In het vorige hoofdstuk hebben we de basisbegrippen en -regels besproken voor het rekenen met kansen. In dit hoofdstuk introduceren we kansverdelingen, een begrip dat in de rest van het boek een grote rol speelt.
23.1 Leerdoelen
Na het bestuderen van dit hoofdstuk kun je:
uitleggen wat kansverdelingen en cumulatieve kansverdelingen zijn;
uitleggen dat, bij numerieke kansvariabelen, kansen kunnen worden gerelateerd aan oppervlakten onder de grafiek van de kansverdeling;
uitleggen dat bij continue verdelingen de kansverdeling de kansdichtheid weergeeft;
verschillende centrum- en spreidingsmaten van kansverdelingen interpreteren;
uitleggen wat de normale verdeling, de standaardnormale verdeling, en de \(t\)-verdeling zijn, en hoe die zich tot elkaar verhouden;
normaalverdeelde kansvariabelen transformeren naar standaardnormaalverdeelde variabelen.
kritieke waarden interpreteren en berekenen voor normale verdelingen en \(t\)-verdelingen;
23.2 Wat zijn kansverdelingen?
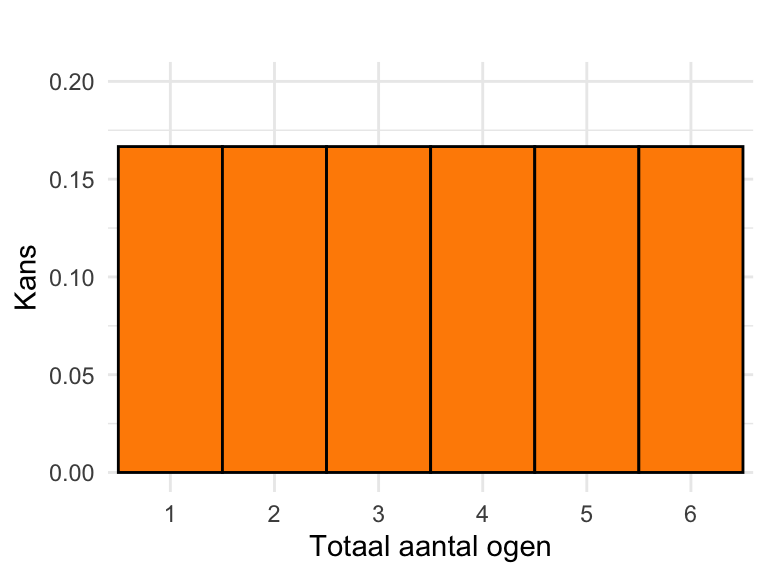
We hebben het in het vorige hoofdstuk vaak gehad over het werpen van een eerlijke dobbelsteen. We kunnen de kansen weergeven in een grafiek:
Code
# Parameters definiërenmin_ogen <-1# Minimum aantal ogen op een dobbelsteenmax_ogen <-6# Maximum aantal ogen op een dobbelsteenkans <-1/ max_ogen # Gelijke kans voor elke uitkomst# Genereer de uitkomsten en bijbehorende kansenuitkomsten <-seq(min_ogen, max_ogen)kansen <-rep(kans, length(uitkomsten))maakKansverdeling(uitkomsten, kansen, "Totaal aantal ogen", y_lim =c(0, 0.2))
Figuur 23.1: Kansverdeling: de kansen bij het gooien van één dobbelsteen.
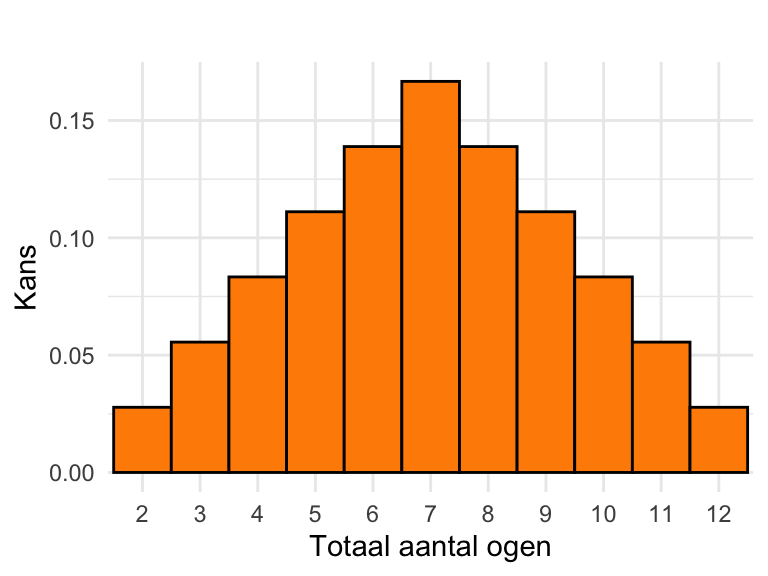
In dit geval zijn alle kansen gelijk. Maar stel je nu voor dat we niet één maar twee dobbelstenen gooien, een blauwe en een rode. We zijn geïnteresseerd in de som van het aantal ogen. De kansruimte is nu de verzameling van de gehele getallen van 2 tot 12. De verschillende uitkomsten zijn nu niet meer even waarschijnlijk. Er is namelijk maar één manier om de uitkomst 2 te krijgen (\(1 + 1\)), en zes manieren om 7 te gooien (\(1 + 6\), \(2 + 5\), \(3 + 4\), \(4 + 3\), \(5 + 2\), \(6 + 1\)). Je zult met twee dobbelstenen dus veel vaker 7 gooien dan 2.
Als we uitgaan van een kansmodel waarin beide dobbelstenen eerlijk en onafhankelijk zijn, dan kunnen we de kansen uitrekenen en in een grafiek laten zien:
Code
# Parameters definiërenmin_som <-2# Minimum som bij twee dobbelstenenmax_som <-2*max_ogen # Maximum som bij twee dobbelstenen# Genereer uitkomsten en bijbehorende kansenuitkomsten <-seq(min_som, max_som) # Mogelijke uitkomstenkansen <-pmin(uitkomsten -1, 13- uitkomsten) / max_ogen^2# Kansen berekenenmaakKansverdeling(uitkomsten, kansen, "Totaal aantal ogen")
Figuur 23.2: Kansverdeling voor het aantal ogen van twee dobbelstenen.
De manier waarop kansen over alle mogelijke uitkomsten verdeeld zijn, wordt de kansverdeling (probability distribution) genoemd. Zowel Figuur 23.1 als Figuur 23.2 geven dus een kansverdeling weer.
TipRelatie tussen kansverdeling en histogram
Figuur 23.2 lijkt op een histogram. Dat is niet voor niets. In Paragraaf 22.3 hebben we de kans op een uitkomst gedefinieerd als de relatieve frequentie van die uitkomst in een héél lange reeks identieke kansexperimenten. De kansverdeling kun je dus interpreteren als het histogram dat je zou krijgen als je hetzelfde kansexperiment héél vaak zou herhalen.
Oefening 23.1 (De kansverdeling van het aantal keer “kop”)
Stel dat we twee munten gooien. We gaan uit van een model waarbij de munten eerlijk zijn en hun uitkomsten onafhankelijk.
Teken de kansverdeling van het aantal keer dat je “kop” gooit.
Oefening 23.2 (Genotypes)
We kruisen twee heterozygote zoogdieren met genotype aA. Om de kansen op de verschillende genotypes aa, aA en AA in de nakomelingen in te schatten, gebruiken we een simpel kansmodel:
Iedere ouder geeft met gelijke kans a of A aan de geslachtscellen mee.
Het allel heeft geen invloed op de kans op conceptie.
Het genotype heeft geen invloed op het succes van de zwangerschap.
Wat is de kans dat een nakomeling genotype aa heeft?
Wat is de kans dat een nakomeling genotype aA heeft?
Wat is de kans dat een nakomeling genotype AA heeft?
Wat is de relatie van deze opgave met Oefening 23.1?
23.3 De vorm van een verdeling kwalitatief beschrijven
In Paragraaf 20.4.2 heb je verschillende termen geleerd waarmee je een verdeling kunt beschrijven: symmetrisch en scheef, klokvormig, uniform, unimodaal, bimodaal, en multimodaal. Die woorden kunnen net zo goed gebruikt worden voor kansverdelingen. De kansverdeling van Figuur 23.1 is uniform; die van Figuur 23.2 symmetrisch en unimodaal.
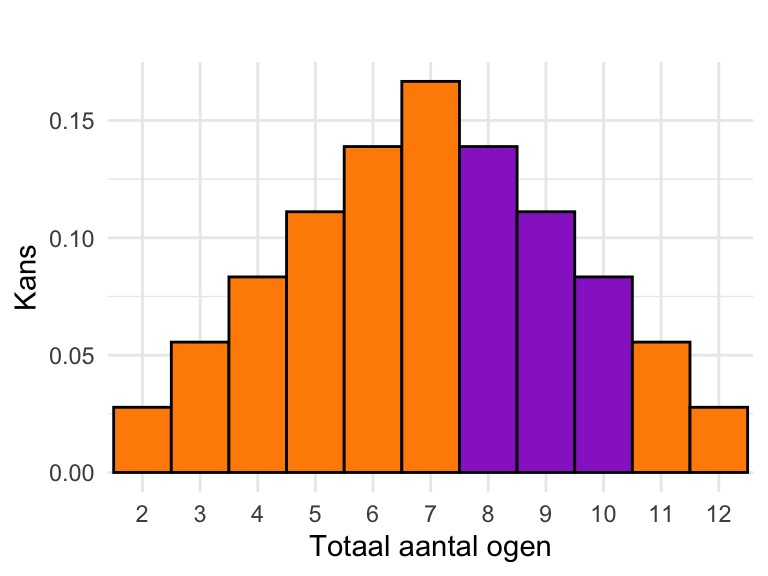
23.4 Kansen als oppervlakten onder de grafiek van de kansverdeling
Kijk nog eens terug naar de kansverdeling voor het totaal aantal ogen bij het gooien met twee dobbelstenen (Figuur 23.2). Stel dat we de kans willen weten op een aantal ogen \(X\) groter dan 7 maar kleiner dan 11, oftewel, \(7 < X < 11\). Deze gebeurtenis kunnen we ook anders uitdrukken, namelijk als \[ X = 8 \textrm{ of } X = 9 \textrm{ of } X = 10.\] Omdat de verschillende uitkomsten \(X = 8\), \(9\) en \(10\) elkaar uitsluiten kunnen we de optelregel Vergelijking 22.8 gebruiken om de kans te berekenen: \[ \textrm{Pr}\!\left[7 < X < 11\right] = \textrm{Pr}\!\left[X = 8\right] + \textrm{Pr}\!\left[X = 9\right] + \textrm{Pr}\!\left[X = 10\right]. \]
In de grafiek van de kansverdeling (Figuur 23.2) was de kans op een uitkomst weergegeven als de oppervlakte van de bijbehorende staaf. De kans \(\textrm{Pr}\!\left[7 < X < 11\right]\) komt dus overeen met de totale oppervlakte van de staven voor de uitkomsten 8, 9 en 10, hieronder in paars weergegeven:
Code
kleur <-rep(opvulkleur, 11)kleur[7:9] <- opvulkleur1ggplot(data.frame(x =factor(uitkomsten), y = kansen), aes(x = x, y = y)) +geom_bar(stat ="identity", fill = kleur, alpha =0.7, color ="black", width =1) +labs(x ="Totaal aantal ogen", y ="Kans") +theme_minimal()
Figuur 23.3: Kansverdeling van het totaal aantal ogen van twee dobbelstenen.
