function(rho, n, groep) { sigma <-matrix(c(1, rho, rho, 1), nrow =2) data <- MASS::mvrnorm(n, mu =c(0, 0), Sigma = sigma)data.frame(X = data[, 1], Y = data[, 2], groep = groep)}# Genereer datasets voor verschillende correlatiesdatasets <-do.call(rbind, Map(genereer_data, correlaties, n = n, groep =1:8))# Bereken sample correlaties per groepcorrelatie_labels <- datasets %>%group_by(groep) %>%summarise(sample_cor =cor(X, Y)) %>%mutate(label =sprintf("r = %.2f", sample_cor))# Maak de ggplot met facet_wrapp <-ggplot(datasets, aes(x = X, y = Y)) +geom_point(color = puntkleur1, alpha =0.8, size =1) +facet_wrap(~ groep, nrow =2, labeller =as_labeller(setNames(correlatie_labels$label, 1:8))) +coord_fixed(xlim =c(-3, 3), ylim =c(-3, 3)) +# theme_minimal() +theme(axis.text =element_blank(),axis.ticks =element_blank(),strip.text =element_text(size =12),plot.margin =margin(0, 0, 0, 0) ) +labs(x =NULL, y =NULL)# Print de plotprint(p)
Figuur 28.3: Voorbeelden van steekproeven met verschillende correlatiecoëfficiënten.
De correlatiecoëfficiënt is niet de richtingscoëfficiënt
De correlatiecoëfficiënt geeft aan of het verband positief of negatief is, en hoe dicht de punten bij de lijn liggen. Maar hij vertelt niet hoe steil de lijn is. Een correlatiecoëfficiënt is dus geen richtingscoëfficiënt (hellingsgetal).
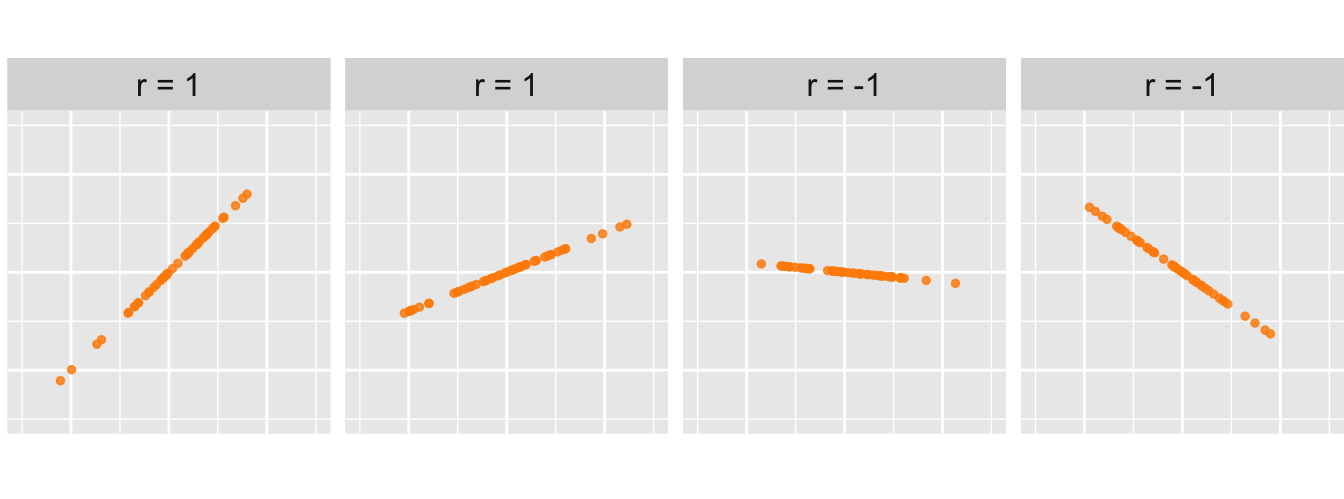
Bijvoorbeeld, de steekproeven in Figuur 28.4 hieronder verschillen sterk in hun richtingscoëfficiënt, maar hebben allemaal \(r = 1\) of \(-1\).
Code
# Definieer parametersn <-50correlaties <-c(1, 1, -1, -1)std_y <-c(1, 0.4, 0.1, 0.7)custom_labels <-c("1"="r = 1", "2"="r = 1", "3"="r = -1", "4"="r = -1")# Functie om bivariate normaal verdeelde data te genererengenereer_data <-function(rho, sigma_y, groep) { sigma <-matrix(c(1, rho * sigma_y, rho * sigma_y, sigma_y^2), nrow =2)set.seed(groep) data <- MASS::mvrnorm(n, mu =c(0, 0), Sigma = sigma)data.frame(X = data[, 1], Y = data[, 2], groep = groep)}# Genereer datasetsdatasets <-do.call( rbind, Map(genereer_data, correlaties, std_y, groep =1:4) )# Maak de ggplot met facet_wrapp <-ggplot(datasets, aes(x = X, y = Y)) +geom_point(color = puntkleur1, alpha =0.8, size =1) +facet_wrap(~ groep, nrow =1, labeller =as_labeller(custom_labels)) +coord_fixed(xlim =c(-3, 3), ylim =c(-3, 3)) +# theme_minimal() +theme(axis.text =element_blank(),axis.ticks =element_blank(),strip.text =element_text(size =12),plot.margin =margin(0, 0, 0, 0) ) +labs(x =NULL, y =NULL)# Print de plotprint(p)
Figuur 28.4: Bij al deze steekproeven is de correlatiecoëfficiënt 1 of -1. De correlatiecoëfficiënt geeft aan in hoeverre de punten op een rechte lijn vallen, niet hoe steil die lijn is.
Oefening 28.1 (Correlatiecoëfficiënten schatten)
Kijk terug naar de gegevens van Galton, Figuur 28.1, en vergelijk de plot met de puntenwolken in Figuur 28.3. Schat op het oog de correlatiecoëfficiënt van Galtons gegevens.
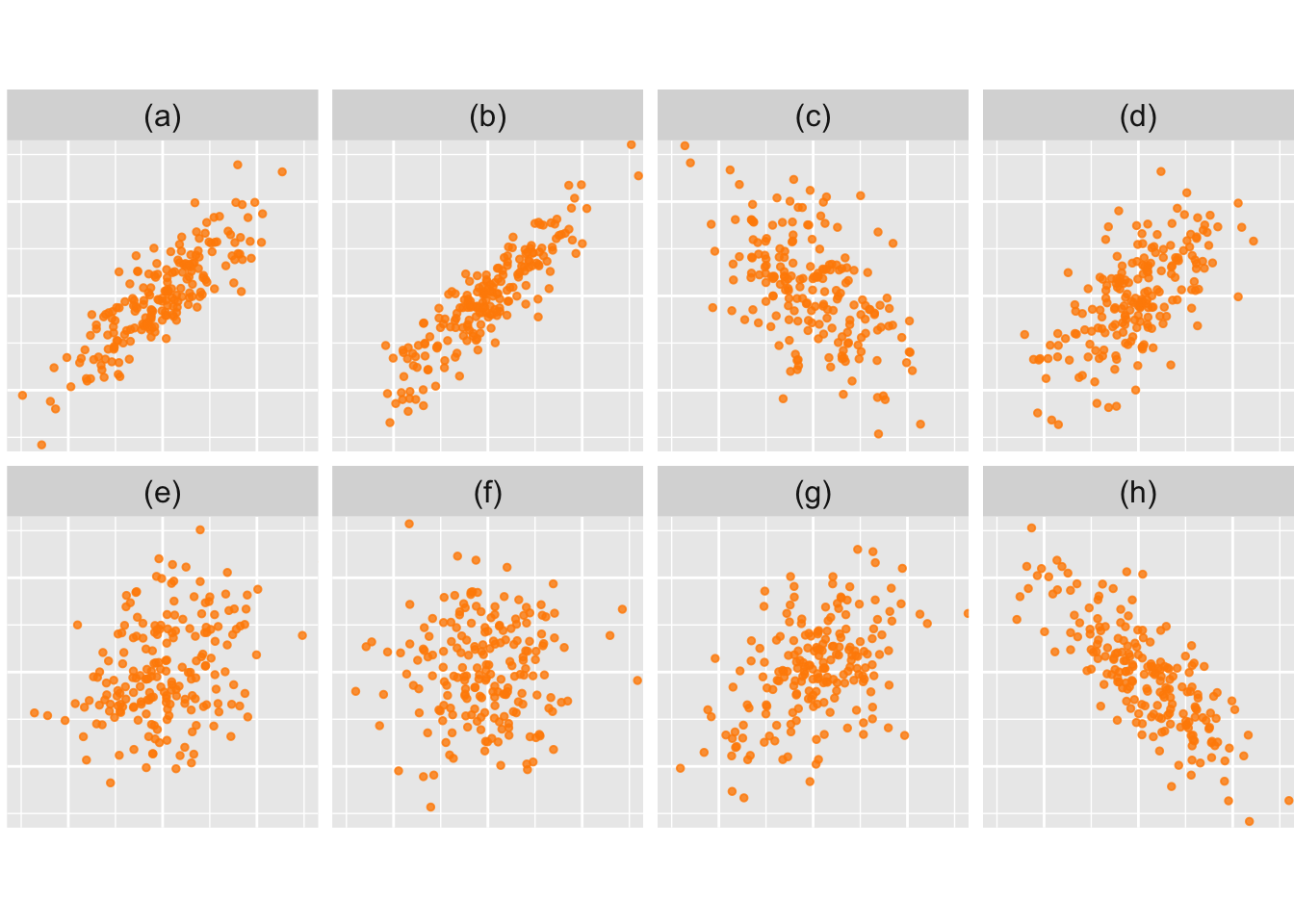
Hieronder zijn 8 puntenwolken gegeven. Schat op het oog de correlatiecoëfficiënten.
Figuur 28.5: Wat zijn de correlatiecoëfficiënten?
De correlatiecoëfficiënt is alleen betekenisvol voor lineaire relaties
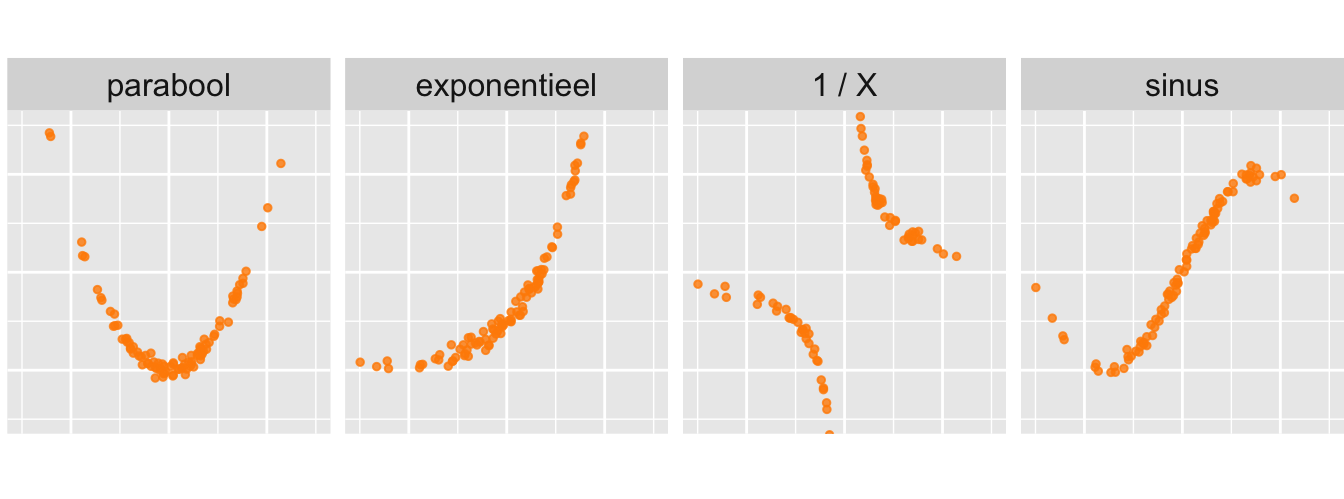
Pearsons correlatiecoëfficiënt is bedoeld om lineaire relaties te beschrijven. De grafieken in Figuur 28.6 hieronder laten variabelen \(X\) en \(Y\) zien die wel een relatie hebben—de waarde van \(Y\) hangt wel af van de waarde van \(X\)—maar de relaties zijn steeds niet lineair. Het is dan niet nuttig om \(r\) uit te rekenen.
Code
# Definieer parametersn <-100sigma_y <-0.1# Kleine variantie voor de foutencustom_labels <-c("1"="parabool", "2"="exponentieel", "3"="1 / X", "4"="sinus")# Functie om niet-lineaire relaties te genererengenereer_data <-function(x, f, groep) {set.seed(groep) y <-f(x) +rnorm(n, mean =0, sd = sigma_y)data.frame(X = x, Y = y, groep = groep)}# Genereer waarden voor Xset.seed(42)x <-rnorm(n, mean =0, sd =1)# Definieer niet-lineaire functiesfuncties <-list(function(x) .8*x^2-2, # Paraboolfunction(x) exp(x) -2, # Exponentiële groeifunction(x) 1/ (x), # 1/x, met verschuiving om singulariteit te vermijdenfunction(x) 2*sin(x) # Sinusfunctie)# Genereer datasetsdatasets <-do.call( rbind, Map(genereer_data, list(x, x, x, x), functies, groep =1:4) )# Maak de ggplot met facet_wrapp <-ggplot(datasets, aes(x = X, y = Y)) +geom_point(color = puntkleur1, alpha =0.8, size =1) +facet_wrap(~ groep, nrow =1, labeller =as_labeller(custom_labels)) +coord_fixed(xlim =c(-3, 3), ylim =c(-3, 3)) +# theme_minimal() +theme(axis.text =element_blank(),axis.ticks =element_blank(),strip.text =element_text(size =12),plot.margin =margin(0, 0, 0, 0) ) +labs(x =NULL, y =NULL)# Print de plotprint(p)
Figuur 28.6: Voorbeelden van niet-lineaire relaties. Als een relatie niet lineair is, vertelt \(r\) je weinig tot niets. Het heeft dan geen zin om \(r\) uit te rekenen.