In het algemeen geldt: de kans dat de uitkomst binnen een bepaald interval valt, is gelijk aan de totale oppervlakte van de staven binnen dit interval. In dit voorbeeld is de kansvariabele discreet, maar we zullen straks zien dat ook voor continue variabelen geldt dat de kans op een uitkomst in een bepaald interval gegeven is door de “oppervlakte onder de grafiek” binnen dat interval.
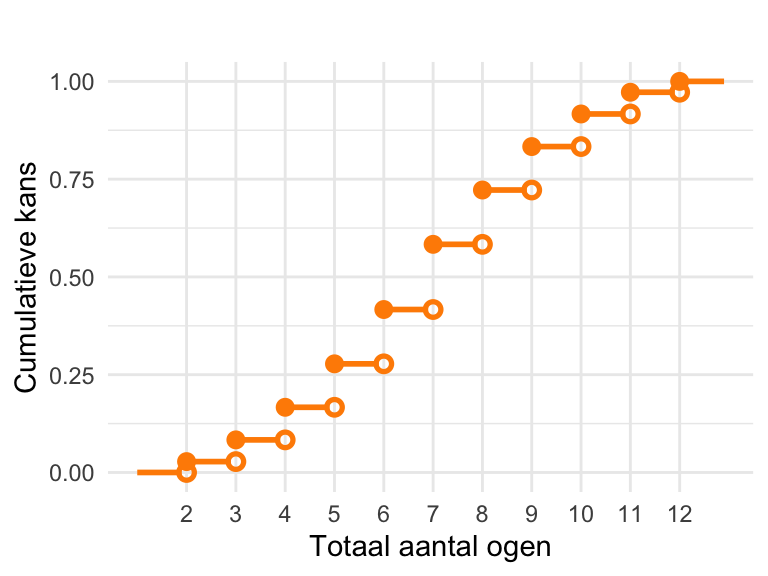
23.5 De cumulatieve kansverdeling
De cumulatieve kansverdeling\(F_X(x)\) van kansvariabele \(X\) is de functie die aangeeft wat de kans is dat de uitkomst kleiner of gelijk is aan de waarde \(x\): \[ F_X(x) = \textrm{Pr}\!\left[X\le x\right]. \tag{23.1}\]Figuur 23.4 is een voorbeeld. Dat is de cumulatieve kansverdeling die hoort bij de kansverdeling in Figuur 23.2, voor het totaal aantal ogen van twee dobbelstenen. De cumulatieve verdeling maakt in dit geval sprongen omdat de uitkomst alleen een geheel aantal ogen kan zijn. (De variabele is discreet.) Bijvoorbeeld, \(F_X(2{,}99) = \textrm{Pr}\!\left[X = 2\right]\), maar \(F_X(3) = \textrm{Pr}\!\left[X = 2\right] + \textrm{Pr}\!\left[X = 3\right]\).
Code
# Voeg extra punten toe om de cumulatieve kansen buiten het bereik van 2-12 te tonenkansen_dobbelsteen_cumulatief <-data.frame(uitkomsten =c(1, uitkomsten, 13), # Voeg 1 en 13 toe als grenzenkansen =c(0, cumsum(kansen), 1) # Voeg 0 en 1 toe aan de kansen)# Genereer de datapunten voor de open cirkelsopen_cirkels <-data.frame(uitkomsten = uitkomsten,kansen =c(0, cumsum(kansen)[-length(kansen)]))# Maak een data frame voor de horizontale lijnen (stappen van de cumulatieve kans)lijnen_data <-data.frame(x_start = kansen_dobbelsteen_cumulatief$uitkomsten[-nrow(kansen_dobbelsteen_cumulatief)],x_end = kansen_dobbelsteen_cumulatief$uitkomsten[-1] - .1,y = kansen_dobbelsteen_cumulatief$kansen[-nrow(kansen_dobbelsteen_cumulatief)])# Maak de plotggplot() +# Voeg de horizontale lijnen toegeom_segment(data = lijnen_data,aes(x = x_start, xend = x_end, y = y, yend = y),color = lijnkleur0, # Kleur van de lijnenlinewidth =1# Dikte van de lijnen ) +# Voeg gesloten cirkels (linkerkanten) toe, behalve bij (1, 0) en (13, 1)geom_point(data = kansen_dobbelsteen_cumulatief[-c(1, nrow(kansen_dobbelsteen_cumulatief)), ],aes(x = uitkomsten, y = kansen),shape =16, # Gesloten cirkelsize =3,color = puntkleur1 ) +# Voeg open cirkels (rechterkanten) toegeom_point(data = open_cirkels,aes(x = uitkomsten, y = kansen),shape =1, # Open cirkelsize =1.8,stroke =1.4,color = puntkleur1 ) +scale_x_continuous(breaks =2:12, # Ticks alleen bij gehele getallen van 2 tot 12minor_breaks =NULL# Verwijder alle minor ticks ) +labs(title ="",x ="Totaal aantal ogen", # Titel voor de x-asy ="Cumulatieve kans"# Titel voor de y-as ) +theme_minimal() # Minimalistisch thema
Figuur 23.4: Cumulatieve verdeling van de som van de ogen van twee dobbelstenen. Omdat de variabele discreet is, maakt de verdeling sprongen. Als je de functie afleest op een geheel getal, zoals \(X = 3\), moet je de waarde bij het ingekleurde datapunt aflezen, niet die van het open datapunt.
Hierboven lieten we zien dat je de kans \(\textrm{Pr}\!\left[7<X<11\right]\) kunt aflezen als de totale oppervlakte van de staven voor \(X=8\), \(X =9\), en \(X = 10\) in de kansverdeling. Je kunt dezelfde kans ook zo berekenen: \[\textrm{Pr}\!\left[7<X<11\right] = F_X(10) - F_X(7).\] De kans op \(7 < X < 11\) is namelijk de kans dat \(X\) kleiner of gelijk is aan 10 min de kans dat \(X\) kleiner of gelijk is aan 7.
Oefening 23.3 (De cumulatieve verdeling van het aantal keer “kop”)
Je gooit net als in Oefening 23.1 met twee munten en gaat weer uit van een model waarbij beide munten eerlijk zijn en de uitkomsten van beide munten onafhankelijk.
Teken de cumulatieve verdeling van het aantal keer “kop”. Gebruik je resultaten uit Oefening 23.1, en neem Figuur 23.4 als voorbeeld.
23.6 Kansverdelingen voor continue variabelen
Tot nu toe hebben we alleen kansverdelingen gezien van discrete kansvariabelen. Als een kansvariabele continu is, moeten we op een andere manier nadenken over de kans op een uitkomst.
Een continue kansvariabele heeft oneindig veel mogelijke uitkomsten. (Om precies te zijn, overaftelbaar oneindig!1) Tussen elke twee getallen die je kiest bestaan namelijk altijd weer oneindig veel andere getallen. De kans op iedere specifieke uitkomst is daarom 0. Bijvoorbeeld, de kans dat een willekeurig gekozen persoon een lichaamslengte heeft van 180,00… cm, exact tot in oneindig veel decimalen, is 0.
Bij continue variabelen zijn we daarom niet geïnteresseerd in de kans op een specifieke uitkomst, maar in de kans dat de uitkomst binnen een bepaald interval valt. De kans dat de lichaamslengte van een willekeurig persoon tussen 170 en 182cm ligt is wél groter dan 0.
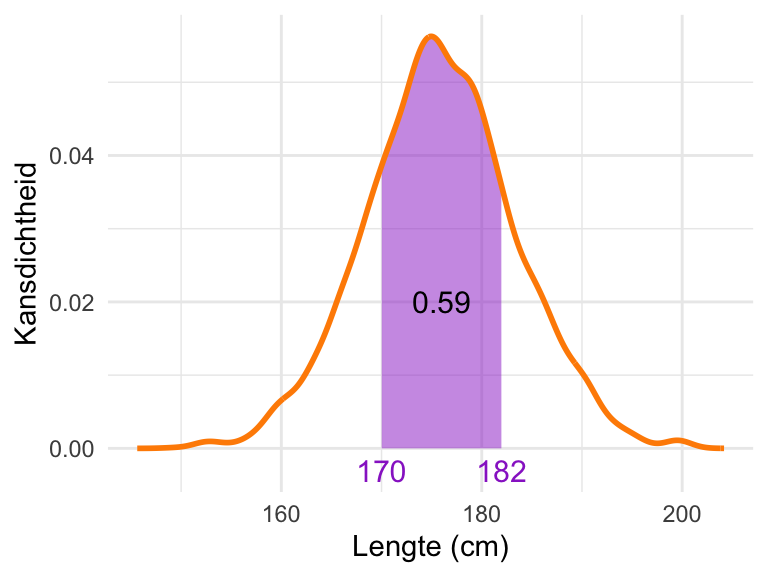
Bekijk Figuur 23.5 hieronder eens. Deze figuur toont (bij benadering) de kansverdeling van de lichaamslengte van volwassen Amerikaanse mannen. De verdeling laat zien dat een lengte in de buurt van 175cm waarschijnlijker is dan een lengte rond 160cm. Toch mogen we de waarde op de \(y\)-as niet interpreteren als de kans op een bepaalde \(x\)-waarde, want we hebben net geconcludeerd dat de kans op iedere specifieke waarde gelijk is aan 0. Wat is dan wél de juiste interpretatie?