De correlatiecoëfficiënt is gevoelig voor uitbijters
De correlatiecoëfficiënt is erg gevoelig voor uitbijters. Zie Figuur 28.7 hieronder. Zonder de uitbijter rechtsboven zou de correlatiecoëfficiënt 0 zijn, maar door dat ene datapunt is de waarde 0,4. Bekijk je gegevens dus altijd nauwkeurig voordat je \(r\) uitrekent. Als het verband er niet lineair uitziet óf er opvallende uitbijters zijn, is de waarde van \(r\) niet betekenisvol. Omdat dit punt heel belangrijk is, komen we er in Oefening 28.8 nog een keer op terug.
Code
# Genereer data met constante Y behalve één uitschieterset.seed(456)n <-20X <-runif(n, -2, 2)Y <-rep(0, n)Y[n] <-5# uitschieter op laatste puntX[n] <-2data <-data.frame(X = X, Y = Y)# Bereken de correlatiecoëfficiënt#correlatie <- cor(data$X, data$Y)#cat("Correlatiecoëfficiënt:", round(correlatie, 3), "\n")# Maak de plotggplot(data, aes(x = X, y = Y)) +geom_point(color = puntkleur1) +# geom_smooth(method = "lm", se = FALSE,# color = "orange", linewidth = 1) +labs(x =expression(italic(X)), y =expression(italic(Y))) +theme_minimal() +theme(axis.text.x =element_blank(),axis.text.y =element_blank() ) +annotate("text", x =-1.5, y =4.5,label =expression(italic(r) ==0.4),size =4) +coord_cartesian( ylim =c(-1, 5.5) )
Figuur 28.7: De correlatiecoëfficiënt is erg gevoelig voor uitbijters. Zonder uitbijter zou de correlatiecoëfficiënt 0 zijn; met de uitbijter 0,4.
De correlatiecoëfficiënt kan afhangen van het bereik van de \(X\)-waarden
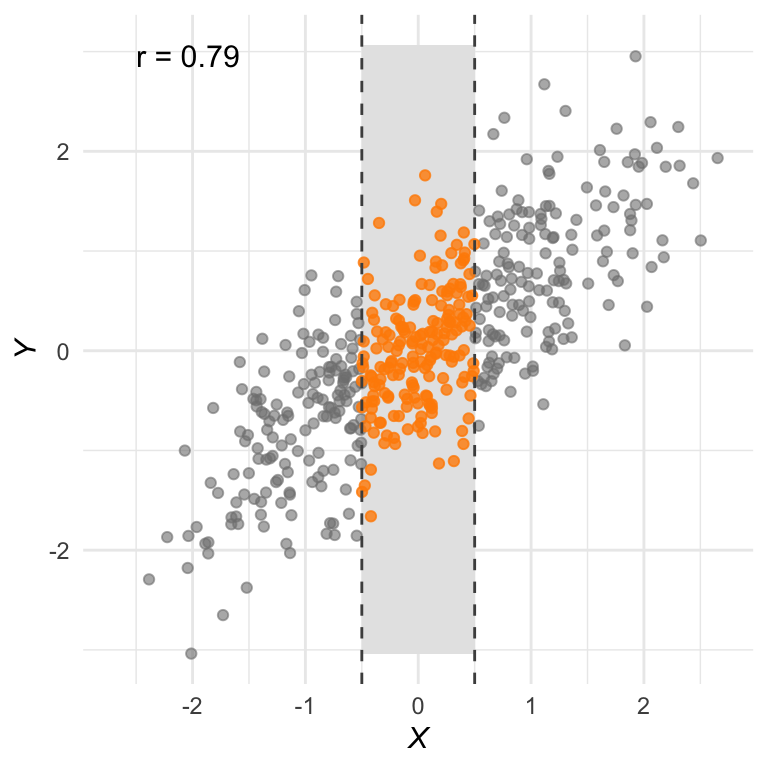
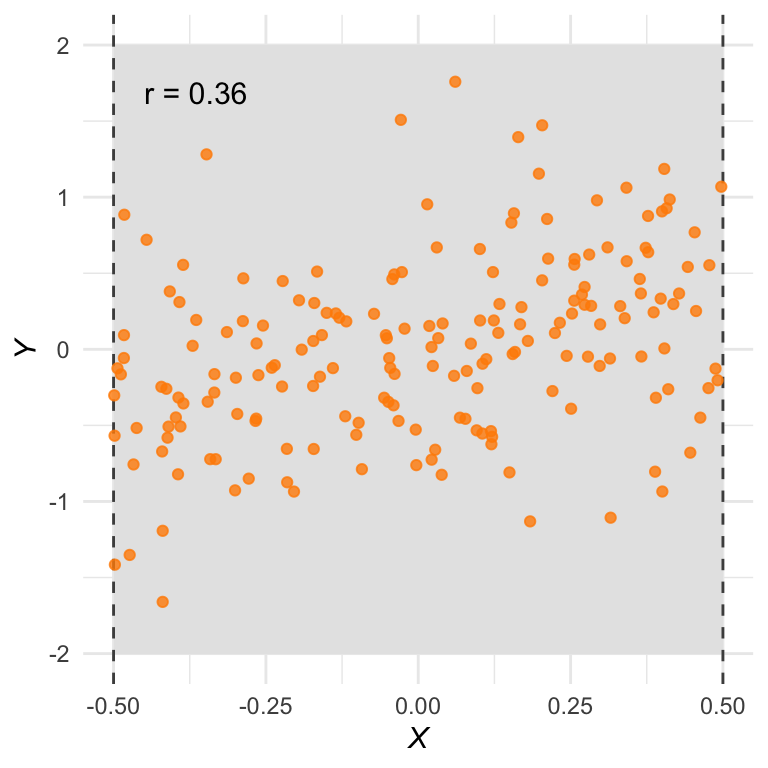
Figuur 28.8 (a) is een plot van variabelen die sterk met elkaar samenhangen. De correlatiecoëfficiënt is dan ook \(r = 0{,}79\).
Maar stel dat we de analyse beperken tot alleen het middelste gedeelte van het domein. We selecteren de oranje datapunten en plotten die los in Figuur 28.8 (b). Nu is de correlatiecoëfficiënt een stuk kleiner: \(r = 0{,}36\)! Op het oog kun je ook goed zien waarom: als het bereik zo klein is, volgen de datapunten veel minder duidelijk een lineaire trend.
Hou dit goed in gedachte bij het interpreteren van gegevens. Als er tussen twee variabelen geen duidelijk verband wordt gevonden, kan dat liggen aan een gebrek aan variatie in de \(X\)-waarden. Een andere studie met meer variatie kan dan mogelijk wél een correlatie aantonen.
(a) Dataset met een sterk positieve correlatie (\(r = 0{,}79\)).
(b) Als de dataset wordt beperkt tot een kleiner domein—het oranje gedeelte van panel(a)—wordt de correlatiecoëfficiënt een stuk kleiner (\(r = 0{,}36\)). Dat is niet gek: de puntenwolk volgt nu ook veel minder duidelijk een rechte lijn.
Figuur 28.8: Het bereik van de dataset kan een grote invloed hebben op de correlatiecoëfficiënt.
De covariantie
Tot nu toe hebben we de eigenschappen van de correlatiecoëfficiënt besproken zonder te vertellen hoe je die uitrekent. Dat is het volgende op het programma.
Het is handig om eerst de covariantie te definiëren tussen de gegevens \(x_i\) en \(y_i\) in een steekproef of serie waarnemingen:
Voor iedere eenheid \(i\) uit onze waarnemingen rekenen we eerst de afwijkingen \(x_i - \overline{x}\) en \(y_i - \overline{y}\) uit en vermenigvuldigen die. Vervolgens tellen we de resultaten op en delen we door \(n - 1\).
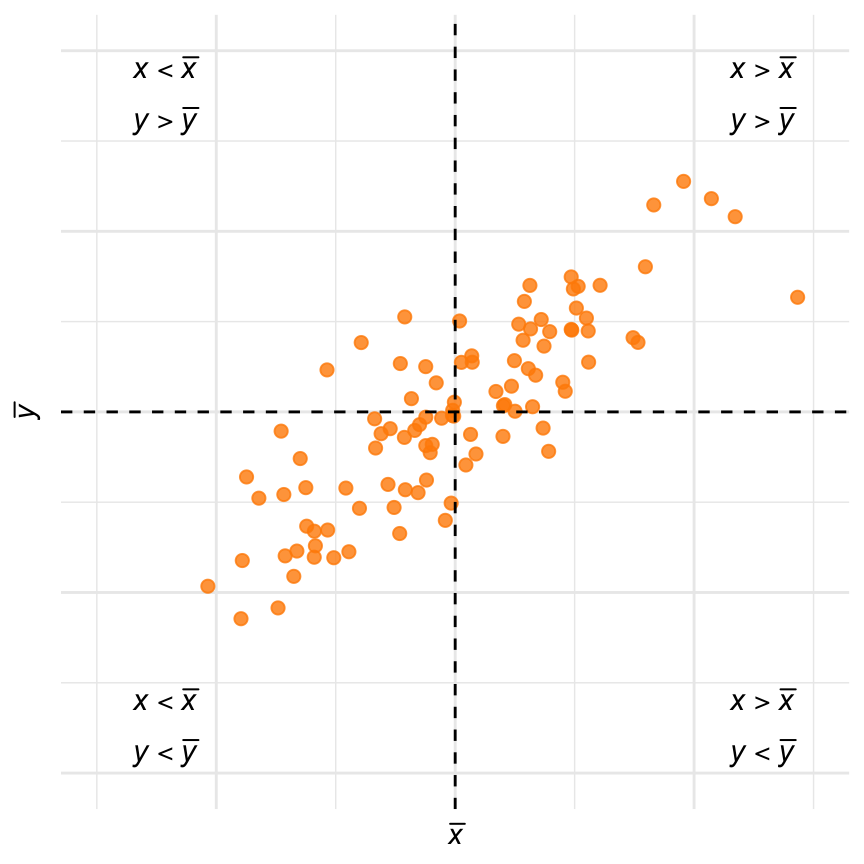
De covariantie meet de mate waarin de \(x\)- en \(y\)-waarden lineair met elkaar samenhangen. Figuur 28.9 illustreert dat.
Code
# Definieer parametersn <-100# Steekproefgrootterho <-0.85# Correlatiecoëfficiëntset.seed(158)# Genereer bivariate normale datasigma <-matrix(c(1, rho, rho, 1), nrow =2)data <- MASS::mvrnorm(n, mu =c(0, 0), Sigma = sigma)df <-data.frame(X = data[, 1], Y = data[, 2])# Bereken gemiddeldenmean_x <-mean(df$X)mean_y <-mean(df$Y)df$X <- df$X - mean_xdf$Y <- df$Y - mean_y# Maak de scatterplotp <-ggplot(df, aes(x = X, y = Y)) +geom_point(color = puntkleur1, alpha =0.8, size =2) +geom_vline(xintercept =0, linetype ="dashed") +geom_hline(yintercept =0, linetype ="dashed") +annotate("text", x =2.3, y =3.5, label =expression(atop(italic(x) >bar(italic(x)), italic(y) >bar(italic(y)))), size =5, hjust =0) +annotate("text", x =-2.7, y =3.5, label =expression(atop(italic(x) <bar(italic(x)), italic(y) >bar(italic(y)))), size =5, hjust =0) +annotate("text", x =2.3, y =-3.5, label =expression(atop(italic(x) >bar(italic(x)), italic(y) <bar(italic(y)))), size =5, hjust =0) +annotate("text", x =-2.7, y =-3.5, label =expression(atop(italic(x) <bar(italic(x)), italic(y) <bar(italic(y)))), size =5, hjust =0) +theme_minimal() +theme(axis.text =element_blank(),axis.ticks =element_blank() ) +labs(x =expression(bar(italic(x))), y =expression(bar(italic(y)))) +coord_cartesian(xlim =c(-3, 3), ylim =c(-4, 4))# Print de plotprint(p)
Figuur 28.9: Spreidingsdiagram met vier kwadranten. De covariantie wordt positief beïnvloed door punten in de kwadranten rechtsboven en linksonder, en negatief door punten in de kwadranten linksboven en rechtsonder.
Het figuur laat een spreidingsdiagram zien met een positieve correlatie. Het diagram is in vier kwadranten verdeeld door met een verticale onderbroken lijn het gemiddelde van \(x\) aan te geven en met een horizontale onderbroken lijn het gemiddelde van \(y\).