Code
linkergrens <-170rechtergrens <-182# Selecteer alleen de volwassen mannen waarvoor een lengte bekend isdata_mannen <- NHANES %>%filter(Age >=18& Gender =="male"&!is.na(Height)) # Selecteer de mannen binnen het intervaldata_mannen_in_interval <- data_mannen %>%filter( Height > linkergrens & Height < rechtergrens )# Kans in het intervalkans <-nrow(data_mannen_in_interval)/nrow(data_mannen)# Selecteer de mannen >= rechtergrensdata_mannen_lang <- data_mannen %>%filter( Height >= rechtergrens )# Kans langkans_lang <-nrow(data_mannen_lang)/nrow(data_mannen)# Selecteer de mannen <= linkergrensdata_mannen_kort <- data_mannen %>%filter( Height <= linkergrens )# Kans in het intervalkans_kort <-nrow(data_mannen_kort)/nrow(data_mannen)# Bereken de dichtheid voor de gehele datasetdichtheid_data <-density(data_mannen$Height, na.rm =TRUE)dichtheid_df <-data.frame(Lengte = dichtheid_data$x, Kansdichtheid = dichtheid_data$y )# Selecteer alleen de dichtheidswaarden binnen het intervaldichtheid_interval <- dichtheid_df %>%filter(Lengte > linkergrens & Lengte < rechtergrens)# Plot de figuurggplot(data = dichtheid_df, aes(x = Lengte, y = Kansdichtheid)) +geom_area(data = dichtheid_interval, aes(x = Lengte, y = Kansdichtheid),fill = opvulkleur1,alpha =0.5) +geom_line(color = lijnkleur0, linewidth =1) +annotate("text", x = linkergrens, y =-0.003, label =paste0(linkergrens),size =4,color = accentkleur2 ) +annotate("text",x = rechtergrens,y =-0.003,label =paste0(rechtergrens),size =4,color = accentkleur2 ) +annotate("text", x = (linkergrens + rechtergrens)/2, y =0.02, label =paste0(round(kans,2)), size =4, color ="black" ) +labs(x ="Lengte (cm)", y ="Kansdichtheid" ) +theme_minimal()
Figuur 23.5: Kansenverdeling van lichaamslengtes van volwassen Amerikaanse mannen. De kans op een lichaamslengte tussen 170cm en 182cm wordt gegeven door het paarse oppervlak onder de kansverdeling. (De kansverdeling is geschat m.b.v. de dataset NHANES.)
Om dit te begrijpen, denken we terug aan Figuur 23.3. Daar zagen we al dat de kans op een waarde binnen een bepaald interval overeenkomt met de oppervlakte onder de grafiek van de kansverdeling. Dit principe geldt ook voor continue variabelen. De kans dat een willekeurig gekozen man een lengte heeft tussen 170cm en 182cm, wordt gegeven door de oppervlakte onder de grafiek tussen die grenzen. Dit gebied is in de grafiek ingekleurd met paars en heeft een oppervlakte van 0,59. Dat is dus de kans dat een Amerikaanse man een lengte heeft tussen 170cm en 182cm.
De totale oppervlakte onder de curve, van \(-\infty\) tot \(\infty\), is bij iedere kansverdeling van een numerieke variabele gelijk aan 1, want de kans dat een uitkomst ergens op de \(x\)-as ligt is 1.
Bij kansverdelingen van continue variabelen is de waarde op de \(y\)-as dus niet de kans op een specifieke waarde. In plaats daarvan spreken we over de kansdichtheid (probability density).
In Paragraaf 23.2 zagen we dat je over een kansverdeling kunt denken als over een histogram van een enorm (oneindig) aantal waarnemingen. Dat werkt ook bij continue variabelen. Je kunt je voorstellen dat het aantal waarnemingen zo groot is dat we de klassen van het histogram extreem smal hebben kunnen maken — zo smal dat de rechthoekige staven niet meer zichtbaar zijn en het histogram een gladde curve wordt.
Oefening 23.4 (Kansen schatten bij continue kansverdelingen)
Wat is de kans dat een Amerikaanse man kleiner is dan 170cm of groter dan 182cm?
Schat op het oog de kans dat een Amerikaanse man kleiner is dan 170cm.
23.7 Maten voor ligging en spreiding van kansverdelingen
In Hoofdstuk 20 heb je gezien dat de verdeling van een numerieke variabele in een dataset kan worden samengevat door maten te geven voor de ligging en spreiding van die verdeling.
Op dezelfde manier kunnen we ook de kansverdeling van een kansvariabele beschrijven door maten van ligging en de spreiding te geven. De maten die we hieronder bespreken zijn dus volledig analoog aan de maten uit Hoofdstuk 20.
Maten voor de ligging van een kansverdeling
We beginnen met de centrummaten.
De modus van een kansverdeling is die uitkomst die de grootste kans of kansdichtheid heeft. Als de kansverdeling één piek heeft, dan is de \(x\)-waarde die bij die piek hoort de modus.
De mediaan van een kansvariabele \(X\) is de waarde zodanig dat de kans op een uitkomst kleiner of gelijk aan die waarde precies gelijk is aan \(\frac{1}{2}\). Dat is dus de waarde waar de cumulatieve kansverdeling gelijk is aan \(\frac{1}{2}\).
Het gemiddelde van een kansverdeling van een kansvariabele \(X\) wordt ook wel de verwachtingswaarde (expected value) genoemd. Een nette notatie is \(\mathbb{E}\!\left[X\right]\); die bijzondere \(\mathbb{E}\) staat voor Expectation. Vaak wordt ook het Griekse symbool \(\mu\) (spreek uit: “mu”) gebruikt, of \(\mu_X\) als we willen benadrukken dat het gaat om de verwachtingswaarde van de variabele \(X\).
Als de variabele discreet is dan kan de verwachtingswaarde berekend worden als \[ \mu_X = \mathbb{E}\!\left[X\right] = \sum_x \textrm{Pr}\!\left[X = x\right]\, x. \tag{23.2}\] De sommatie gaat over alle mogelijke uitkomsten \(x\). Vergelijking 23.2 wil dus zeggen: we nemen het gewogen gemiddelde van alle mogelijke uitkomsten \(x\), waarbij uitkomsten met een grotere kans een zwaarder gewicht krijgen.
Oefening 23.6 (De definitie van de verwachtingswaarde)
In Oefening 20.10 heb je een formule bestudeerd (Vergelijking 20.7) waarmee je het gemiddelde kunt berekenen van een dataset die beschreven is met een frequentietabel.
Bestudeer die opgave nog een keer.
Vergelijk Vergelijking 20.7 met Vergelijking 23.2 en leg uit waarom ze zo op elkaar lijken. (Hint: In Paragraaf 22.3 hebben we de kans op een uitkomst gedefinieerd als de relatieve frequentie van die uitkomst in een zéér lange (oneindige) reeks herhalingen van het kansexperiment.)
Oefening 23.7 (Verwachtingswaarde)
In een experiment krijgen dieren 9 keer de gelegenheid om een taak uit te voeren. De experimentatoren tellen hoe vaak dat lukt.
Vooraf is een kansmodel bedacht voor het aantal keer dat een dier de taak succesvol weet uit te voeren. Dat model levert de volgende kansen op:
Tabel 23.1
Aantal
Kans
0
0.009
1
0.054
2
0.151
3
0.244
4
0.255
5
0.177
6
0.082
7
0.024
8
0.004
9
0.000
Bereken de verwachtingswaarde voor het aantal keer succes. Het is handig om R als rekenmachine te gebruiken.
Als een variabele continu is, dan kunnen we niet sommeren over alle mogelijke uitkomsten omdat er oneindig veel mogelijke uitkomsten zijn en iedere individuele uitkomst kans 0 heeft. In plaats daarvan verandert de sommatie in een integraal: \[ \mu_X = \mathbb{E}\!\left[X\right] = \int_{-\infty}^\infty \textrm{Pr}\!\left[X = x\right]\, x\, \mathrm{d}x. \tag{23.3}\] Gelukkig hoef je dit soort integralen in deze cursus niet zelf uit te voeren.
Maten van spreiding
Dan nu de maten van spreiding.
De meest gebruikte maten van spreiding van een kansverdeling zijn de variantie en de standaarddeviatie / standaardafwijking.
In Paragraaf 20.8.3 hebben we de definitie gezien van de variantie \(V_X\) van een reeks numerieke waarnemingen (Vergelijking 20.4). Kijk nog eens naar die definitie: \[
V_X = \frac{\sum_{i=1}^n \left(x_i - \overline{x}\right)^2}{n-1}.
\] Dat is dus het gemiddelde van de gekwadrateerde afwijkingen van het gemiddelde. (In Paragraaf 21.8 heb je gezien waarom we in de noemer \(n-1\) gebruiken.)
De variantie van een kansvariabele \(X\) wordt vaak genoteerd als \(\mathrm{Var}\!\left(X\right)\). De definitie daarvan is weer de gemiddelde gekwadrateerde afwijking van het gemiddelde, maar nu gaat het om het gemiddelde van de kansverdeling, dus de verwachtingswaarde: \[
\mathrm{Var}\!\left(X\right) = \mathbb{E}\!\left[ \left( X - \mu_X \right)^2\right].
\tag{23.4}\] Van iedere mogelijke uitkomst wordt dus het gemiddelde \(\mu_X\) afgetrokken, en die afwijking wordt gekwadrateerd. Vervolgens nemen we het gemiddelde van die gekwadrateerde afwijkingen, waarbij uitkomsten met een grotere kans zwaarder worden meegewogen. Als \(X\) een discrete kansvariabele is, dan komt dat neer op \[
\mathrm{Var}\!\left(X\right) = \sum_x \textrm{Pr}\!\left[X = x\right] \left( x - \mu_X \right)^2.
\tag{23.5}\] Bij een continue variabele wordt de sommatie weer een integraal.
De standaarddeviatie van \(X\) is de wortel van de variantie van \(X\). Deze wordt vaak genoteerd als de Griekse letter \(\sigma\) of als \(\sigma_{X}\): \[
\sigma_{X} = \sqrt{\mathrm{Var}\!\left(X\right)}.
\tag{23.6}\]
Omgekeerd is de variantie van \(X\) dus het kwadraat van de standaarddeviatie: \[
\mathrm{Var}\!\left(X\right) = \sigma_{X}^2.
\tag{23.7}\] Daarom wordt de variantie van een kansvariabele \(X\) ook vaak genoteerd als \(\sigma^2\) of \(\sigma_{X}^2\) in plaats van \(\mathrm{Var}\!\left(X\right)\).
Oefening 23.8 (Variantie en standaarddeviatie van een kansvariabele)
In deze opgave gaan we verder met de kansverdeling uit Oefening 23.7. Je gaat voor deze kansverdeling de variantie en standaarddeviatie uitrekenen aan de hand van de definities Vergelijking 23.4 en Vergelijking 23.6.
De verwachtingswaarde \(\mathbb{E}\!\left[X\right]\) of \(\mu_X\) van deze kansverdeling heb je in Oefening 23.7 al berekend.
Bereken voor iedere mogelijke uitkomst de afwijking van de verwachtingswaarde. Dat gaat handig in R. Als de vector van mogelijke uitkomsten uitkomsten heet en de verwachtingswaarde E:
afwijkingen <- uitkomsten - E
Bereken het kwadraat van alle afwijkingen.
Vermenigvuldig nu de gekwadrateerde afwijkingen met hun kans. De kans van iedere uitkomst is gegeven in Oefening 23.7.
De variantie is nu de som van de getallen die je in onderdeel c hebt berekend.
Bereken de standaarddeviatie.
23.8 De normale verdeling
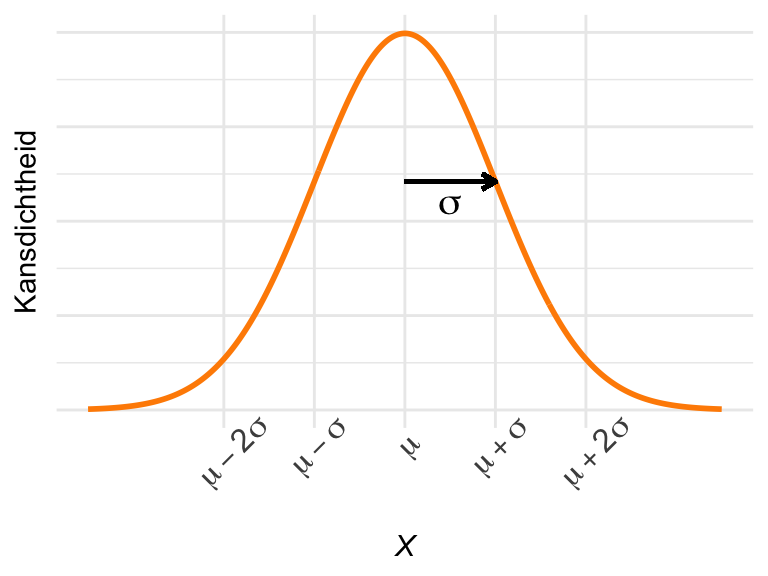
Bepaalde kansverdelingen komen in theorie en praktijk steeds weer terug en hebben daarom een naam gekregen. De beroemdste is de normale verdeling (normal distribution), ook wel de normaalverdeling, Gaussische verdeling of Gausscurve genoemd, naar de Wiskundige Carl Friedrich Gauss (1777–1855).
Eigenlijk gaat het niet om één specifieke kansverdeling maar om een “familie” van kansverdelingen. Leden van deze familie lijken precies op elkaar, behalve dat ze verschillen in gemiddelde \(\mu\) en standaarddeviatie \(\sigma\). We noemen \(\mu\) en \(\sigma\) de parameters van de normale verdeling.
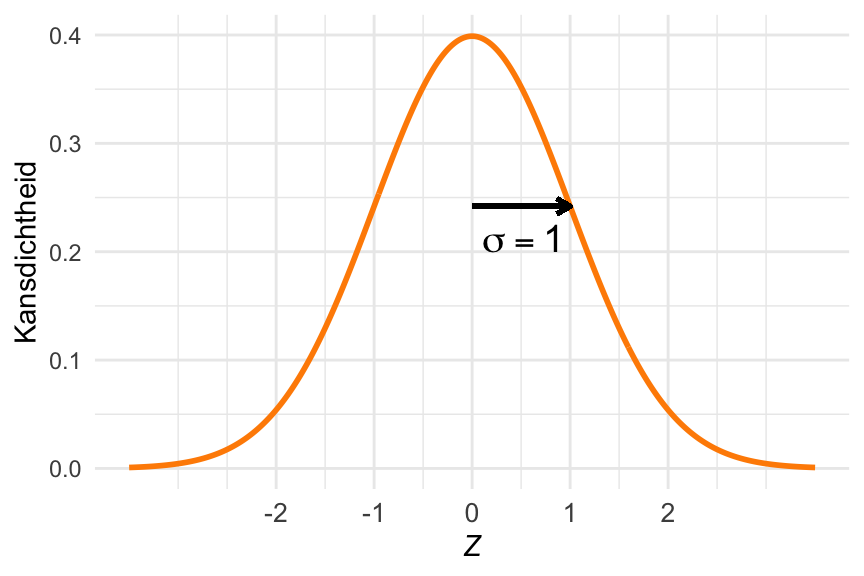
De verdelingen zien er als volgt uit (Figuur 23.7):
Code
# Definieer de standaardnormale verdeling (nodig voor oppervlak())x <-seq(-3.5, 3.5, length.out =350)data <-data.frame(x = x, y =dnorm(x))normaalGeneriek <-normaalCurve(0, 1, expression(italic(X)))normaalGeneriek +pijlSigma(0, 1)
Figuur 23.7: De normale verdeling.
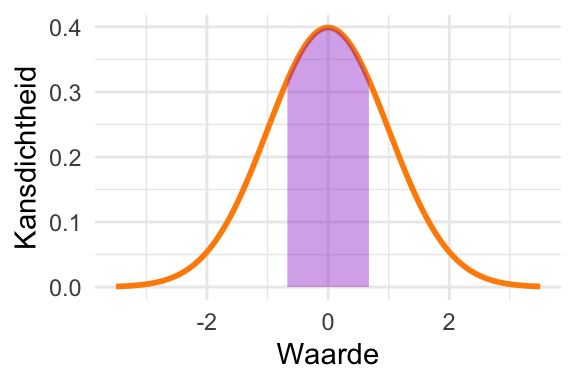
Je ziet dat de verdeling een klokvorm heeft en volledig symmetrisch is. Daardoor is \(\mu\) het gemiddelde, de mediaan, én de modus. De meeste kans ligt binnen twee standaarddeviaties van \(\mu\).
De precieze formule voor de normale verdeling zul je in deze cursus niet nodig hebben, maar het is toch handig deze een keer gezien te hebben: \[ \textrm{Pr}\!\left[X = x\right] = \frac{1}{\sqrt{2\pi\sigma^2}} e^{-\frac{(x - \mu)^2}{2\sigma^2}}.\] De normale verdeling heeft dus een precieze wiskundige definitie. Niet iedere verdeling die een klokvorm heeft is ook een normale verdeling (maar iedere normale verdeling heeft wel dezelfde klokvorm).
Vuistregels voor de normale verdeling
Het is heel nuttig om de volgende twee eigenschappen uit je hoofd te leren; je hebt ze vaak nodig.
Als \(X\) normaal verdeeld is, dan geldt:
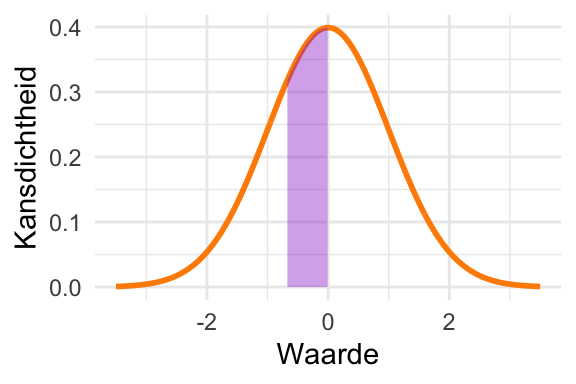
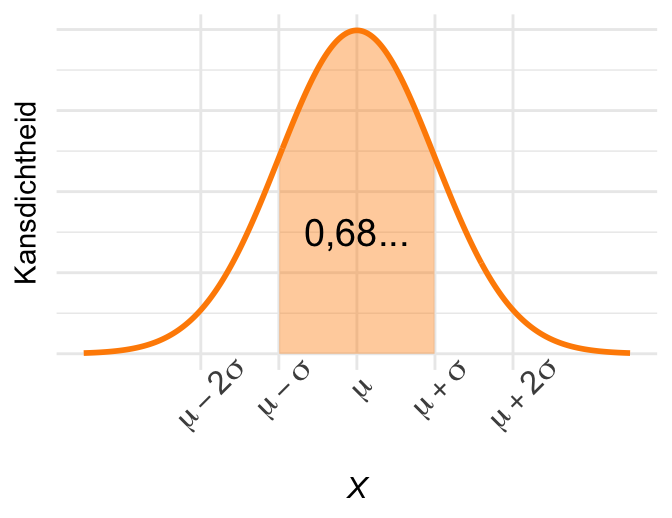
De kans dat de uitkomst binnen één standaarddeviatie van het gemiddelde valt is iets meer dan \(\frac{2}{3}\). Om precies te zijn: \[\textrm{Pr}\!\left[\mu - \sigma < X < \mu + \sigma\right] = 0{,}683\ldots. \tag{23.8}\]
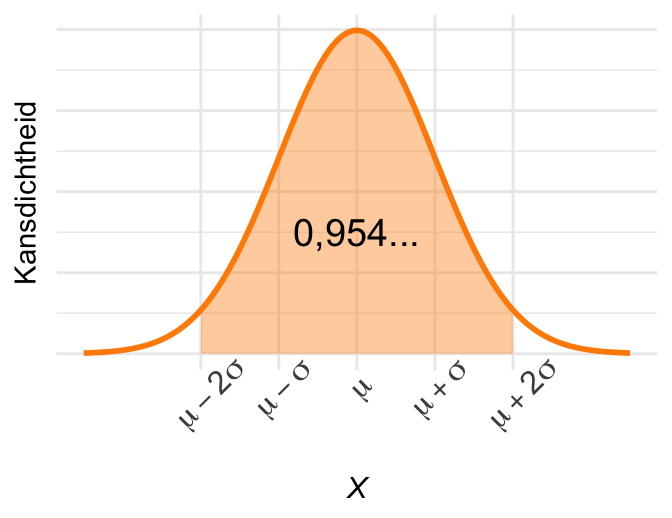
De kans dat de uitkomst binnen twee standaarddeviaties van het gemiddelde valt is iets groter dan 0,95. Om precies te zijn:
\[\textrm{Pr}\!\left[\mu - 2\sigma < X < \mu + 2\sigma\right] = 0{,}954\ldots. \tag{23.9}\]Figuur 23.8 laat beide eigenschappen zien.
(a) Iets meer dan 2/3 van de kans valt binnen één standaarddeviatie van het gemiddelde.
(b) Iets meer dan 95% van de kans valt binnen 2 standaarddeviaties van het gemiddelde.
Figuur 23.8: Vuistregels voor de normale verdeling.
Oefening 23.9 (Het toepassen van de vuistregels voor de normale verdeling)
Als je nadenkt over kansverdelingen helpt het om de situatie te schetsen. Maak daar een gewoonte van!
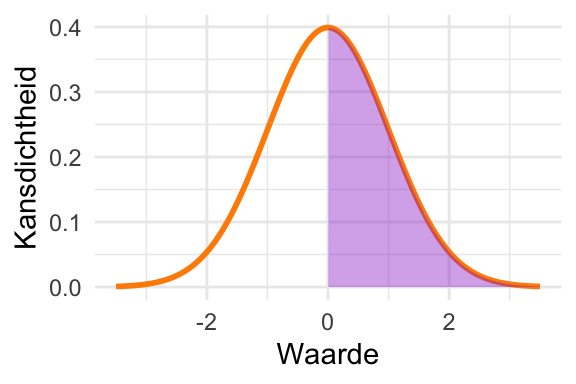
Schets Figuur 23.7 na. Arceer het oppervlak onder de curve dat overeenkomt \(\textrm{Pr}\!\left[X < \mu\right]\). Wat is die kans?