In het kwadrant rechtsboven liggen alle datapunten waarbij \(x_i > \overline{x}\), en \(y_i > \overline{y}\). Het product \((x_i - \overline{x})(y_i - \overline{y})\) is voor die punten dus positief. Deze punten dragen dus positief bij aan de waarde van de covariantie (Vergelijking 28.1). Punten die ver in de rechts-bovenhoek van het diagram liggen, dragen het sterkst bij, want daarvoor zijn \(x_i - \overline{x}\) en \(y_i - \overline{y}\) het grootst.
In het kwadrant linksonder liggen alle datapunten waarbij \(x_i < \overline{x}\), en \(y_i < \overline{y}\). Het product \((x_i - \overline{x})(y_i - \overline{y})\) is voor die punten ook positief. Punten in dit kwadrant dragen dus óók positief bij; de punten ver in de links-onderhoek het sterkst.
In het kwadrant linksboven liggen alle datapunten waarbij \(x_i < \overline{x}\), en \(y_i > \overline{y}\). Het product \((x_i - \overline{x})(y_i - \overline{y})\) is nu altijd negatief. In Vergelijking 28.1 leveren deze punten dus een negatieve bijdrage. Hetzelfde geldt voor het kwadrant rechtsonder, waar \(x_i > \overline{x}\), en \(y_i < \overline{y}\).
Het gevolg is dat de covariantie positief is als de meeste datapunten rechtsboven of linksonder in de plot te vinden zijn. Dat zou inderdaad betekenen dat er een positieve relatie is.
Bij de berekening van de covariantie vermenigvuldigen we steeds een waarde van \(X\) met een waarde van \(Y\). Daardoor is de dimensie van de covariantie gelijk aan de dimensie van \(X\) vermenigvuldigd met de dimensie van \(Y\). Bijvoorbeeld, in de gegevens van Galton hebben \(X\) en \(Y\) allebei de dimensie van lengte, met eenheid cm. De covariantie van die gegevens heeft dus dimensie lengte\(^2\) en eenheid cm\(^2\).
Oefening 28.2 (De relatie tussen variantie en covariantie)
Stel dat we de covariantie van \(X\) met zichzelf berekenen, \(C_{XX}\). Wat is daarvoor de formule? (Vervang in Vergelijking 28.1 elke \(y\) door een \(x\), en versimpel de vergelijking een beetje.)
Vergelijk het resultaat van onderdeel a met Vergelijking 20.4. Wat valt je op?
De variantie \(V_{X}\) is altijd positief, en dus \(C_{XX}\) ook. Had je dat kunnen verwachten?
De formule voor Pearsons correlatiecoëfficiënt
Nu we weten wat de covariantie is, kunnen we de formule voor Pearsons correlatiecoëfficiënt schrijven als:
\[
r = \frac{C_{XY}}
{s_X s_Y}.
\tag{28.2}\]
De correlatiecoëfficiënt is dus de covariantie gedeeld door de standaarddeviaties van \(X\) en \(Y\). Het delen door beide standaarddeviaties zorgt ervoor dat \(r\) tussen -1 en 1 ligt.
Omdat \(s_X\) en \(s_Y\) alleen maar positief kunnen zijn, heeft \(r\) altijd hetzelfde teken als \(C_{XY}\). Als de covariantie positief is, is \(r\) dat dus ook.
Oefening 28.3 (De correlatie van \(X\) met \(X\))
In Oefening 28.2 heb je laten zien dat \(C_{XX}\) gelijk is aan \(V_X\).
Wat is volgens Vergelijking 28.2 dan de correlatiecoëfficiënt van \(X\) met zichzelf? Is dat wat je zou verwachten?
Correlatie-coëfficiënt berekenen met R
Met R kun je de covariantie tussen twee vectoren heel eenvoudig berekenen. Laten we dat doen voor de gegevens van Galton. Het dataframe heet GaltonFamilies:
De covariantie is positief, zoals verwacht. Maar omdat de covariantie afhangt van de eenheden en schaal van de variabelen, is het getal zelf lastig te interpreteren.
Daarom berekenen we de correlatiecoëfficiënt. Dat gaat ook erg gemakkelijk:
De correlatiecoëfficiënt tussen de lengte van ouders en hun kinderen is in de dataset van Galton dus 0,50. (Had je dat in Oefening 28.1 al zo ingeschat?)
28.3 Toets van de correlatiecoëfficiënt
Als we in een steekproef of serie waarnemingen een correlatie zien tussen twee variabelen, dan kan dat betekenen dat deze variabelen gecorreleerd zijn in de populatie. Maar het is ook mogelijk dat de correlatie in de waarnemingen het gevolg is van toevallige steekproevenvariabiliteit. Is er een manier om dat te toetsen? In andere woorden: kunnen we laten zien dat deze gegevens sterk bewijs leveren tegen de hypothese dat de correlatiecoëfficiënt van de populatie, \(\rho\), gelijk is aan 0?
Omdat we al meerdere hypothesetoetsen besproken hebben, kunnen we deze toets snel behandelen. We lopen de 6 stappen door:
Stap 1: Kies een statistisch model.
In eerdere hoofdstukken ging het statistisch model steeds over de kans op een waarneming \(X\). Nu moeten we een stapje verder gaan, omdat iedere waarneming nu twee waardes inhoudt: een waarde van \(X\) en een waarde van \(Y\). We hebben dus een statistisch model nodig voor de verdeling van van datapunten \((X, Y)\) in de populatie.
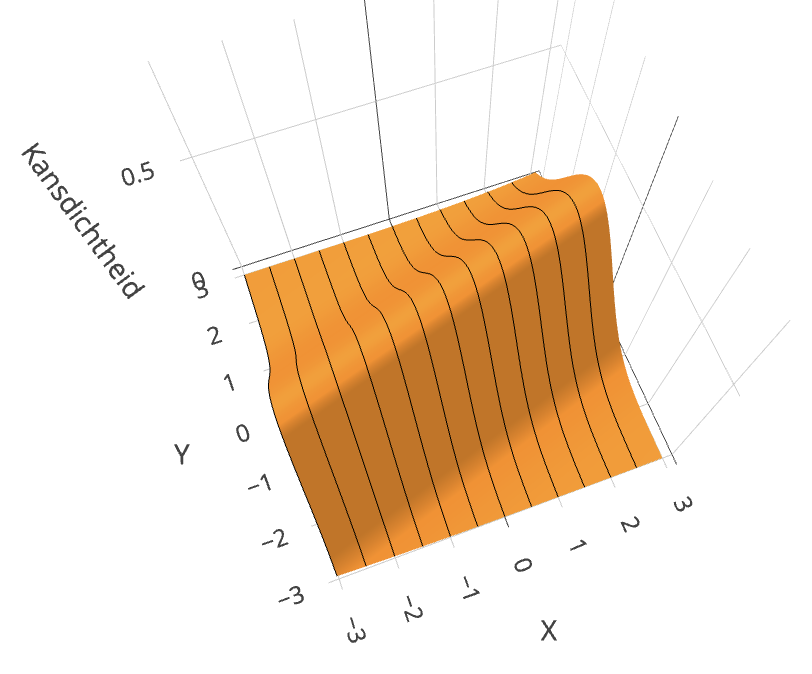
Bij deze toets nemen we aan dat de verdeling in de populatie bivariaat normaal is. Figuur 28.10 laat zien hoe een bivariate normale verdeling eruit ziet. Het is een 3D plot: de hoogte van de grafiek geeft de kansdichtheid, die afhangt van zowel de waarde van \(X\) als van de waarde van \(Y\). Je kunt met je muis de grafiek bewegen om ’m van alle kanten te bekijken.
We nemen ook aan dat ieder datapunt onafhankelijk uit de verdeling getrokken is.
Interactieve content beschikbaar op de website:
Visualisatie van de bivariate normale verdeling met \(\rho = 0.5\).
Figuur 28.10: Visualisatie van de bivariate normale verdeling met \(\rho = 0.5\). Je kunt met je muis de grafiek ronddraaien en in- en uitzoomen.
De bivariate normale verdeling heeft een aantal belangrijke eigenschappen.
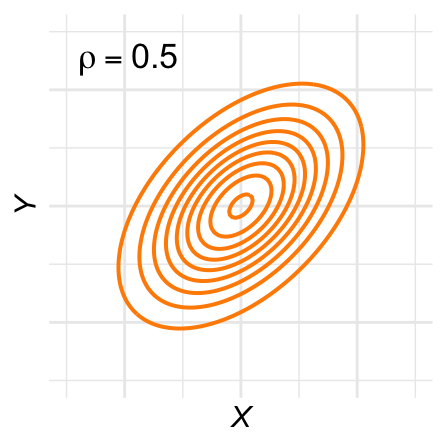
Vijf parameters: De bivariate normale verdeling heeft vijf parameters: de gemiddelden van \(X\) en \(Y\), de standaarddeviaties van \(X\) en \(Y\), en de correlatiecoëfficiënt van de populatie \(\rho\). In het voorbeeld van Figuur 28.10 is \(\mu_X = \mu_Y = 0\), \(\sigma_X = \sigma_Y = 1\), en \(\rho = 0{,}5\).
Beide variabelen zijn normaal verdeeld: Zowel \(X\) als \(Y\) zijn normaal verdeeld.
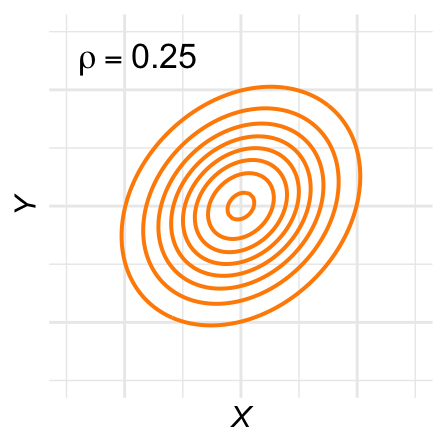
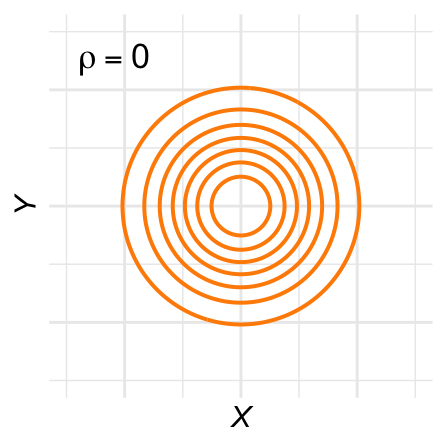
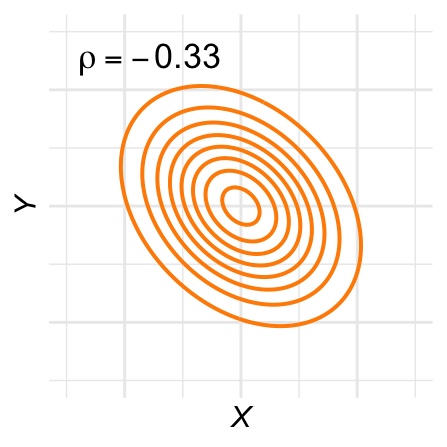
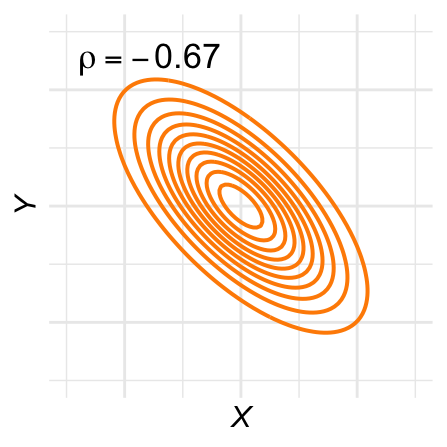
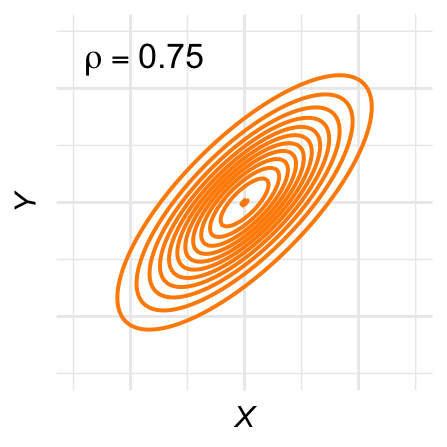
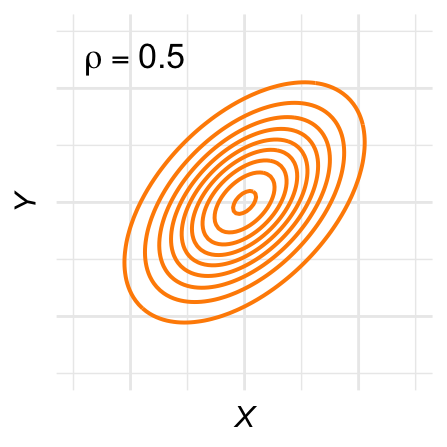
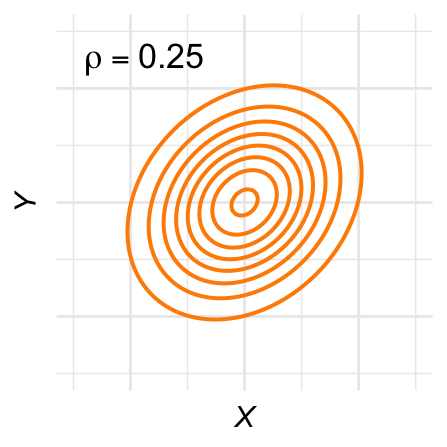
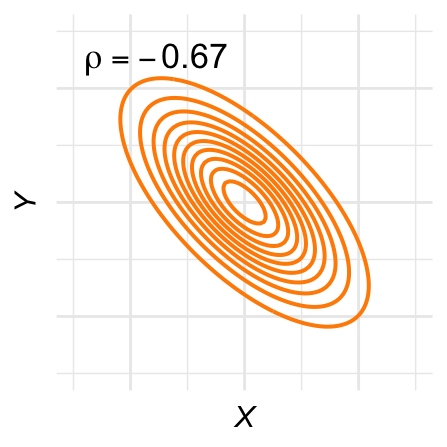
De contour-lijnen zijn ovaal: De hoogtelijnen van de bivariate normale verdeling, ook wel contour-lijnen genoemd, zijn ovaal. Figuur 28.11 laat een aantal voorbeelden zien voor verschillende waarden van \(\rho\).