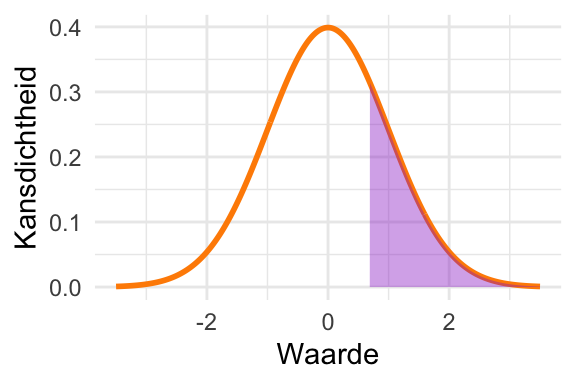
Maak nog zo’n schets, maar nu voor \(\textrm{Pr}\!\left[X > \mu + \sigma\right]\). Bepaal die kans met behulp van de vuistregel uit Paragraaf 23.8.1.
Wat is de kans \(\textrm{Pr}\!\left[X < \mu - 2 \sigma\right]\)? Maak weer gebruik van een schets en de vuistregels.
Idem, maar nu voor \(\textrm{Pr}\!\left[X < \mu - 2 \sigma \text{ of } X > \mu + 2 \sigma\right]\).
Oefening 23.10 (Hoofd-omtrek van pasgeboren babies)
De verdeling van de hoofdomtrek van pasgeboren babies die voldragen zijn (d.w.z., niet prematuur geboren), is klokvormig. Een redelijk model is een normale verdeling met gemiddelde \(\mu = 34{,5}\)cm en standaarddeviatie \(\sigma = 1{,}75\)cm.
Hoeveel standaarddeviaties boven het gemiddelde is een hoofdomtrek van 38 cm?
Wat is de kans dat een baby een hoofdomtrek heeft van meer dan 38 cm?
(Tip: Maak weer een schets!)
Waarom de normale verdeling? De centrale limietstelling.
De normale verdeling neemt in de waarschijnlijkheidsleer en statistiek een heel bijzondere plek in. Dat heeft verschillende redenen.
Om te beginnen hebben veel variabelen binnen en buiten de biologie een klokvorm. Voor zulke variabelen kan de normale verdeling een goed model zijn. Voorbeelden zijn de lichaamslengte en het IQ van volwassen mannen of vrouwen die onder vergelijkbare omstandigheden zijn opgegroeid; de gemiddelde CITO-score op verschillende basisscholen in Nederland; maar ook de afstand die een molecuul in een oplossing door diffusie aflegt in een vaste tijd.
Dat we de normale verdeling zowel in theorie als in de praktijk vaak terugzien, heeft een wiskundige reden. Je kunt namelijk aantonen dat een kansvariabele die beïnvloed wordt door een groot aantal andere kansvariabelen vaak ongeveer normaal verdeeld zal zijn. Dat geldt bijvoorbeeld als een variabele de optelsom is van een groot aantal kansvariabelen. De wiskundige stelling die dat bewijst wordt de Centrale Limietstelling (Central Limit Theorem) genoemd. In Paragraaf 24.10.4 komen we daar nog even op terug.
In de praktijk worden veel variabelen beïnvloed door een groot aantal factoren. Lichaamslengte is bijvoorbeeld het resultaat van een groot aantal genen en allerlei omgevingsfactoren tijdens de groei, zoals voeding, slaap, en hygiëne. Omdat al die variabelen per individu verschillen valt te verwachten dat het resultaat ongeveer normaal verdeeld is.
23.9 De standaardnormale verdeling
De standaardnormale verdeling (standard normal distribution) (Figuur 23.9) is een speciaal geval van de normale verdeling: het is de normale verdeling met \(\mu = 0\) en \(\sigma = 1\). Deze verdeling is hieronder (Figuur 23.9) weergegeven.
Eerder hebben we kansvariabelen vaak \(X\) genoemd. Voor een standaardnormaal verdeelde variabele wordt vaak de letter \(Z\) gebruikt. Dit is niet meer dan een gewoonte, maar toch is het handig: kom je in een statistische formule een kansvariabele \(Z\) tegen, dan is dat een hint dat die variabele waarschijnlijk standaardnormaal verdeeld is.
Transformeren naar de standaardnormale verdeling
Alle normale verdelingen hebben dezelfde klokvorm, maar ze verschillen in hun gemiddelde en hun standaarddeviatie. Als twee normale verdelingen verschillen in hun gemiddelde, dan zijn ze ten opzichte van elkaar verschoven. Verschillen ze in hun standaarddeviatie, dan zijn de klokvormen ten opzichte van elkaar horizontaal uitgerekt of samengedrukt. Ondanks die verschillen is de totale oppervlakte onder de grafiek altijd gelijk aan 1, want de kans op een uitkomst tussen \(-\infty\) en \(\infty\) is altijd 1. Horizontaal uitrekken gaat dus altijd samen met verticaal samendrukken.
Bekijk Figuur 23.10 eens. Deze laat twee normale verdelingen zien.
De bovenste figuur toont de verdeling van een variabele \(X\) met gemiddelde \(\mu_X = 170\) en standaarddeviatie \(\sigma_{X} = 6\). Het zou een model kunnen zijn voor de lichaamslengte van Nederlandse volwassen vrouwen, in centimeters.
Het onderste figuur toont de verdeling van variabele \(Z\), die standaardnormaal verdeeld is (dus \(\mu_Z=0\) en \(\sigma_{Z} = 1\)).
Hoewel de parameters van beide verdelingen verschillen, hebben ze exact dezelfde vorm. (De \(x\)- en \(y\)-assen van de figuren zijn wel ten opzichte van elkaar uitgerekt en verschoven.)
Code
# Basisparameters instellenmu_x <-170# Gemiddelde voor Xsigma_x <-6# Standaarddeviatie voor Xx_threshold <- mu_x + sigma_x # Drempelwaarde voor Xmu_z <-0# Gemiddelde voor Zsigma_z <-1# Standaarddeviatie voor Zz_threshold <- mu_z + sigma_z # Drempelwaarde voor Znr_sd <-3.5# Aantal standaarddeviaties om te tonen# Berekeningen op basis van parametersx_range <-c(mu_x - nr_sd * sigma_x, mu_x + nr_sd * sigma_x) # Bereik voor Xz_range <-c(mu_z - nr_sd * sigma_z, mu_z + nr_sd * sigma_z) # Bereik voor Zn_points <-50* nr_sd # Aantal datapunten# Domeinen voor X en Zx_values <-seq(x_range[1], x_range[2], length.out = n_points)z_values <-seq(z_range[1], z_range[2], length.out = n_points)# Bereken kansdichthedenx_data <-data.frame(x = x_values,y =dnorm(x_values, mean = mu_x, sd = sigma_x))z_data <-data.frame(x = z_values,y =dnorm(z_values, mean = mu_z, sd = sigma_z))# Gebied waar X > x_thresholdx_fill <-data.frame(x =seq(x_threshold, x_range[2], length.out =100),y =dnorm(seq(x_threshold, x_range[2], length.out =100), mean = mu_x, sd = sigma_x))# Gebied waar Z > z_thresholdz_fill <-data.frame(x =seq(z_threshold, z_range[2], length.out =100),y =dnorm(seq(z_threshold, z_range[2], length.out =100), mean = mu_z, sd = sigma_z))# Plot voor Xplot_x <-ggplot(x_data, aes(x = x, y = y)) +geom_line(linewidth =1, color = lijnkleur0) +geom_area(data = x_fill, aes(x = x, y = y),fill = opvulkleur1, alpha =0.5 ) +labs(x =expression(italic(X)),y ="Kansdichtheid" ) +theme_minimal()# Plot voor Zplot_z <-ggplot(z_data, aes(x = x, y = y)) +geom_line(linewidth =1, color = lijnkleur0) +geom_area(data = z_fill, aes(x = x, y = y),fill = opvulkleur1, alpha =0.5 ) +labs(x =expression(italic(Z)),y ="Kansdichtheid" ) +theme_minimal()# Combineer de twee plots met cowplotcombined_plot <-plot_grid( plot_x, plot_z, ncol =1, align ="v")# Voeg een verticale lijn toe over beide plotsfinal_plot <-ggdraw(combined_plot) +draw_line(x =c(0.675, 0.675), # Relatieve positie op de x-as (0-1 schaal)y =c(0.09, 1), # Relatieve positie op de y-as (0-1 schaal)color = lijnkleur1,size =1, linetype ="dashed" )# Toon de finale plotprint(final_plot)
Figuur 23.10: Kansen voor een normaal verdeelde variabele \(X\) hangen samen met kansen voor standaardnormaal verdeelde variabele \(Z\).
Stel nu dat we geïnteresseerd zijn in de kans dat \(X > 176\), dus \(\textrm{Pr}\!\left[X > 176\right]\). In de bovenste grafiek van Figuur 23.10 is dat de oppervlakte van het paars gekleurde gebied. Omdat de twee grafieken dezelfde vorm hebben, kunnen we exact hetzelfde oppervlak ook intekenen in de onderste grafiek; dat hebben we weer met paars gedaan. De paarse stippellijn laat zien dat de grenzen van de paarse gebieden in beide plots precies zijn uitgelijnd.
In de bovenste plot is het gemiddelde \(\mu_X = 170\) en de standaarddeviatie \(\sigma_{X} = 6\). De grens van het paarse gebied, 176 cm, is dus precies één standaarddeviatie boven het gemiddelde. In de onderste plot moet de grens dus ook getrokken worden op één standaarddeviatie boven het gemiddelde, en dat is \(Z = 1\). Hieruit kunnen we concluderen dat \[ \textrm{Pr}\!\left[X > 176\right] = \textrm{Pr}\!\left[Z > 1\right]. \]
Dit werkt in het algemeen: kansen voor iedere normaal verdeelde variabele \(X\) kunnen worden gerelateerd aan kansen voor de standaardnormaal verdeelde variabele \(Z\). De grens voor \(Z\) moet dan steeds gelijk zijn aan het aantal standaarddeviaties dat \(X\) van het gemiddelde afligt. Dat wil zeggen: \[ Z = \frac{X - \mu_X}{\sigma_{X}}. \tag{23.10}\] In het statistisch jargon zeggen we dat \(X\) in deze vergelijking wordt getransformeerd naar een standaardnormaal verdeelde variabele. Die transformatie wordt in het volgende hoofdstuk heel belangrijk.
Oefening 23.11 (Kansen voor de normale verdeling in R)
Met R kun je de kansen voor een normale verdeling opvragen met de functie pnorm(). Die functie geeft de cumulatieve verdeling van de normale verdeling. Neem bijvoorbeeld:
pnorm(0)
Dit commando geeft de kans op een waarneming kleiner dan 0 volgens de standaardnormale verdeling.