Het gevolg is dat steekproeven uit de bivariate normale verdeling ook ongeveer een ovale of ronde puntenwolk vormen. De steekproeven die we in Figuur 28.3 als voorbeeld gebruikten, zijn ieder uit een bivariate normale verdeling getrokken.
Figuur 28.11: Contour-plots voor verschillende bivariaat-normale verdelingen.
Stap 2: Stel de hypotheses \(H_\textrm{0}\) en \(H_\textrm{A}\) op.
De nulhypothese is dat \(X\) en \(Y\) niet gecorreleerd zijn in de populatie. Dat wil zeggen:
\(H_\textrm{0}:\qquad \rho = 0,\)
\(H_\textrm{A}:\qquad \rho \neq 0.\)
Stap 3: Kies de toetsingsgrootheid en bepaal zijn kansverdeling onder \(H_\textrm{0}\).
Als toetsingsgrootheid gebruiken we de correlatiecoëfficiënt uit de steekproef \(r\), gedeeld door de bijbehorende standaardfout:
\[ t = \frac{r}{\mathrm{SE}_{r}}. \tag{28.3}\]
Die standaardfout kan met deze formule worden berekend:
\[ \mathrm{SE}_{r} = \sqrt{\frac{1 - r^2}{n - 2}}. \tag{28.4}\] Je voelt het misschien al aankomen: de kansverdeling onder \(H_\textrm{0}\) van deze \(t\) is weer een \(t\)-verdeling. Maar deze keer met \(n - 2\) vrijheidsgraden.
Stap 4: Bereken de toetsingsgrootheid op basis van de daadwerkelijke waarnemingen. Hiervoor vul je dus de formules Vergelijking 28.4 en Vergelijking 28.3 in op basis van de steekproef.
Stap 5: Bereken de \(P\)-waarde.
Net als bij de \(t\)-toetsen in Hoofdstuk 26 kun je de \(P\)-waarde berekenen met de functie pt(). Let wel op dat je het juiste aantal vrijheidsgraden gebruikt:
P <-2*pt(-abs(t), df = n -2)
Stap 6: Trek je conclusies
Trek op basis van \(P\) je conclusies.
Oefening 28.4 (Correlatietoets van de gegevens van Galton)
We zouden de correlatietoets graag willen toepassen op de gegevens van Galton, om te zien of we uit zijn gegevens kunnen concluderen dat lichaamslengte inderdaad deels erfelijk is.
Kijk nog eens naar het spreidingsdiagram van de gegevens, Figuur 28.1. Geven deze gegevens de indruk afkomstig te zijn uit een bivariate normale verdeling, of zie je afwijkingen?
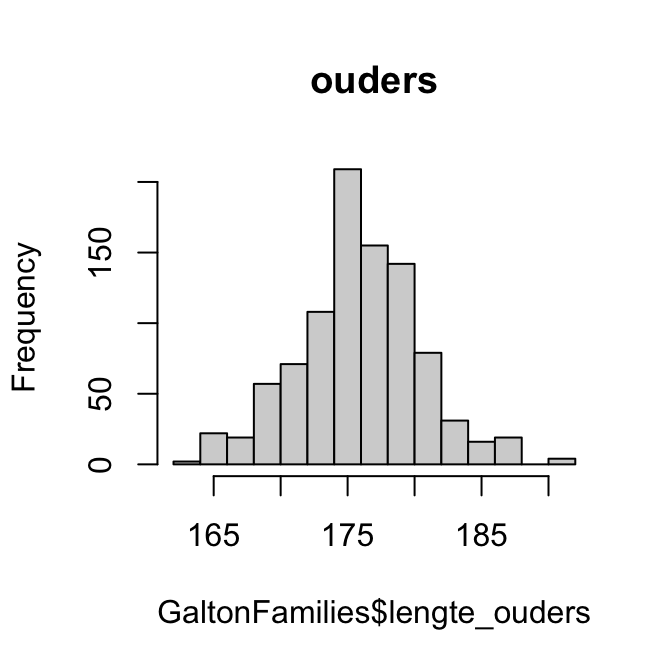
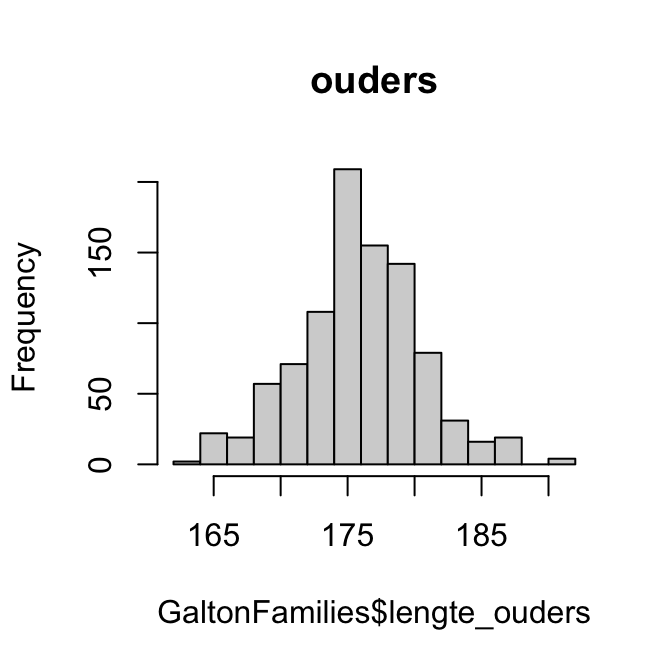
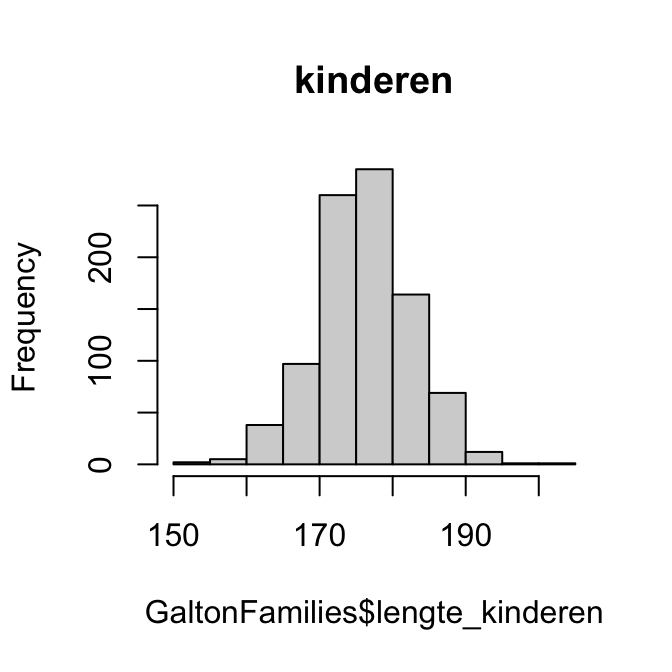
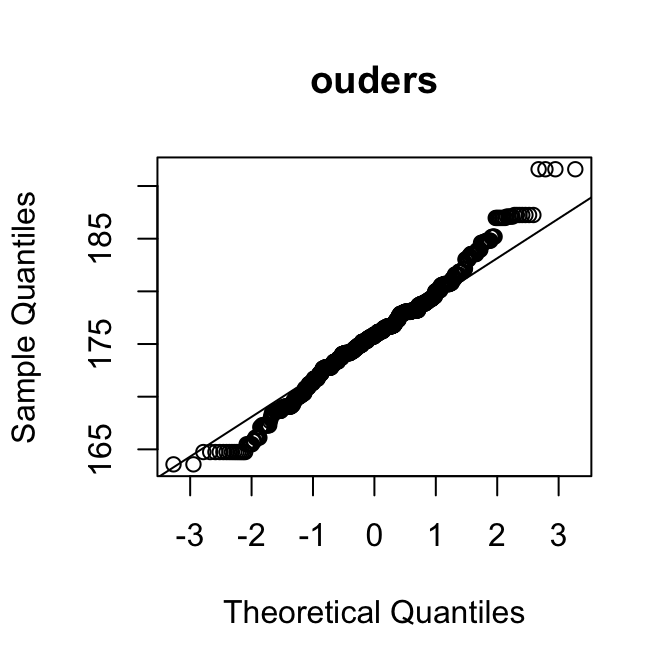
Als de verdeling bivariaat normaal is, dan zouden de lengtes van de ouders en de lengtes van de kinderen allebei normaal verdeeld moeten zijn. We kunnen kijken of we afwijkingen zien door histogrammen en QQ-plots te maken van beide variabelen:
Code
hist(GaltonFamilies$lengte_ouders, main ="ouders")hist(GaltonFamilies$lengte_kinderen, main ="kinderen")qqnorm(GaltonFamilies$lengte_ouders, main ="ouders")qqline(GaltonFamilies$lengte_ouders)qqnorm(GaltonFamilies$lengte_kinderen, main ="kinderen")qqline(GaltonFamilies$lengte_kinderen)
Wat is jouw oordeel?
Het statistische model neemt ook aan dat alle paren datapunten \((x_i, y_i)\) onafhankelijk uit de bivariaat normale kansverdeling zijn getrokken.
Om te bepalen of dat een redelijke aanname is, moeten we meer weten over de manier waarop Galton deze dataset samenstelde.
Lees de beschrijving van de dataset via deze link.
Lijkt het je redelijk om aan te nemen dat de datapunten onafhankelijk zijn?
De toets uitvoeren met R
Het is weer veel eenvoudiger om de volledige toets met R uit te voeren, met de functie cor.test(). We laten het aan de hand van een voorbeeld zien:
Voorbeeld 28.2 (De correlatie tussen flipper-lengte en gewicht bij Adelie-pinguïns)
In Hoofdstuk 26 heb je al kennisgemaakt met de dataset palmerpenguins, met gegevens over pinguïns in de Palmer-archipel. In die dataset is ook voor alle pinguïns de flipperlengte (flipper_length_mm) en het lichaamsgewicht (body_mass_g) opgenomen. Je zou verwachten dat dat zwaardere pinguïns ook typisch langer flippers hebben. We gaan dat testen voor de soort Adelie. Bestudeer ook de code voor ieder stap, zodat je het straks ook zelf kunt.
We hebben de gegevens over de Adelie-pinguïns opgeslagen in een dataframe adelie.
Er lijkt inderdaad een positief verband te bestaan tussen lichaamsgewicht en flipperlengte. De puntenwolk ziet er redelijk ovaal uit, consistent met een bivariate normale verdeling, en er zijn geen bijzondere uitbijters te zien.
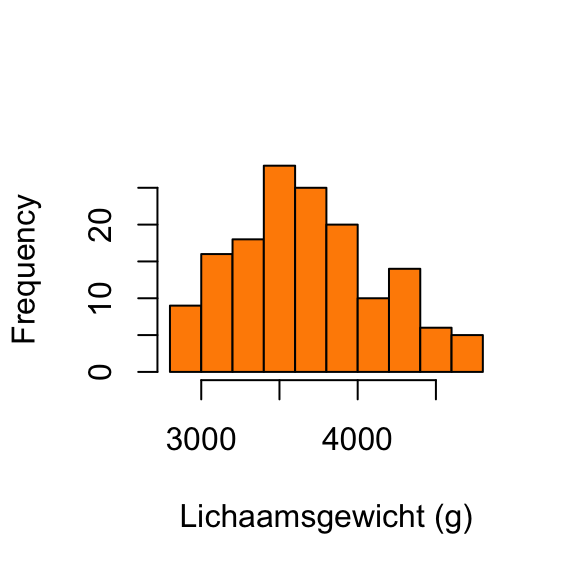
Om verder te controleren of het bivariate model redelijk is, bekijken we de verdelingen van beide variabelen:
Code
# Histogrammen met base Rhist(adelie$body_mass_g,main =NULL,xlab ="Lichaamsgewicht (g)",col = opvulkleur, border ="black")hist(adelie$flipper_length_mm,main =NULL,xlab ="Flipperlengte (mm)",col = opvulkleur, border ="black")# QQ-plotsqqnorm(adelie$body_mass_g, main ="QQ-plot lichaamsgewicht")qqline(adelie$body_mass_g)qqnorm(adelie$flipper_length_mm, main ="QQ-plot flipperlengte")qqline(adelie$flipper_length_mm)
Lichaamsgewicht lijkt iets asymmetrisch, maar de afwijking is erg subtiel.