Maak eerst een schets van de standaardnormale verdeling. Bedenk wat de waarde van de cumulatieve verdelingsfunctie moet zijn bij \(Z = 0\), en voer dan het commando pnorm(0) uit om dat te controleren.
Maak weer een schets van de standaardnormale verdeling. Arceer het gedeelte \(Z < -1\). Wat is volgens de vuistregels de kans op een waarneming in dat interval? Bereken die kans vervolgens met de functie pnorm().
Bereken met pnorm() de kans dat \(Z > 0{,}5\). Een schets helpt. Hint: gebruik de complement-regel (Vergelijking 22.1).
Maak weer een schets van de standaardnormale verdeling. Arceer het gedeelte tussen \(Z = -1\) en \(Z = 1\). Wat is volgens de vuistregels de kans op een waarneming in dat interval? Bereken de kans vervolgens met de functie pnorm().
Hint: je hebt de functie twee keer nodig…
Hierboven gingen de vragen steeds over de standaardnormale verdeling, maar je kunt pnorm() ook gebruiken voor andere normale verdelingen. Je moet de functie dan vertellen welk gemiddelde en welke standaarddeviatie gebruikt moeten worden.
Bijvoorbeeld, als \(\mu = 170\) en \(\sigma = 6\) is dit de kans op een waarneming \(X < 176\):
pnorm(176, mean =170, sd =6)
[1] 0.8413447
De variabele IQ is ongeveer normaal verdeeld met gemiddelde \(\mu = 100\) en \(\sigma = 15\). Wat is de kans dat een willekeurige persoon een hoogbegaafd IQ heeft van meer dan 140?
23.10 De \(t\)-verdeling
Later in de cursus komen we ook een andere belangrijke verdeling tegen: de t-verdeling.
Ook de \(t\)-verdeling is niet één verdeling maar een familie van verdelingen. Deze verdelingen hebben een index: de eerste heet \(t_1\), de tweede \(t_2\), enzovoort. De index wordt het aantal vrijheidsgraden genoemd. Je kunt \(t_8\) dus ook omschrijven als de \(t\)-verdeling met 8 vrijheidsgraden, of met df = 8. (Hier staat df voor degrees of freedom.) Een variabele met een \(t\)-verdeling wordt vaak \(t\) genoemd.
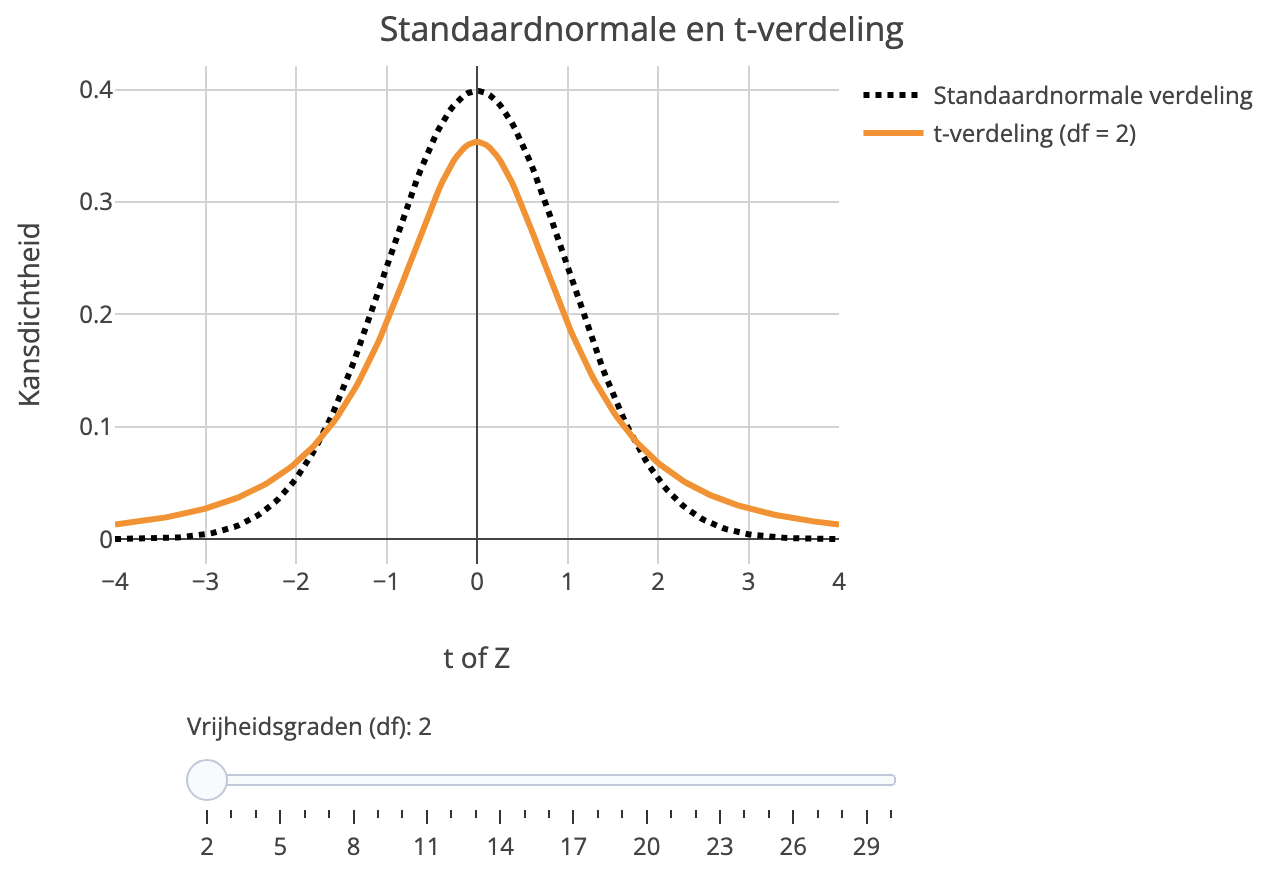
De \(t\)-verdelingen lijken behoorlijk op de standaardnormale verdeling. In Figuur 23.11 hieronder kun je de \(t\)-verdeling (oranje) vergelijken met de standaardnormale verdeling (zwart). Gebruik de slider om het aantal vrijheidsgraden te veranderen.
Vergelijking tussen verschillende \(t\)-verdelingen en de standaardnormale verdeling. Hoe groter het aantal vrijheidsgraden, hoe kleiner het verschil.
(interactieve versie online)
Figuur 23.11: Vergelijking tussen verschillende \(t\)-verdelingen en de standaardnormale verdeling. Hoe groter het aantal vrijheidsgraden, hoe kleiner het verschil.
Net als bij de standaardnormale verdeling is het gemiddelde altijd 0. Vergeleken met de standaardnormale verdeling heeft de \(t\)-verdeling wel een lagere piek en “dikkere staarten”. De spreiding van de \(t\)-verdeling is daardoor groter.2 Maar, het verschil tussen de \(t\)-verdeling en de standaardnormale verdeling wordt kleiner naarmate het aantal vrijheidsgraden groter wordt. Dat kun je in Figuur 23.11 duidelijk zien: bij \(\text{df} = 20\) zijn de \(t\)-verdeling en de standaardnormale verdeling op het oog al moeilijk te onderscheiden. In de limiet van \(\text{df}\rightarrow \infty\) convergeert de \(t\)-verdeling ook echt naar de standaardnormale verdeling.
Oefening 23.12 (Dijken)
Om te berekenen hoe hoog de zeedijken moeten zijn maken we gebruik van een model dat veronderstelt dat de waterstand bij vloed normaal verdeeld is.
Stel dat in werkelijkheid de verdeling meer lijkt op een \(t\)-verdeling. Welk effect heeft dat op onze risico-berekeningen?
(Je hoeft niets te berekenen, alleen te beredeneren.)
23.11 Kritieke waarden
Kritieke waarden van de standaardnormale verdeling
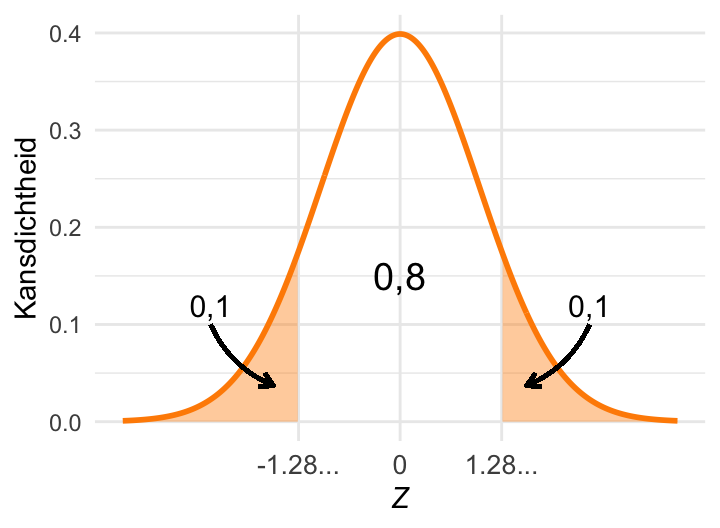
In Figuur 23.12 (a) is weer de standaardnormale verdeling weergegeven. In beide staarten van de verdeling is een gebied paars gekleurd. De oppervlakte van elk van deze gebieden is 0,1; samen representeren ze dus een kans van 0,2.
Om ervoor te zorgen dat die kans precies 0,2 is, is de grens van het rechtergebied ingesteld op (afgerond) 1,28 en de grens van het linkergebied op (afgerond) -1,28. De kans op een waarneming die extremer is (meer afwijkt van het gemiddelde) dan 1,28 is dus precies 0,2, en de kans op een waarneming die minder extreem is, is 1 - 0,2 = 0,8.
(a) De kritieke waarde van de standaardnormale verdeling \(Z_{0{,}2(2)} \approx 1{,}28\).
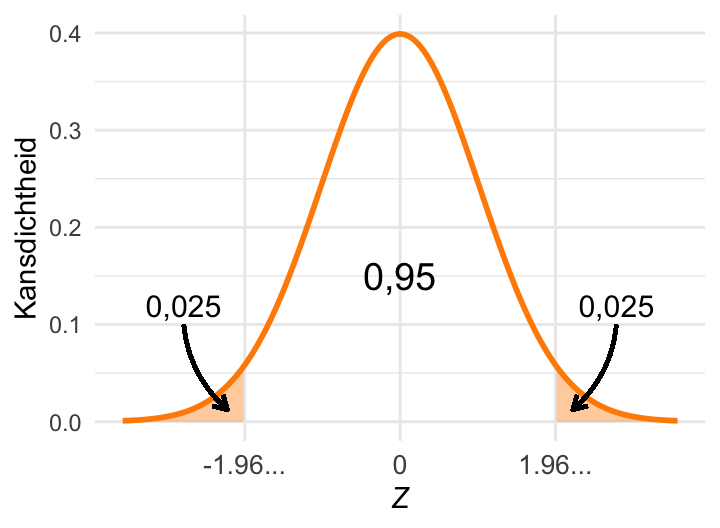
(b) De kritieke waarde van de standaardnormale verdeling \(Z_{0{,}05(2)} \approx 1{,}96\).