Aangenomen dat de steekproef redelijk aselect heeft plaatsgevonden, kunnen we de toets uitvoeren:
Pearson's product-moment correlation
data: adelie$body_mass_g and adelie$flipper_length_mm
t = 6.4678, df = 149, p-value = 1.343e-09
alternative hypothesis: true correlation is not equal to 0
95 percent confidence interval:
0.3334071 0.5842379
sample estimates:
cor
0.4682017
De uitvoer geeft direct de \(P\)-waarde: \(P = 1{,}3\times 10^{-9}\). Die \(P\)-waarde is heel erg klein en laat weinig ruimte voor twijfel over de samenhang tussen gewicht en flipperlengte.
De uitvoer geeft ook een 95%-BHI voor de correlatiecoëfficiënt van de populatie: \([0{,}33, 0{,}58]\). We zijn dus 95% zeker dat de ware correlatiecoëfficiënt in dat interval ligt.
Oefening 28.5 (Assorted mating bij mensen?)
Met de gegevens van Galton kan nog een andere vraag worden onderzocht: is er een correlatie tussen de lichaamslengtes van mannen en vrouwen binnen een echtpaar? Dat zou een voorbeeld zijn van assorted mating bij mensen!
De gegevens van Galton zijn te vinden in de library HistData. Als je die nog niet geïnstalleerd hebt, doe dat dan nu even:
install.packages("HistData", dependencies =TRUE)
Begin een nieuw script. Kopieer de volgende code om de dataset in te lezen en de gegevens te bekijken:
Merk op dat iedere regel de gegevens bevat van een kind en de bijbehorende ouders. Omdat dezelfde ouders vaak meerdere kinderen hebben, staan dezelfde ouders meerdere keren in de dataset. Wij willen voor deze analyse ieder ouderpaar maar één keer analyseren, en dus moeten we de gegevens filteren.
Kopieer de volgende code naar je script en voer die uit:
# Vind de eerste rij per unieke familieeerste_index <-match(unique(GaltonFamilies$family), GaltonFamilies$family)# Selecteer alleen die rijen, en houd alleen de relevante kolommenouders_uniek <- GaltonFamilies[ eerste_index, c("family", "father", "mother") ]
Bekijk ouders_uniek, bijvoorbeeld met str(ouders_uniek).
Voeg een regel code toe om een plot te maken waarin de lichaamslengte van de moeder wordt uitgezet tegen die van de vader. Vermoed jij een verband?
We moeten controleren of het statistische model voor de correlatietoets redelijk is voor deze gegevens. Maak daarom histogrammen en QQ-plots voor beide variabelen. Wat concludeer je?
Voer de toets uit met de functie cor.test(), bekijk de uitvoer, en trek je conclusies. Zie je bewijs voor assorted mating?
28.4 De regressielijn
Wanneer \(X\) en \(Y\) lineair met elkaar samenhangen, geeft de waarde van \(X\) informatie over de waarde van \(Y\). We kunnen \(Y\) dan tot op zekere hoogte voorspellen als we \(X\) weten.
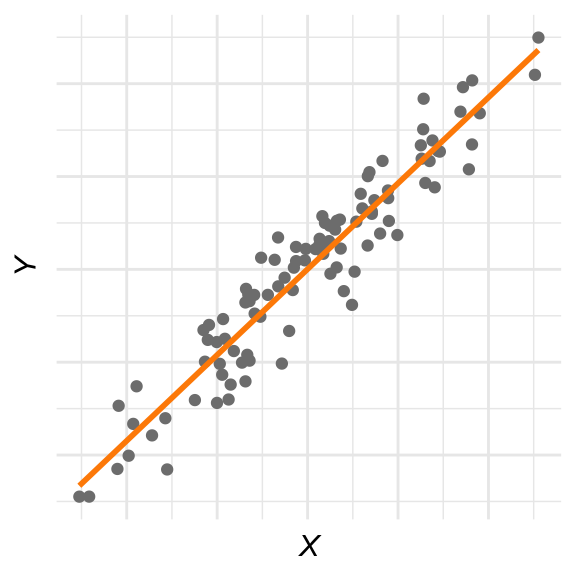
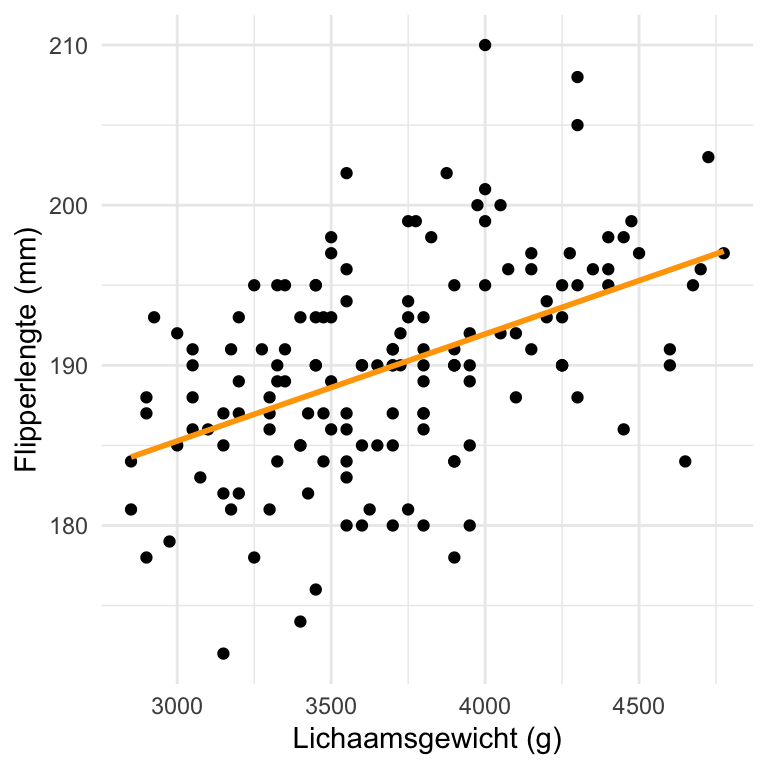
Om dat te kunnen doen, zoeken we een rechte lijn die de puntenwolk het beste beschrijft. Zo’n lijn wordt de regressielijn genoemd. Hieronder hebben we de gegevens uit Voorbeeld 28.2 opnieuw weergegeven, maar nu is de regressielijn toegevoegd:
Figuur 28.12: De regressielijn waarmee de flipper-lengte van Adelie-pinguïns voorspeld kan worden op basis van hun gewicht.
We kunnen deze lijn gebruiken om voorspellingen te doen. Bijvoorbeeld, als je te weten komt dat een pinguïn een gewicht heeft van 4500 g, dan zegt de lijn dat zijn flipperlengte rond de 195mm zal liggen. Bij een pinguïn van 3000g ligt dat meer rond 185mm. Omdat het verband tussen gewicht en flipperlengte niet volmaakt is, is die voorspelling natuurlijk een schatting; de daadwerkelijke flipperlengte kan wat groter of kleiner zijn. Hoe sterker het verband is, hoe beter de voorspelling.
De definitie van de regressielijn
Zoals je weet, heeft een rechte lijn de volgende vorm: \[ Y = a + b X . \] Hier is \(a\) het startgetal, en \(b\) de richtingscoëfficiënt. De parameters \(a\) en \(b\) van de regressielijn worden regressiecoëfficiënten genoemd.
WaarschuwingVerwarring over \(a\) en \(b\)!
Let op: in veel Nederlandse schoolboeken worden in de definitie van een rechte lijn de symbolen \(a\) en \(b\) precies andersom gebruikt: het startgetal heet dan \(b\) en de richtingscoëfficiënt \(a\). Als je dat gewend bent, zul je even scherp moeten zijn.
Om de regressielijn te bepalen moeten we dus waarden voor \(a\) en \(b\) vastleggen. We willen \(a\) en \(b\) zo kiezen dat de lijn zo goed mogelijk de puntenwolk beschrijft. Om precies te zijn: we willen dat de lijn voor iedere waarde \(X\) een schatting geeft voor de gemiddelde waarde van \(Y\). Figuur 28.13 hieronder illustreert hoe we dat doen.
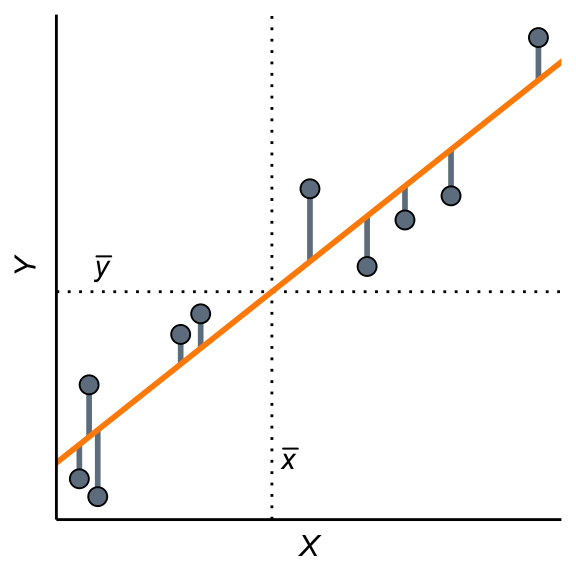
Figuur 28.13: De regressielijn minimaliseert de som van gekwadrateerde residuen. Het is alsof de grijze lijntjes elastiekjes zijn die de lijn naar de datapunten toetrekken.
Als het goed is, doet Figuur 28.13 je denken aan Figuur 20.13 uit Paragraaf 20.7.3. Daar lieten we zien dat het gemiddelde van een reeks getallen de waarde is waarvoor de som van de gekwadrateerde residuen zo klein mogelijk was. In Figuur 20.13 waren de residuen (afwijkingen van het gemiddelde) met grijze lijntjes aangegeven. We konden ons voorstellen dat de grijze lijntjes elastiekjes waren die de oranje lijn verticaal naar de datapunten probeerden te trekken.
Het bepalen van de regressielijn werkt precies zo. We zoeken weer de lijn die de som van de gekwadrateerde residuen zo klein mogelijk maakt. In Figuur 28.13 zijn de residuen weer als grijze lijntjes aangegeven. Je kunt ze weer interpreteren als elastiekjes die de lijn verticaal naar de datapunten trekken. Daardoor schuift en draait de lijn, net zo lang totdat de trekkrachten in evenwicht zijn. Het resultaat is de regressielijn.
BelangrijkDefinitie van de regressielijn
De regressielijn die hoort bij een serie van \(n\) gepaarde gegevens \((x_i, y_i)\) is de rechte lijn die de kwadratensom zo klein mogelijk maakt. De kwadratensom is de som van de gekwadrateerde residuen.
Eigenschappen van de regressielijn
De volgende eigenschappen van regressielijnen zijn belangrijk om te weten.
De regressielijn gaat altijd door het zwaartepunt \((\overline{x}, \overline{y})\) van de puntenwolk. In Figuur 28.13 zijn \(\overline{x}\) en \(\overline{y}\) met stippellijnen aangegeven; de regressielijn gaat precies door het kruispunt van die stippellijnen.
De waarde van \(b\) (dus de richtingscoëfficiënt van de regressielijn) kan worden berekend met deze formule: \[ b = \frac{C_{XY}}{V_X}. \tag{28.5}\] Als je die formule vergelijkt met Vergelijking 28.2, dan zie je dat je dat ook kunt schrijven als \[ b = \left(\frac{s_Y}{s_X}\right)r. \tag{28.6}\] Deze formule laat zien dat de regressiecoëfficiënt \(b\) en de correlatiecoëfficiënt \(r\) met elkaar samenhangen. Als \(b\) positief is, dan is \(r\) dat ook; een stijgende regressielijn betekent dus een positieve correlatie. Maar Vergelijking 28.6 benadrukt ook dat \(b\) en \(r\) niet gelijk zijn:
\(r\) geeft aan hoe strak de datapunten op of langs de lijn liggen. \(r\) heeft geen dimensie (en dus geen eenheid) en ligt altijd tussen -1 en 1.
\(b\) geeft aan hoeveel \(Y\) gemiddeld stijgt als je \(X\) verhoogt. \(b\) heeft als dimensie de dimensie van \(Y\) gedeeld door de dimensie van \(X\), en kan iedere waarde aannemen.
De regressielijn berekenen in R
In de praktijk zul je regressiecoëfficiënten altijd met R uitrekenen.
Stel dat de gegevens zijn opgeslagen in een dataframe gegevens met variabelen (kolommen) x en y. Om \(a\) en \(b\) te berekenen, gebruiken we eerst de functie lm(). Die naam staat voor linear model. Dit is een heel veelzijdige functie die een groot aantal statistische analyses kan uitvoeren. De functie berekent allerlei resultaten, waarvan we er hier maar een paar nodig hebben. We slaan de resultaten daarom eerst op in een variabele, die we hier resultaatLM noemen. Dat werkt als volgt:
resultaatLM <-lm(y ~ x, data = gegevens)
Het eerste argument, y ~ x, vertelt de functie lm() dat we een regressielijn willen voor variabele/kolom y als functie van x. Als je variabelen/kolommen andere namen hebben, vul je hier dus die namen in.
Het tweede argument, data = gegevens, vertelt de functie welke dataframe gebruikt moet worden. Als je dataframe een andere naam heeft, vul je die dus hier in.
Vervolgens kun je met de functie summary() de waarden van \(a\) en \(b\) uit de resultaten opvragen:
Voorbeeld 28.3 (De regressielijn voor flipperlengte versus gewicht van de Adelie-pinguïn.)
In Voorbeeld 28.2 hebben we de correlatie onderzocht tussen de flipper-lengte en het gewicht van Adelie-pinguins. In Figuur 28.12 was voor dezelfde gegevens ook een regressielijn getekend, die gebruikt kan worden om flipper-lengte te voorspellen op basis van het gewicht. We kunnen de coëfficiënten van deze regressielijn zelf met R uitrekenen.
De dataframe had de naam adelie, en de variabelen (kolomnamen) waren flipper_length_mm (met eenheid mm) en body_mass_g (met eenheid g). Dat levert de volgende code op:
resultaatLM <-lm(flipper_length_mm ~ body_mass_g, data = adelie)summary(resultaatLM)$coefficients
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.652448e+02 3.849280576 42.928752 8.681123e-86
body_mass_g 6.676867e-03 0.001032317 6.467848 1.343265e-09
Je kunt de uitvoer als volgt uitlezen:
Informatie over \(a\) lees je af in de regel die begint met (Intercept). (\(a\) is het snijpunt met de \(Y\)-as, wat in het Engels de \(Y\)-intercept wordt genoemd.) De waarde is af te lezen in de kolom Estimate en is in dit geval \(a = 1{,}65\times 10^2\textrm{\,mm}\).
Informatie over \(b\) lees je af in de regel die begint met body_mass_g. Daar vind je de waarde \(b = 6{,}7 \times 10^{-3}\textrm{\,mm/g}\).
De regressielijn is dus \(Y = 1{,}65\times 10^2\textrm{\,mm} + (6{,}7 \times 10^{-3}\textrm{\,mm/g}) X\).
Oefening 28.6 (Het voorspellen van de flipperlengte van Adelie-pinguïns.)
Nu we in Voorbeeld 28.3 de regressielijn voor de flipperlengte als functie van het gewicht hebben bepaald, kunnen we de lijn gebruiken om voorspellingen te doen.
We selecteren een willekeurige Adelie-pinguïn uit de populatie. Deze heeft een gewicht van 4000g. Wat is jouw beste schatting voor de flipperlengte van deze pinguïn?
We vinden een bijzonder kleine pinguïn die maar 500g weegt. Wat is nu jouw voorspelling?
Wat denk je over de betrouwbaarheid van je voorspelling bij onderdeel b?
28.5 Betrouwbaarheidsintervallen voor de regressiecoëfficiënten
De regressielijnen die we hierboven hebben gezien, waren gebaseerd op gegevens afkomstig uit experimenten of een steekproef. Als we hetzelfde onderzoek opnieuw uitvoeren, vinden we waarschijnlijk een andere regressielijn. De regressiecoëfficiënten \(a\) en \(b\) worden dus geplaagd door steekproevenvariabiliteit.
Stel dat de werkelijke regressielijn van de populatie gegeven is door \[ Y = \alpha + \beta X.\] Hier zijn \(\alpha\) en \(\beta\) populatieparameters. Dan zijn de \(a\) en \(b\) die we berekenen op basis van onze gegevens schattingen van die populatieparameters. We zouden de onzekerheid in die schattingen graag willen kwantificeren met een 95%-BHI.
Die betrouwbaarheidsintervallen zijn met R gemakkelijk te berekenen, met de functie confint() (voor confidence intervals). We gebruiken daarbij het resultaat van de functie lm(). Om dat te laten zien, berekenen we de 95%-BHIs voor de regressiecoëfficiënten van Voorbeeld 28.3:
resultaatLM <-lm(flipper_length_mm ~ body_mass_g, data = adelie)confint(resultaatLM)
Deze tabel geeft de ondergrens en de bovengrens van de betrouwbaarheidsintervallen van \(\alpha\) en \(\beta\). De interpretatie spreekt verder voor zich.
Het gebruikte statistische model
Op de exacte berekening van de betrouwbaarheidsintervallen zullen we niet verder ingaan. Wel zijn deze berekeningen gebaseerd op een statistisch model, en het is belangrijk te weten wat de aannames daarvan zijn, zodat je weet wanneer je deze BHI’s kunt vertrouwen, en wanneer niet.
Het zal je niet verbazen dat het statistische model weer een variant is van het Normale Model. De aannames zijn dat voor de populatie geldt:
De verwachtingswaarde (het gemiddelde) van \(Y\) hangt lineair af van de waarde van \(X\):
Voor iedere waarde van \(X\) is \(Y\) normaal verdeeld.
De standaarddeviatie van \(Y\) is voor alle waarden van \(X\) hetzelfde.
Iedere waarneming is onafhankelijk uit zijn verdeling getrokken.
In Figuur 28.14 is het model gevisualiseerd in een 3D-plot. Je kunt de plot weer met je muis bewegen om de vorm van alle kanten te bekijken. De lijnen op het oppervlak van de verdeling laten zien dat voor iedere vaste waarde van \(X\) de waarde van \(Y\) normaal verdeeld is.
Interactieve content beschikbaar op de website:
Visualistatie van het statistisch model dat gebruikt wordt bij de toetsen van de regressiecoëfficiënten. Voor iedere waarde van \(X\) is \(Y\) normaal verdeeld. Het gemiddelde van die verdeling hangt lineair van \(X\) af.
Figuur 28.14: Visualistatie van het statistisch model dat gebruikt wordt bij de toetsen van de regressiecoëfficiënten. Voor iedere waarde van \(X\) is \(Y\) normaal verdeeld. Het gemiddelde van die verdeling hangt lineair van \(X\) af.
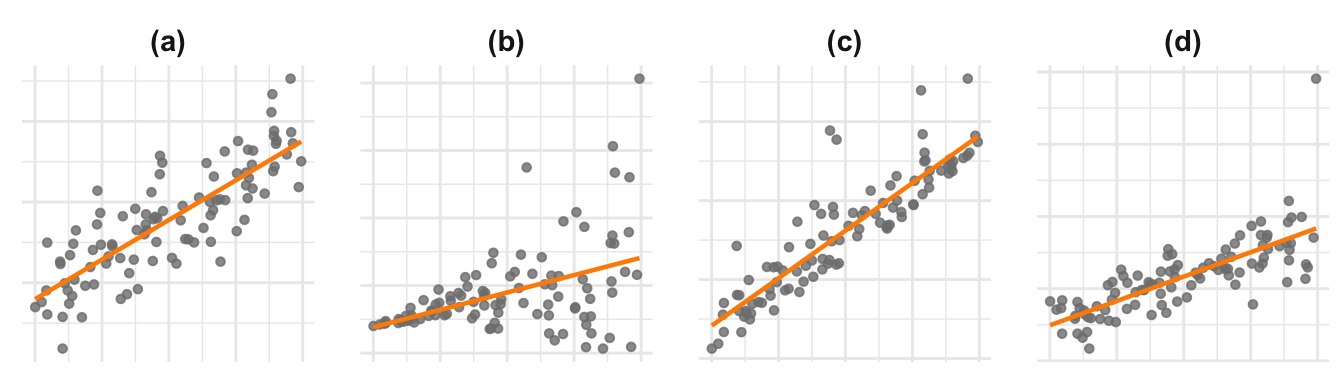
De puntenwolk in Figuur 28.15(a) past goed bij dit model. Figuur 28.15(b–d) zijn voorbeelden waarbij dat niet het geval is.
Code
# Zet zaad voor reproduceerbaarheidset.seed(123)# Definieer parametersn <-100alpha <-2beta <-0.5sigma <-1x_waarden <-runif(n, min =0, max =10)# Genereer de vier datasetsy1 <- alpha + beta * x_waarden +rnorm(n, mean =0, sd = sigma)y2 <- alpha + beta * x_waarden +rnorm(n, mean =0, sd =0.2* x_waarden^1.5)y3 <- alpha + beta * x_waarden +rgamma(n, shape =1.5, scale =0.5)y4 <- alpha + beta * x_waarden +rnorm(n, mean =0, sd = sigma)y4[which.max(x_waarden)] <- y4[which.max(x_waarden)] +8# uitschieter# Combineer in één dataframedata <-data.frame(X =rep(x_waarden, 4),Y =c(y1, y2, y3, y4),groep =factor(rep(c("(a)", "(b)", "(c)", "(d)"), each = n),levels =c("(a)", "(b)", "(c)", "(d)")))# Plotp <-ggplot(data, aes(x = X, y = Y)) +geom_point(color = puntkleur3, alpha =0.8, size =1.2) +geom_smooth(method ="lm", se =FALSE,color = lijnkleur0, size =0.8) +facet_wrap(~ groep, nrow =1, scales ="free_y") +theme_minimal(base_size =11) +theme(axis.title =element_blank(),axis.text =element_blank(),axis.ticks =element_blank(),strip.text =element_text(size =11, face ="bold"),# panel.grid = element_blank(),panel.spacing =unit(1, "lines") )print(p)
Figuur 28.15: Het statistische model voor de toetsen en de BHI’s van de regressiecoëfficiënten. Paneel (a) laat een puntenwolk zien die consistent is met het model: het gemiddelde van \(Y\) loopt lineair op, en de standaarddeviatie van \(Y\) is voor iedere \(X\) ongeveer gelijk. De data in (b), (c), en (d) zijn niet consistent met het model. In (b) neemt de standaarddeviatie van \(Y\) toe met \(X\). In (c) is de verdeling van \(Y\) rechts-scheef en dus niet normaal verdeeld. In (d) is de extreme uitschieter het probleem.
28.6 Toetsen van de regressiecoëfficiënten
Stel dat we op basis van onze gegevens een positieve waarde van \(b\) vinden. Dan zijn we geneigd om te concluderen dat er een positieve relatie bestaat tussen de twee variabelen. Maar voordat we dat kunnen concluderen, zullen we eerst moeten onderzoeken of het redelijkerwijs ook mogelijk is dat de regressiecoëfficiënt van de populatie \(\beta\) eigenlijk gelijk is aan 0, en de positieve \(b\) enkel het gevolg is van steekproevenvariabiliteit. Daarvoor kunnen we hypothesetoetsen uitvoeren.
Het is weer gemakkelijk om die toetsen binnen R uit te voeren. Sterker nog, we hebben er al twee gedaan! Kijk maar eens terug naar de coëfficiënten die we hadden berekend voor de regressie tussen flipper_length_mm en body_mass_g. Dit was de uitvoer van R:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1.652448e+02 3.849280576 42.928752 8.681123e-86
body_mass_g 6.676867e-03 0.001032317 6.467848 1.343265e-09
In de kolom Estimate waren de waarden van \(a\) en \(b\) gegeven. De andere kolommen geven resultaten van statistische toetsen.
In de regel (Intercept) wordt de nulhypothese getoetst dat \(\alpha = 0\). Het is een \(t\)-toets. Onder Std. Error staat de standaardfout van \(a\); onder t value de \(t\)-waarde van de toets; en onder Pr(>|t|) de bijbehorende \(P\)-waarde. Dat de \(P\)-waarde zo klein is (\(P = 8{,}7 \times 10^{-86}\)) geeft aan dat we erg zeker zijn dat \(\alpha \neq 0\).
In de regel body_mass_b wordt de nulhypothese getoetst dat \(\beta = 0\). Dat is dus de hypothese dat er in de populatie géén relatie is tussen \(X\) en \(Y\). De \(P\)-waarde van deze toets is ook erg klein (\(P = 1{,}3 \times 10^{-9}\)). Er is dus sterk bewijs voor een positieve relatie tussen \(X\) en \(Y\).
We zullen de onderliggende berekeningen hier niet verder uitspellen. Wel is het belangrijk dat voor deze resultaten hetzelfde statistische model gebruikt wordt als voor de berekening van de 95%-BHI’s (Figuur 28.14).
28.7 Interpolatie en extrapolatie
De \(X\)-waarden van de gegevens die we gebruiken om een regressielijn mee te berekenen, zijn altijd beperkt tot een bepaald domein. Bijvoorbeeld, de gewichten van de Adelie-pinguïns liepen van 2850g tot 4775g. We kiezen de waarden van \(a\) en \(b\) zo dat de regressielijn de gegevens binnen dit domein goed beschrijft, maar kunnen niet weten of dezelfde lijn buiten dat domein ook nog van toepassing is. Bij het voorspellen van een \(Y\)-waarde op basis van een \(X\)-waarde kunnen we daarom onderscheid maken tussen twee situaties:
Interpoleren: Als de \(X\)-waarde waarvoor we een voorspelling willen doen binnen het domein valt van de gegevens waarop de regressielijn gebaseerd was, dan heet dat interpoleren.
Extrapoleren: Als de \(X\)-waarde waarvoor we een voorspelling willen doen buiten dat domein valt, dan noemen we dat extrapoleren.
Extrapoleren is gevaarlijk: het is heel goed mogelijk dat het lineaire verband dat is waargenomen binnen het domein van de data zich niet voortzet buiten dat domein. In dat geval kunnen de voorspellingen enorm de plank misslaan.
Tot nu toe hebben we ons alleen beziggehouden met lineaire verbanden. In werkelijkheid komt het ook vaak voor dat variabelen op een niet-lineaire manier met elkaar samenhangen.