(c) De kritieke waarde van de \(t\)-verdeling \(t_{0{,}2(2)4} \approx 1{,}53\).
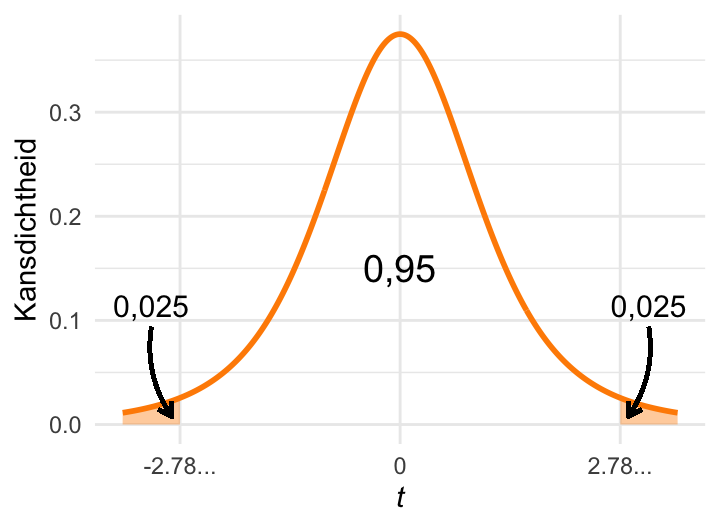
(d) De kritieke waarde van de \(t\)-verdeling \(t_{0{,}05(2)4} \approx 2{,}78\).
Figuur 23.12: Kritieke waarden van de standaardnormale verdeling en de \(t\)-verdeling.
De grenswaarde van het rechter gebied wordt een kritieke waarde (critical value) van de verdeling genoemd. In dit geval gaat het om de kritieke waarde die hoort bij een kans van 0,2 (voor beide paarse gebieden samen). Deze kritieke waarde wordt daarom genoteerd als \(Z_{0{,}2(2)}\). Hierin verwijst 0,2 naar de totale oppervlakte van de paarse gebieden, en de (2) geeft aan dat daarbij beide staarten worden meegeteld.
Op dezelfde manier is \(Z_{0{,}05(2)}\) de grenswaarde die hoort bij paarse gebieden met een totale oppervlakte van 0,05. Deze situatie is weergegeven in Figuur 23.12 (b). De kritieke waarde is nu \(Z_{0{,}05(2)} \approx 1{,}96\). Dat deze kritieke waarde dicht bij 2 ligt, had je kunnen inschatten. De tweede vuistregel uit Paragraaf 23.8.1 stelt dat bij een normale verdeling ietsje meer dan 95% van de kansmassa zich binnen 2 standaarddeviaties van het gemiddelde bevindt, en de overige 5% dus daarbuiten. Dan moet de kritieke waarde \(Z_{0{,}05(2)}\) dus erg dicht bij 2 liggen. Onthoud de waarde \(Z_{0{,}05(2)}=1{,}96\); deze kritieke waarde komt in de statistiek keer op keer terug.
Er bestaan kritieke waarden voor elke keuze van de totale oppervlakte van de paarse gebieden. Als we deze oppervlakte noteren met de Griekse letter \(\alpha\) (spreek uit als “alfa”), is er een kritieke waarde \(Z_{\alpha(2)}\) voor iedere waarde van \(\alpha\) tussen 0 en 1. Samengevat:
BelangrijkDefinitie: Kritieke waarden van de standaardnormale verdeling
De kritieke waarde \(Z_{\alpha(2)}\) is de grenswaarde zodat de kans op een waarneming extremer dan \(Z_{\alpha(2)}\) gelijk is aan \(\alpha\).
Je kunt dit schrijven als
\[\textrm{Pr}\!\left[Z < -Z_{\alpha(2)} \text{ of } Z > Z_{\alpha(2)}\right] = \alpha. \tag{23.11}\]
Binnen de grenzen ligt juist een kans \(1 - \alpha\):
\[\textrm{Pr}\!\left[-Z_{\alpha(2)} < Z < Z_{\alpha(2)}\right] = 1 - \alpha. \tag{23.12}\]
Je kunt de kritieke waarde die hoort bij een waarde van \(\alpha\) berekenen met de applet hieronder. Beweeg de slider tot de paarse gebieden de gewenste oppervlakte \(\alpha\) hebben, en lees de kritieke waarde vervolgens af.
Kritieke waarden van de \(t\)-verdeling
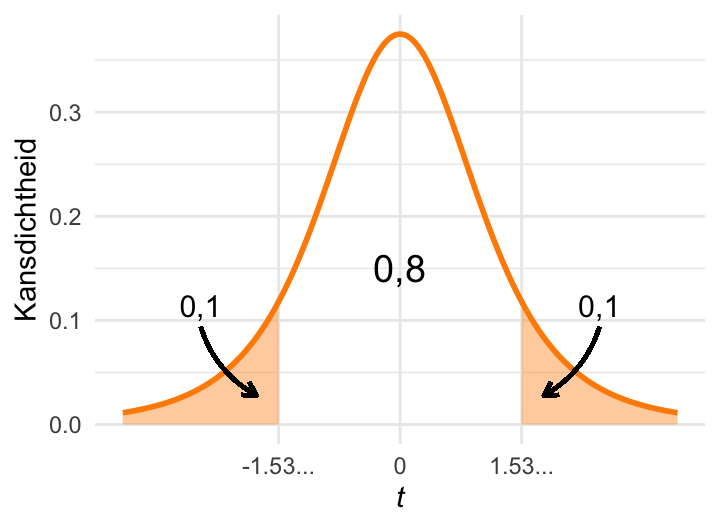
Kritieke waarden kunnen ook worden gedefinieerd voor \(t\)-verdelingen. Het grote verschil is dat de kritieke waarde die hoort bij een bepaalde kans \(\alpha\) nu ook afhangt van het aantal vrijheidsgraden (df) van de \(t\)-verdeling. In Figuur 23.12 (c) is de \(t\)-verdeling met \(\mathrm{df} = 4\) weergegeven. Net als in Figuur 23.12 (a) hebben de paarse gebieden in totaal een oppervlakte van 0,2. De grenzen van deze gebieden zijn de kritieke waarden voor de kans 0,2 en \(\mathrm{df} = 4\). We noteren dat als \(t_{0{,}2 (2) \mathrm{4}}\).
BelangrijkDefinitie: Kritieke waarden van de \(t\)-verdeling
De kritieke waarde \(t_{\alpha (2) \mathrm{df}}\) voor de \(t\)-verdeling met df vrijheidsgraden is de waarde waarvoor geldt:
\[\textrm{Pr}\!\left[t < -t_{\alpha (2) \mathrm{df}} \text{ of } t > t_{\alpha (2) \mathrm{df}}\right] = \alpha. \tag{23.13}\]
Binnen de grenzen ligt juist een kans \(1 - \alpha\):
Doordat de \(t\)-verdeling dikkere staarten heeft dan de standaardnormale verdeling (meer kansmassa in de staarten) zijn bij gelijke \(\alpha\) de kritieke waarden van de \(t\)-verdeling groter. Vergelijk bijvoorbeeld Figuur 23.12 (a) met Figuur 23.12 (c): \(Z_{0.2(2)}\approx 1{,}28\), terwijl \(t_{0{,}2 (2) \mathrm{4}} \approx 1.53\). Of vergelijk Figuur 23.12 (b) met Figuur 23.12 (d): \(Z_{0.05(2)}\approx 1{,}96\), terwijl \(t_{0{,}05 (2) \mathrm{4}} \approx 2.78\).
De applet uit de vorige sectie kan ook worden gebruikt om kritieke waarden van de \(t\)-verdeling te berekenen. Speel er eens mee!
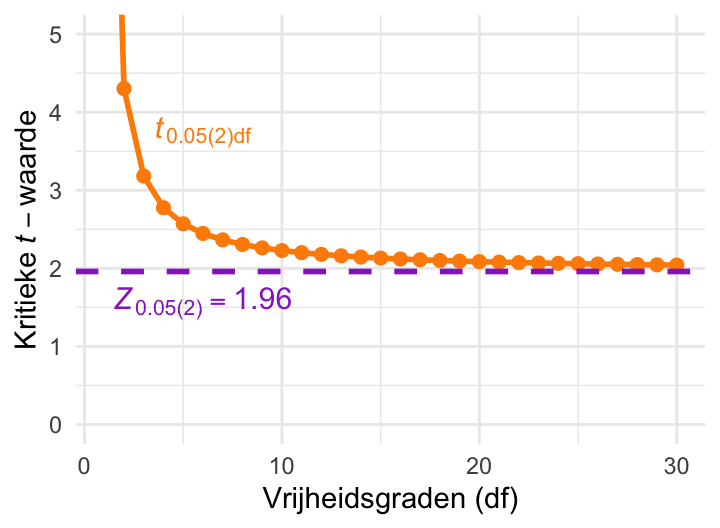
In Paragraaf 23.10 zagen we ook dat de \(t\)-verdeling naar de standaardnormale verdeling convergeert als het aantal vrijheidsgraden groot wordt. Dat betekent dat ook de kritieke waarden van de \(t\)-verdeling convergeren naar de kritieke waarden van de standaardnormale verdeling. Figuur 23.13 laat dit zien: \(t_{0{,}05(2)\mathrm{df}}\) convergeert naar \(Z_{0{,}05(2)}=1{,}96\) in de limiet van grote df.
Code
# Parametersalpha <-0.05# Significatieniveauvrijheidsgraden <-1:30# Aantal vrijheidsgradenkritieke_t <-qt(1- alpha /2, df = vrijheidsgraden) # Kritieke $t$-waardenkritieke_normaal <-qnorm(1- alpha /2)# Data voorbereidendata <-data.frame(df = vrijheidsgraden,kritieke_t = kritieke_t)# Plotggplot(data, aes(x = df, y = kritieke_t)) +geom_point(color = puntkleur1, size =2) +# Puntengeom_line(color = lijnkleur0, linewidth =1) +# Lijnengeom_hline(yintercept = kritieke_normaal, color = lijnkleur1,linetype ="dashed", linewidth =1 ) +annotate("text", x =6, y = kritieke_normaal -0.4, label =expression(italic(Z)[0.05*"("*2*")"] ==1.96), color = lijnkleur1,size =4 ) +annotate("text", x =6, y =3.75, label =expression(italic(t)[0.05*"("*2*")"*"df"]),color = accentkleur1,size =4 ) +coord_cartesian(ylim =c(0, 5)) +# Stel het bereik van de y-as inlabs(x ="Vrijheidsgraden (df)",y =expression(Kritieke~italic(t)-waarde),title =NULL ) +theme_minimal()
Figuur 23.13: Kritieke \(t\)-waarde bij \(\alpha = 0.05\) als functie van het aantal vrijheidsgraden df. Voor grote df convergeert de kritieke waarde naar de kritieke waarde van de standaardnormale verdeling, 1,96.