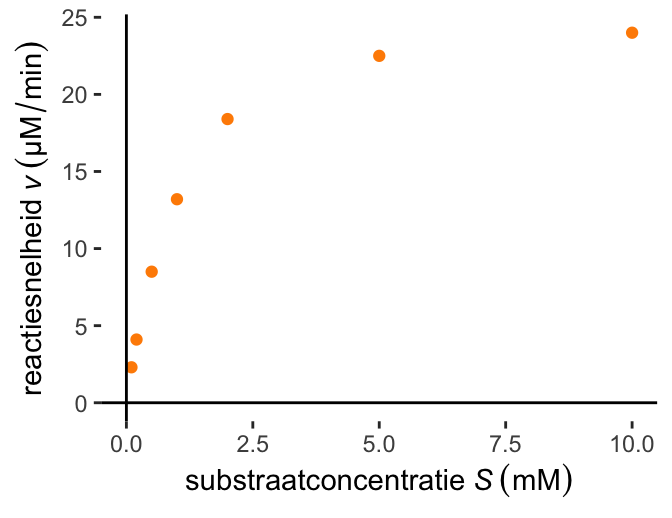
Bijvoorbeeld, de snelheid van een chemische reactie die door een enzym wordt gekatalyseerd hangt op een niet-lineaire manier af van de hoeveelheid substraat. Je kunt dat in het lab onderzoeken door voor verschillende substraatconcentraties de reactisnelheid te meten. Figuur 28.16 (a) laat zien hoe experimentele resultaten eruit zouden kunnen zien. Als je de substraatconcentratie steeds verder verhoogt, wordt uiteindelijk de reactiesnelheid niet meer groter omdat het enzym al op zijn maximale snelheid werkt. De relatie tussen substraatconcentratie en reactiesnelheid is dus niet lineair.
Code
data <-data.frame(substraatconcentratie =c(0.1, 0.2, 0.5, 1.0, 2.0, 5.0, 10.0),reactiesnelheid =c(2.3, 4.1, 8.5, 13.2, 18.4, 22.5, 24.0))ggplot( data, aes(x = substraatconcentratie, y = reactiesnelheid)) +geom_point(color = puntkleur1) +labs(x =expression(substraatconcentratie ~italic(S) ~ (mM)),y =expression(reactiesnelheid ~italic(v) ~ (μM/min)) ) +geom_hline(yintercept =0, color ="black") +geom_vline(xintercept =0, color ="black") +theme_classic() +theme(axis.line =element_blank(), # remove default axes )# Definieer parameterskm <-3vmax <-10kleur <- lijnkleur0# Substraatconcentraties tot ruim boven Kms_waarden <-seq(0, 6*km, length.out =300)# Michaelis-Menten vergelijkingv_waarden <- (vmax * s_waarden) / (km + s_waarden)# Bereken punt op de kromme bij S = Kmv_bij_km <- vmax/2# Zet in data.framegegevens <-data.frame(s = s_waarden,v = v_waarden)# Teken de grafiekggplot(gegevens, aes(x = s, y = v)) +geom_line(color = kleur,size =1 ) +# Horizontale lijn op Vmaxgeom_hline(yintercept = vmax,linetype ="dashed",color ="gray40" ) +# Horizontale lijn op Vmax/2geom_hline(yintercept = v_bij_km,linetype ="dashed",color ="gray40" ) +# Verticale lijn van x-as tot de kromme bij S = Kmgeom_segment(aes(x = km, xend = km,y =0, yend = v_bij_km ),linetype ="dashed",color ="gray40" ) +# Labels bij Km, Vmax en Vmax/2annotate("text",x = km +0.5,y =0.5,label =expression(italic(K)[M]),hjust =0,size =4 ) +annotate("text",x =1,y = vmax -0.5,label =expression(italic(v)[max]),hjust =0,size =4 ) +annotate("text",x =8,y = v_bij_km +0.6,label =expression(italic(v)[max] /2),hjust =0,size =4 ) +labs(x =expression(substraatconcentratie ~italic(S)),y =expression(reactiesnelheid ~italic(v)) ) +geom_hline(yintercept =0, color ="black") +geom_vline(xintercept =0, color ="black") +theme_classic() +theme(axis.line =element_blank(), # remove default axesaxis.text.x =element_blank(),axis.text.y =element_blank(),axis.ticks.x =element_blank(),axis.ticks.y =element_blank() )
(a) Gemeten reactiesnelheden \(v\) bij verschillende substraatconcentraties \(S\).
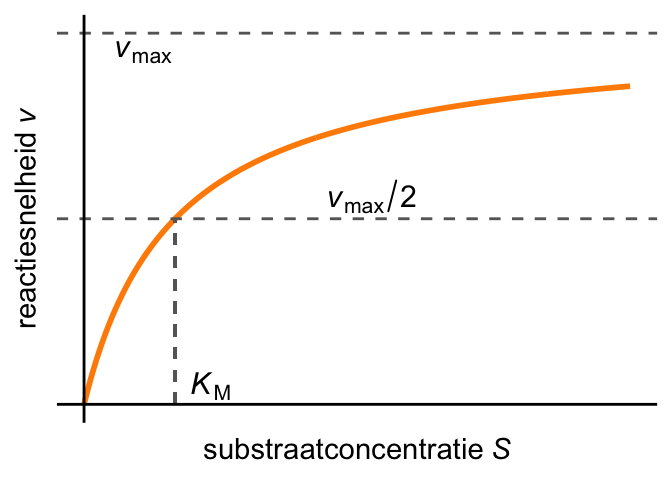
(b) Michaelis-Menten-model voor enzymkinetiek.
Figuur 28.16: Voorbeeld van een niet-lineair verband dat met een model beschreven kan worden.
De kinetiek van enzymatische reacties kan vaak worden beschreven met de volgende formule: \[
v = \frac{v_\textrm{max}\cdot S}{K_\textrm{M} + S}.
\tag{28.7}\] Dit wordt de Michaelis-Menten-curve genoemd; Figuur 28.16 (b) illustreert de formule. Hier is \(v\) de snelheid van de reactie, en \(S\) de substraatconcentratie. De parameter \(v_\textrm{max}\) bepaalt de maximumsnelheid van de reactie, de parameter \(K_\textrm{M}\) bij welke concentratie de reactiesnelheid \(v_\textrm{max}/2\) bereikt.
We kunnen voor de gegevens uit Figuur 28.16 (a) de waarden van \(v_\textrm{max}\) en \(K_\textrm{M}\) bepalen die het beste bij de gegevens passen. Dit noemen we het “fitten” van het model aan de gegevens. Dit is de manier waarop de eigenschappen van enzymen in de praktijk ook worden bepaald.
Eerder hebben we de parameters \(a\) en \(b\) van de regressielijn “gefit” door te zoeken naar de waarden waarbij de kwadratensom minimaal was. Voor niet-lineaire modellen wordt dezelfde truc gebruikt. Om \(v_\textrm{max}\) en \(K_\textrm{M}\) te bepalen, zoeken we ook naar de waarden waarbij de kwadratensom minimaal is.
We kunnen in deze cursus helaas niet meer tijd besteden aan het fitten van niet-lineaire modellen. Maar in Oefening 28.10 helpen we je om met R het Michaelis-Menten-model te fitten aan de gegevens van Figuur 28.16 (a).
28.9 Samenvatting
Correlatie
We zeggen dat de twee variabelen een lineaire relatie hebben of gecorreleerd zijn als de datapunten zich op of in de buurt van een rechte lijn bevinden die stijgt of daalt.
Covariantie:
Maat van lineaire samenhang tussen \(X\) en \(Y\), in de dimensies en eenheden van \(X\) en \(Y\).
Maat van lineaire samenhang tussen \(X\) en \(Y\), zonder dimensie.
Definitie: \[
r = \frac{C_{XY}}
{s_X s_Y}.
\]
Eigenschappen:
Ligt altijd in het interval [-1, 1]
Het teken geeft de richting van het verband (positief of negatief)
De absolute waarde geeft de sterkte van het verband.
Perfect verband: \(r = 1\) of \(r = -1\).
Geen verband: \(r = 0\).
Waarschuwingen: De correlatiecoëfficiënt is
geen richtingscoëfficiënt.
alleen geschikt voor lineaire verbanden.
gevoelig voor uitbijters.
afhankelijk van het bereik van de \(X\)-waarden.
BelangrijkDe toets voor correlatie in 6 stappen
We zijn geïnteresseerd in twee continue variabelen \(X\) en \(Y\) en willen de hypothese toetsen dat het de correlatiecoëfficiënt tussen die twee variabelen in de populatie, \(\rho\), gelijk is aan \(0\). We nemen daarom een steekproef van \(n\) eenheden en berekenen de correlatiecoëfficiënt \(r\) van die steekproef.
Dan zijn dit de stappen van de toets:
Kies het statistische model: het Bivariate Normale Model.
Verdeling van de toetsingsgrootheid onder \(H_\textrm{0}\):
De \(t\)-verdeling met \(\mathrm{df}= n - 2\).
Bereken de toetsingsgrootheid op basis van de steekproef.
Achtereenvolgens: \(r\), \(\mathrm{SE}_{r}\), en dan \(t\).
Bereken de \(P\)-waarde:
Gebruik R:
P <-2*pt(-abs(t), df = n -2)
Trek je conclusies.
Lineaire regressie
Rechte lijn door de “puntenwolk”; beschrijft de lineaire relatie tussen \(X\) en \(Y\). Kan gebruikt worden om \(Y\) te voorspellen uit de waarde van \(X\).
Definitie:
De rechte lijn \(Y = a + b X\) waarbij \(a\) en \(b\) zo gekozen zijn dat de kwadratensom zo klein mogelijk is.
Eigenschappen:
Gaat altijd door het zwaartepunt \((\overline{x}, \overline{y})\).
De formule voor \(b\) is:
\[ b= \frac{C_{XY}}{V_X}.\]
Dat kan ook geschreven worden als
\[ b = \left(\frac{s_Y}{s_X}\right)r.\]
Waarschuwingen:
Ook \(b\) is gevoelig voor uitbijters.
Voorspellingen buiten het domein van de gegevens (extrapolaties) zijn onbetrouwbaar.
BHI’s en toetsen:
Voor het berekenen van BHI’s voor de regressiecoëfficiënten en hypothesetoetsen wordt gebruik gemaakt van het volgende statistisch model:
De verwachtingswaarde (het gemiddelde) van \(Y\) hangt in de populatie lineair af van de waarde van \(X\):
Voor iedere waarde van \(X\) is \(Y\) normaal verdeeld.
De standaarddeviatie van \(Y\) is voor alle waarden van \(X\) hetzelfde.
Iedere waarneming is onafhankelijk uit zijn verdeling getrokken.
De details van de berekeningen hebben we niet behandeld; die laten we voor nu aan R over.
Het fitten van modellen
Het vinden van parameters van een model aan de hand van gegevens, wordt “fitten” genoemd.
Bij lineaire regressie is het berekenen van \(a\) en \(b\) dus het “fitten” van een rechte lijn aan de gegevens.
De parameters van niet-lineaire modellen kunnen op dezelfde manier bepaald worden, door de parameters te zoeken waarbij de kwadratensom zo klein mogelijk is.
Functie die de kans(dichtheid) geeft voor een combinatie van twee variabelen, bijvoorbeeld \((X, Y)\).
bivariate normale verdeling
bivariate normal distribution
Bivariate kansverdeling waarbij beide variabelen normaal verdeeld zijn en (mogelijk) gecorreleerd zijn.
covariantie
covariance
Maat van de lineaire samenhang tussen twee variabelen. Heeft de dimensies van beide variabelen.
dimensieloos
dimensionless
Als een grootheid geen dimensie heeft en dus geen eenheid, is die dimensieloos. Voorbeelden zijn de correlatiecoëfficiënt, verhoudingen, en kansen.
extrapolatie
extrapolation
Een model dat is geformuleerd en gefit voor een bepaald domein van \(X\)-waarden, toepassen buiten dat domein.
een model fitten
to fit a model
De parameters van een model kiezen zodat het model een dataset zo goed mogelijk beschrijft.
lineaire relatie
linear relation
Een relatie tussen twee variabelen die beschreven kan worden met een rechte lijn.
interpolatie
interpolation
Een model dat is geformuleerd en gefit voor een bepaald domein van \(X\)-waarden, toepassen voor een \(X\)-waarde binnen dat domein.
(Pearsons) correlatiecoëfficiënt
(Pearson’s) correlation coefficient
Dimensieloze maat voor de lineaire samenhang tussen twee variabelen, met waarden tussen -1 en 1. Geeft aan hoe “strak” de datapunten op de rechte lijn liggen.
regressiecoëfficiënt
regression coefficient
Parameters van een regressiemodel, zoals de richtingscoëfficiënt \(b\) en het snijpunt met de \(y\)-as \(a\) van de regressielijn.
regressielijn
regression line
De rechte lijn door de gegevens waarvan de parameters gekozen zijn zodanig dat de kwadratensom zo klein mogelijk is.
28.11 Opgaven
Oefening 28.7 (Het kalibreren van de nephelometer.)
De beroemde bioloog en Nobelprijswinnaar Jacques Monod beschreef in zijn proefschrift uit 1942 in veel detail de groei van bacterie-culturen. Om dat te kunnen doen, wilde hij tijdens de groei van een cultuur de totale biomassa van de cellen kunnen meten zonder de cultuur te verstoren.
Daarom maakte hij gebruik van een nephelometer. Een nephelometer meet de optische dichtheid (OD) van een suspensie door er een lichtstraal op te schijnen en de verstrooiing van het licht te meten. Het idee was dat de OD toeneemt naarmate de biomassa groeit. Uit de OD zou je de biomassa dus moeten kunnen berekenen.