De kritieke waarden van de standaardnormale verdeling en de \(t\)-verdeling zullen een belangrijke rol spelen in Hoofdstuk 24 en Hoofdstuk 25.
Kritieke waarden bepalen met R
Om de kritieke waarden van een verdeling te bepalen zullen we in deze cursus gebruik maken van R.
Kijk nog eens naar Figuur 23.12 (a), waarin de kritieke waarde is geïllustreerd voor \(\alpha = 0{,}2\). De kritieke waarde is de grenswaarde van \(Z\) zodanig dat het gebied rechts ervan een oppervlakte heeft van \(\alpha/2 = 0{,}1\), en het hele gebied links ervan dus een oppervlak van \(1 - \alpha/2 = 0{,}9\). Dat betekent dat de kritieke waarde gelijk aan kwantiel 0,9, oftewel het 90e percentiel, van de standaardnormale verdeling. Die waarde kunnen we aan R vragen met de functie qnorm(). In de naam van die functie staat q voor quantile, en norm voor de normale verdeling. Het werkt zo:
qnorm(0.9)
[1] 1.281552
Het resultaat is precies de grenswaarde van (afgerond) 1,28 die je in Figuur 23.12 (a) aan de \(x\)-as ziet staan.
Voor iedere willekeurige waarde van alfa kun je het als volgt aanpakken:
alfa <-0.2qnorm(1- alfa/2)
[1] 1.281552
Oefening 23.13 (Kritieke waarden voor de normale verdeling.)
Bekijk Figuur 23.12 (a) nog eens. Dat is een illustratie voor de kritieke waarde bij \(\alpha = 0{,}2\).
Schets net zo’n plaatje, maar nu voor \(\alpha = 0{,}1\).
Gebruik qnorm() om de kritieke waarde uit te rekenen en geef die aan op de \(Z\)-as.
Beredeneer zonder te rekenen: is \(Z_{0{,}5(2)}\) groter of kleiner dan \(Z_{0{,}1(2)}\)?
Tip: Schetsen helpt!
Beredeneer: wat is \(Z_{1(2)}\)?
Figuur 23.12 (c) illustreert de kritieke waarde van de \(t\)-verdeling met 4 vrijheidsgraden, weer voor \(\alpha = 0,2\). Weer kunnen we deze kritieke waarde aan R vragen, nu met de functie met de voorspelbare naam qt(). Omdat de kritieke waarde afhangt van het aantal vrijheidsgraden zul je die aan de functie moeten meegeven:
alfa <-0.2qt(1- alfa/2, df =4)
[1] 1.533206
Hier komt precies de waarde van (afgerond) 1,53 uit die in de figuur is aangegeven.
Oefening 23.14 (Oefenen met kritieke waarden van de \(t\)-verdeling)
Bereken met R de kritieke waarde \(t_{0{,}05(2)2}\).
Is deze waarde kleiner of groter dan die van de normale verdeling bij dezelfde \(\alpha\)?
Waarom?
Bereken met R de kritieke waarde \(t_{0{,}05(2)100}\).
Is deze waarde kleiner of groter dan bij 2 vrijheidsgraden?
Waarom?
23.12 Andere kansverdelingen
Hierboven hebben we de normale verdeling en de \(t\)-verdeling besproken. In deze cursus hebben we geen tijd om andere verdelingen te bespreken, maar allerlei andere kansverdelingen komen in de statistiek ook vaak terug. In Figuur 23.14 geven we een paar voorbeelden. Bekijk ze even en lees de namen door; het is handig dat die in je achterhoofd zitten voor als je ze ergens tegenkomt.
Figuur 23.14: Verschillende kansverdelingen voor discrete en continue variabelen die vaak in de statistiek voorkomen. In deze cursus hebben we (helaas?) geen tijd om deze kansverdelingen te bestuderen.
23.13 Samenvatting
Kansverdelingen
De kansverdeling van een kansvariabele is de manier waarop de kans over verschillende uitkomsten verspreid is.
Kansverdeling voor discrete variabelen
De kansverdeling kan worden weergegeven als een soort histogram dat voor iedere mogelijke uitkomst met een staaf de kans aangeeft.
Kansverdelingen van continue variabelen
Continue variabele hebben oneindig veel mogelijke uitkomsten, ieder met kans 0.
Daarom heeft het alleen zin om het te hebben over de kans op een uitkomst in een bepaald interval.
De kansverdeling kan nu worden weergegeven als een lijnplot die voor iedere mogelijke uitkomst de kansdichtheid weergeeft.
De kans op een waarneming in het interval \((a,b)\) is de oppervlakte onder de curve van de kansdichtheid in het interval \((a, b)\).
Cumulatieve kansverdeling
De cumulatieve kansverdeling is een functie \(F_X(x)\) die voor elke uitkomst \(x\) van kansvariabele \(X\) aangeeft wat de kans is op een waarneming kleiner of gelijk aan \(x\):
\[F_X(x) = \textrm{Pr}\!\left[X\leq x\right].\]
Maten voor ligging en spreiding
Maten voor ligging van een kansverdeling:
De modus: de plek van de piek van de verdeling; de uitkomst met de grootste kans of kansdichtheid.
De mediaan: de kans op een waarneming kleiner of gelijk aan de mediaan is 0,5.
Het gemiddelde of de verwachtingswaarde, \(\mathbb{E}\!\left[X\right]\) of \(\mu_X\): Bij discrete variabelen het gemiddelde van alle uitkomsten, gewogen naar hun kans:
Bij continue variabelen, de integraal over alle uitkomsten gewogen naar hun kansdichtheid (Vergelijking 23.3).
Maten voor de spreiding van een kansverdeling
De variantie, \(\mathrm{Var}\!\left(X\right)\) of \(\sigma_{X}^2\): De verwachtingswaarde van de gekwadrateerde afwijkingen van het gemiddelde.
Bij discrete variabelen: \[\mathrm{Var}\!\left(X\right) = \sum_x \textrm{Pr}\!\left[X = x\right] \left( x - \mu_X \right)^2.\]
Bij continue variabelen verandert de sommatie in een integraal.
De standaarddeviatie, \(\sigma_{X}\): Wortel van de variantie. \[\sigma_{X} = \sqrt{\mathrm{Var}\!\left(X\right)}.\]
Speciale kansverdelingen
Normale verdeling
Andere namen: normaalverdeling, Gaussische verdeling, Gausscurve.
Klokvormig
Twee parameters: gemiddelde \(\mu\) en standaarddeviatie \(\sigma\).
Vuistregels:
De kans op een waarneming binnen afstand \(\sigma\) van het gemiddelde is iets groter dan \(\frac{2}{3}\).
De kans op een waarneming binnen afstand \(2\sigma\) van het gemiddelde is ietsje groter dan 0,95.
Standaardnormale verdeling: de normale verdeling met \(\mu = 0\) en \(\sigma = 1\).
Transformeren: De normaal verdeelde variabele \(X\) wordt een standaardnormaal verdeelde variabele \(Z\) als je het gemiddelde eraf trekt en dan door de standaarddeviatie deelt:
\[ Z = \frac{X - \mu_X}{\sigma_{X}}.\]
Centrale Limietstelling: kansvariabelen die de optelsom zijn van veel andere kansvariabelen zijn bij benadering normaal verdeeld.
\(t\)-verdeling
Familie van verdelingen met als index het aantal vrijheidsgraden df.
Gemiddelde is altijd 0.
Lagere piek en dikkere “staarten” dan de standaardnormale verdeling; dus grotere variantie.
Convergeert naar de standaardnormale verdeling voor \(\text{df}\rightarrow \infty\).
Kritieke waarden
De kritieke waarde \(Z_{\alpha(2)}\) voor de normale verdeling is de waarde zodat de kans op een waarneming die extremer is dan \(Z_{\alpha(2)}\) precies \(\alpha\) is.
De kritieke waarde \(t_{\alpha (2) \mathrm{df}}\) voor de \(t\)-verdeling met df vrijheidsgraden is de waarde zodat de kans op een waarneming \(t\) die extremer is dan \(t_{\alpha (2) \mathrm{df}}\) precies \(\alpha\) is.
Een functie die aangeeft wat de kans is dat een waarneming kleiner of gelijk is aan een bepaalde waarde.
Gaussische verdeling
Gaussian distribution
Synoniem voor normale verdeling, ook wel Gausscurve.
kansdichtheid
probability density
Functie die voor een continue kansvariabele aangeeft hoe de kans over de mogelijke uitkomsten verdeeld is.
kansverdeling
probability distribution
De manier waarop kans over de mogelijke uitkomsten van een kansproces zijn verdeeld.
kritieke waarde
critical value
Voor een kansverdeling, een grenswaarde zodanig dat de kans op een extremere waarde gelijk is aan een gegeven kans.
normale verdeling
normal distribution
Een specifieke klokvormige en symmetrische kansverdeling met twee parameters: gemiddelde en standaarddeviatie.
standaardnormale verdeling
standard normal distribution
Een normale verdeling met verwachtingswaarde 0 en standaarddeviatie 1.
t-verdeling
t distribution
Een familie klokvormige kansverdelingen met als parameter het aantal vrijheidsgraden.
transformeren
to transform
Het omzetten van een kansvariabele in een andere variabele door middel van een functie \(f(X)\).
verwachtingswaarde
expected value
De gemiddelde waarde van een kansverdeling.
vrijheidsgraad
degree of freedom
In deze context: parameter van de \(t\)-verdeling.
Voor wie dat interessant vindt: In de wiskunde bestaan er verschillende versies van het begrip oneindig. Van de natuurlijke getallen \(\{0, 1, 2, \ldots\}\), bestaan er aftelbaar oneindig veel. Van de reële getallen bestaan er overaftelbaar oneindig veel.
Een verzameling is onaftelbaar als het niet mogelijk is om de elementen in die verzameling ieder een eigen nummer te geven in een oneindige lijst. Als je dat probeert, kom je erachter dat iedere oneindige lijst met reële getallen incompleet is. Hoewel er oneindig veel natuurlijke getallen zijn, zijn er alsnog oneindig veel meer reële getallen dan natuurlijke getallen.↩︎
De variantie van de \(t\)-verdeling hangt af van het aantal vrijheidsgraden en is gelijk aan \(\mathrm{df}/(\mathrm{df} - 2)\). In de limiet waarbij het aantal vrijheidsgraden naar oneindig gaat, convergeert dit naar 1. Dat moet ook, want in die limiet convergeert de \(t\)-verdeling naar de standaardnormale verdeling, en die heeft variantie \(\sigma^2 = 1\).↩︎