Om te bevestingen dat OD inderdaad een goede proxy is voor drooggewicht en de omrekenfactor te schatten, mat Monod acht keer zowel het drooggewicht (in mg per liter groeimedium) en de OD voor Bacillus subtilis-culturen. Hij vond de volgende waarden:
Experiment
OD
Drooggewicht (mg/L)
1
31.0
24
2
34.6
26
3
40.0
32
4
35.2
26
5
57.5
42
6
56.5
44
7
57.0
44
8
56.8
42
Maak in R twee vectoren met de meetgegevens: OD en drooggewicht. Combineer ze tot een dataframe.
Plot drooggewicht tegen OD. Ziet het ernaar uit dat OD gebruikt kan worden om drooggewicht te voorspellen?
Bereken de correlatiecoëfficiënt tussen beide variabelen. Wat zegt die waarde?
Bepaal een lineaire formule om OD te voorspellen uit drooggewicht. Gebruik daarvoor eerst de functie lm() en daarna de functie summary().
In een nieuw experiment meet Monod een OD van 45,5. Wat is jouw beste schatting van het drooggewicht?
In een volgend experiment meet Monod een OD van 100,0. Wat zegt de regressielijn over het drooggewicht?
Oefening 28.8 (Anscombes kwartet)
In 1973 publiceerde statisticus Francis Anscombe een interessante dataset.1 Deze dataset is beschikbaar via de library datasets; als je die nog niet geïnstalleerd hebt, moet je dat eenmalig nog even doen met het commando:
install.packages("datasets")
Start een nieuw script. Schrijf al je code in het script, niet rechtstreeks in de Console.
Laad de dataset in:
library("datasets")
De dataframe heet anscombe. Bekijk de structuur van de dataframe:
str(anscombe)
Verifieer dat er 8 kolommen zijn en 11 rijen.
De datafame bevat eigenlijk vier datasets: x1 hoort bij y1, x2 bij y2, etc.
We focussen even op variabelen x1 en y1.
Bereken het gemiddelde van beide variabelen.
Bereken de standaarddeviatie van beide variabelen.
Bereken de correlatiecoëfficiënt voor x1 en y1.
Bereken de regressiecoëfficiënten voor y1 als functie van x1.
Herhaal de berekeningen van onderdeel b, maar nu voor x2 en y2.
(Als je de code voor b netjes in je script hebt geschreven, kun je met copy-paste heel snel klaar zijn.)
Doe hetzelfde voor x3 en y3…
… en tot slot voor x4 en y4.
Wat valt je op als je de resultaten van b tot e vergelijkt? Wat zou je op basis van al deze kengetallen denken over deze vier datasets?
Gebruik de functie plot() om een spreidingsdiagram te maken van y1 versus x1. Herhaal dit voor de andere drie datasets. Vertellen de figuren hetzelfde verhaal?
Wat is de moraal van dit verhaal?
Oefening 28.9 (Pinguïnparadox)
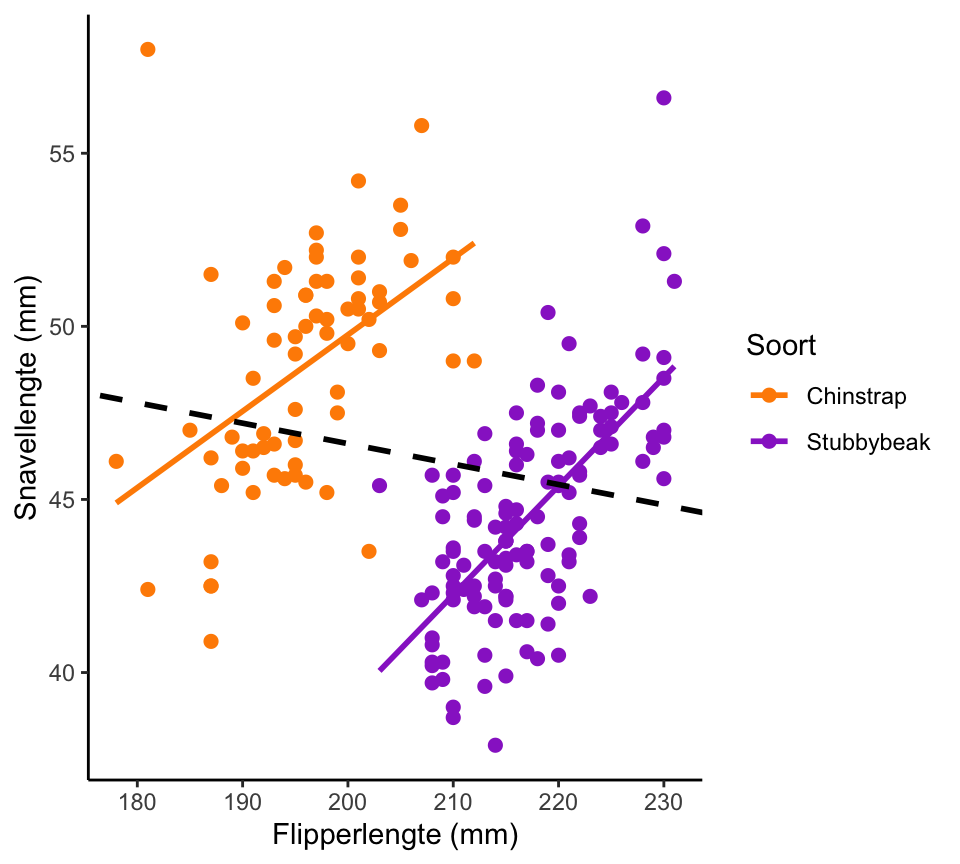
Tijdens avontuurlijk veldwerk hebben onderzoekers in de Palmer-archipel de snavellengte en flipperlengte van pinguïns gemeten. De verwachting was dat die twee variabelen positief met elkaar zouden correleren, want een pinguïn met lange flippers zal typisch in alle opzichten wat groter zijn dan een pinguïn met korte flippers, en dus ook typisch een langere snavel hebben.
Groot was dan ook het ongeloof, toen bleek dat de correlatie negatief was: \(r = -0{,}19\)!
Om uit te vinden wat er aan de hand was, doken de onderzoekers dieper de gegevens in. Het bleek dat er pinguïns van twee soorten in de dataset waren opgenomen: Chinstrap en Stubbybeak2.
De plot hieronder laat de gehele dataset zien. De datapunten voor de twee soorten hebben verschillende kleuren gekregen. Ook zijn aparte regressielijnen toegevoegd voor beide soorten (gekleurd) en voor de gehele dataset (zwarte onderbroken lijn).
Figuur 28.17: De pinguïnparadox: correleert snavellengte positief met flipperlengte?
Is de correlatiecoëfficiënt voor de Chinstrap-pinguïns positief of negatief?
Is de correlatiecoëfficiënt voor de Stubbybeak-pinguïns positief of negatief?
Kun jij begrijpen hoe het kan dat de correlatie voor de gehele dataset toch negatief is?
OpmerkingSimpsons paradox
De pinguïnparadox heet in het algemeen Simpsons paradox. De paradox is: als twee variabelen positief geassocieerd zijn in twee groepen, dan kan het zijn dat ze negatief geassocieerd zijn als de twee groepen worden samengevoegd. Het is dus belangrijk om goed na te denken voordat je data van meerdere groepen aggregeert in één dataset.
Oefening 28.10 (Eigenschappen van een enzymatische reactie, en een niet-lineair model.)
In Paragraaf 28.8 hebben we uitgelegd dat de reactiesnelheid (\(v\)) van een enzymatische reactie op een niet-lineaire manier afhangt van de substraatconcentratie \(S\). In Figuur 28.16 (a) lieten we meetwaarden zien voor zo’n reactie.
Een veelgebruikt model voor enzymkinetiek is het Michaelis–Menten-model. Binnen dat model is de reactiesnelheid gegeven door: \[
v = \frac{v_\textrm{max} \cdot S}{K_\textrm{M} + S},
\] met de volgende parameters:
\(v_\textrm{max}\): De maximale reactiesnelheid.
\(K_\textrm{M}\): De substraatconcentratie waarbij de reactiesnelheid de helft van \(v_{\max}\) bereikt.
We vertellen de functie nls() om te zoeken naar waarden van v_max en K_M waarbij de functie michaelis_menten de variabele reactiesnelheid uit de dataset meetgegevens zo dicht mogelijk benadert.
Door Figuur 28.16 (a) te vergelijken met Figuur 28.16 (b) kunnen we grofweg inschatten dat v_max in de buurt van 25 zal liggen, en K_M in de buurt van 1. We vertellen R daarom om te starten met v_max = 25 en K_M = 1 en vervolgens in die buurt te zoeken naar de parameterwaarden die de kwadratensom minimaliseren. Het eindresultaat wordt opgeslagen in de variabele fit.
Zorg dat je snapt wat er in de code gebeurt; neem deze regels code dan over en voer ze uit.
Gebruik de functie summary() om de gevonden parameterwaarden te bekijken:
# Laat de gefitte parameters ziensummary(fit)$coefficients
Zijn die ongeveer zoals je verwacht had?
Om te controleren hoe goed de Michaelis-Menten-curve de data beschrijft, maken we een plot met zowel de gegevens als de gefitte curve:
v_max <-# de gevonden parameterwaarden invullenK_M <-S_waarden <-seq(0, 10, 0.5)# de gefitte MM-curve:reactiesnelheid_model <-michaelis_menten(S_waarden, v_max, K_M)# plot de lijn volgens het modelplot( S_waarden, reactiesnelheid_model, type ="l", col ="black", lwd =2,xlab ="substraat",ylab ="reactiesnelheid")# voeg de datapunten eraan toepoints( meetgegevens$substraatconcentratie, meetgegevens$reactiesnelheid,pch =21, bg = opvulkleur, cex =1.5 )
Ziet de fit er overtuigend uit?
Anscombe, F. J. (1973). “Graphs in Statistical Analysis”. American Statistician. 27 (1): 17–21.↩︎
Ok, om eerlijk te zijn: de pinguïnsoort Stubbybeak bestaat niet. We hebben die soort voor deze opgave uit onze duim gezogen.
De gegevens voor Stubbybeak zijn eigenlijk meetgegevens voor Gentoo-pinguïns uit de dataset “palmerpenguins”, behalve dat van iedere snavellengte 3mm is afgetrokken. De gegevens van Chinstrap zijn wél echt.↩︎

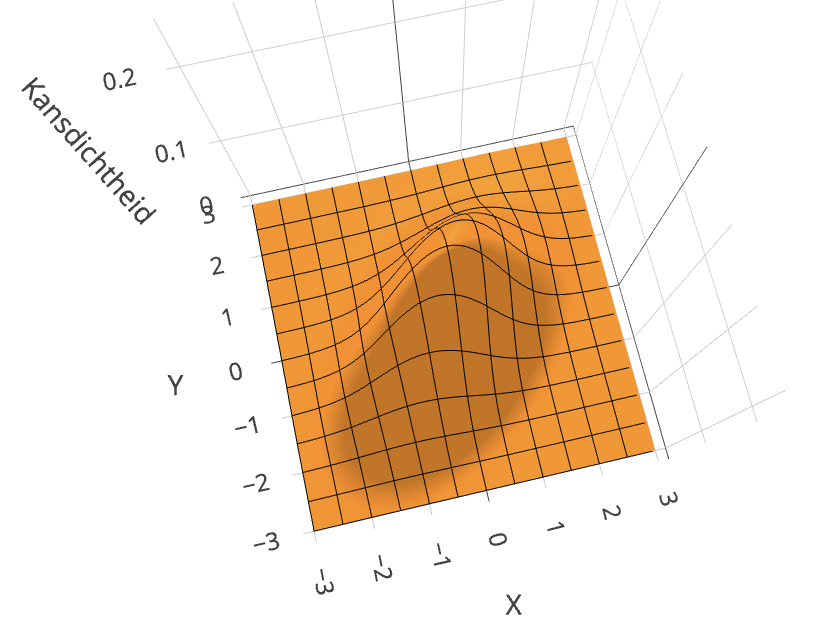 Visualisatie van de bivariate normale verdeling met
Visualisatie van de bivariate normale verdeling met 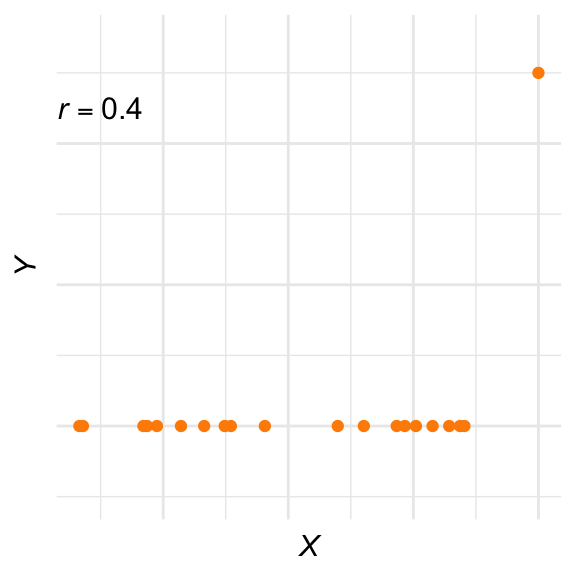
 Visualistatie van het statistisch model dat gebruikt wordt bij de toetsen van de regressiecoëfficiënten. Voor iedere waarde van
Visualistatie van het statistisch model dat gebruikt wordt bij de toetsen van de regressiecoëfficiënten. Voor iedere waarde van